(6 hrs avg)
Seems like while first node works, the second one stays idle. Then they changes. While node is ‘idle’ last contact counter grows. Sometimes one node goes offline.
Why this happens? I know, that storj reccomends 1 thread per 1 node, but some topics near here tells, that if system and cpu load below 80% you can run additional nodes. Does my experiment shows that it doesn’t work?
like a pro lol you seem to be very integrated into the storagenode code these days…
enjoy and make good use of it while it lasts, such comprehension of complex systems is a rarity and a fleeting one at best.
That is my super power. Other people are great in developing stuff. You don’t want to see my code…
I noticed that I have one unique skill. You can give me a bunch of design documents and I will tell you what kind of issues you might get later on. I can also write down a bunch of test ideas to proof it. I don’t need to dedicate additional time for that. I just read it once and for some reason I can keep it in mind very easy. For some reason this trick doesn’t work for other situations in my life. I am always search for my phone and can’t remember where I put it down 10 minutes ago…
Now let me explain the background for this topic. The nodeID is the primary key in the database. If 2 nodes are using the same nodeID that means the satellite will only communicate with the node that checked in last. The satellite will send all upload, download and audit request to that one node. The second node will be offline with no communication in the logs. After some time the second node might contact the satellite to update the database entry with its port. Now the first node will be offline and the second node gets all the traffic. Inclusive audit request for data that the other node is holding. At the beginning of the storage node lifetime that is ok. Just turn off one of the node. Maybe copy over all the pieces from the second node. I believe that will fix the audit problem. Even if it doesn’t fix it you might be lucky to get additional pieces to compensate a few audit failures.
so you are saying its technically not super difficult to merge storagenodes?
because that is a feature i think many SNO’s would be interested in…
well your logical deduction is sound logical deduction doesn’t help remember phones tho… but one can keep it in designated spots heheHelps the deduction
logical deduction makes one able to predict the future
more to be learned from keeping it i guess… so long as it’s not DQ on any satellites and even then just for testing it might be irrelevant… ofc it sort of depends on how big the node is… but low audit score shouldn’t hurt anything i’m can think of… not long term anyways…
So… Node will be 1 month old soon. It’s size is 7 tb and audit score keeps between 90 and 100%. On 2 satellites it is fully vetted, but ingress still at 2 other not fully vetted nodes level (both have 100% audits and max 54 vetting)
How long will audit score be like that? Months? Years?
Hardvare want to die, but still according to 2 other nodes all working fine
excuse me from going totally off topic are you saying you have 7tb stored on a 1 month old node, because that sounds weird.
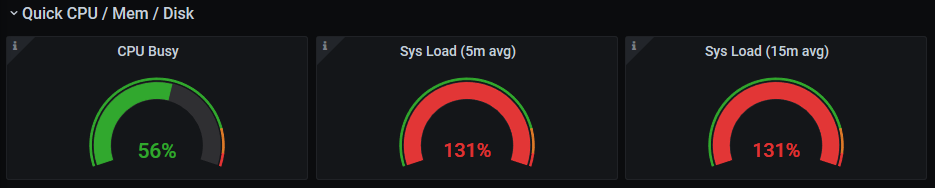
your audit scores shouldn’t change, it should stay consistent at the same number, that they drop at times is a sign something is wrong… and not saying that it is, but it could be related to processing, if you avg is 56% then i cannot imaging it keeping up at all times…
but really one would need to investigate your logs to figure out what has happened… or what is happening.
if you aren’t exporting your logs to permanent records then you should start, because to figure this out might require some log files to work with.
i’ve never seen my audit scores at anything else than 100%
the uptime score is also kinda odd… i mean if audit score is *100 shouldn’t uptime score be that also… but ill assume thats just not working or whatever…
the vetting takes different time on different satellites as it is dependent on traffic.
your audit scores look very worrying, ill try to reduce cpu time on my newest node… see if i can make it suffer from the same thing.
you should consider yourself lucky that the audit scores actually flux and not straight up drop, because then your node would have been DQ long ago
I can assume that you run 3 nodes. In the multi node setup the traffic is shared between all nodes behind the same /24 subnet of public IPs.
The vetting usually takes at least a month for the one node. In case of multi setup the vetting could be in the same times longer as a number of nodes behind the same /24 subnet of public IPs
If you mean how long it would take to went through vetting - in your case it could be 3 months.
If you mean the fluctuating audit score - then it’s not normal. This is mean that your node keep failing audits for some reason - either because unresponsive (audit considered as failed, if node answer on audit request but cannot provide a few kb of the piece for 5 minutes and repeats the same for the same piece three more times) or because it’s lost an access to the pieces - they either unreadable, or does not exists or it doesn’t have enough rights to read it.
I would like to ask you to check your disk for errors, especially if you see in logs the “file not found” messages.
Perhaps it’s not wise to run two nodes on the one-core CPU. As recommended in the Step 1. Understand Prerequisites - Storj Docs each node should have at least a one CPU core to work normally.
The fluctuating audit score I wouldn’t call normal work.
Let’s make it clear. I’m not new to storj, i’m holding a node since v2. There is no question about node vetting, this process is clear and easy to understand. Returning to start of the topic i’ve started second node with same id as first, so the reason of low audit score is killing second node with data deletion (Not hudge ammount, but noticeable), not drives errors or something else. I’m shure system doing well, cause 2 other nodes (out of 3) are totally fine.
Uptime score is broken on this dashboard and i dunno when author will fix it.
Also, hight system load caused by grafana + prometheus + exporter software, not storj.
The real question was how long need node to detect all data that corrupted and fix it? Or i’l continue getting bad audits and i’ts better to drop this node and reuse storage with new one? I know that while node audist score is above 60% there nothing to fear, but im shure that’s affects ingress traffic.
This node is located near mine, but on other subnet, physically located in other place in my city. While my node getting 2,4-5 Mbps, this getting below 1Mbps. Vetting passed on 2 main satellites, now providing most traffic, and storj exporter provides total statistics on all nodes i host. So, i can tell that each node still getting 25% of avaliable traffic, like they all are unvetted.
Maby i tell wrong, 7TB is the total size of avaliable disk space for this node. Current used is about 80GB
the node will never fix corrupted data. If you too much of your data is corrupt, your node will get DQed eventually. if it has only 80GB, I’d start a new one and make sure the data doesn’t get corrupted. Why did it get corrupted?
When I’ve started second node it accidentally started with the first node id. So it got some first node data, then when i noticed this error i deleted second node with all data it got. So satellite think there is that data on node, but node doesn’t have it.
Even if satellite tell to delete it? That should not be real data, cause it happened when node was less than week old. Also, doesn’t satellite tag this pieces as corrupted and use repair from other nodes to get this piece? If piece tagged as corrupted satellite should never ask for it again, so when all corrupted pieces tagged score shoul grow up? Or it works in different way?
Node was corrupting data less then half a day, and half of the data stored correctly, so, if average ingress was 250kbps, than there was stored 375kb. Half of them stored correctly, so there are only 187,5 KB corrupted. According to all node stored data (90+ GB) it is a drop in the sea, but it continue failing audits. Strange.
yeah it’s something with that if you got two nodes on the same identity, it will switch between which of the nodes are registered as online, and thus the data will be split between then…
the correct way to “recover” from this is to put the data from the “new identity sharing” node into the data of the “original identity” node, this will help reduce the failed audits…
your node is lacking some data, seems like not enough to kill it, but it may die… if it doesn’t then eventually it should run out of files that you don’t have and audit score should remain stable from that point…
can’t say i really understand the mechanics of it, but personally i might just wait it out see if audit scores doesn’t improve over time, but it can be a long long time, thus if you don’t want to be confused by the unstable audit score, then if node is still very small one could just get rid of it… ofc then you are back to square one with that node…
so really it comes down to if you don’t mind that you will have a hard time seeing problems on the node in question for a time, maybe a long time…
or if you want to get have a 100% audit score so you can see if it’s running correctly.
or if you got the data from the … shadow node… second node on the same id, because then you may be able to fix it…
i by no means have even a partial understanding on how all of this works, but that’s how i see it…
nor am i a financial advisor lol there thats out.