all this 13 nodes treeted as one node, may be someone droped chia and started to deal with storj, thats all. Loot of chia big playrs have lot of hdds
The problem is that if there are 2 operators in one /24 subnet, but 1 has 13 nodes on one IP address, and the second has 1 node on 1 IP address, then the network considers all nodes equal, and the first gets 13/14 traffic, and the second 1/14.
Accordingly, if the first operator has a breakdown of equipment, the network loses 13 nodes at once, and may turn out to be unreliable.
network cant be unreliable, only node.
Well, as if it’s a little wrong, you must agree - it’s one thing when traffic is distributed equally between IP ADDRESSES within one / 24 subnet, and it’s quite another thing when it is distributed equally between all nodes in one /24 subnet.
What prevents me from joining any subnet, creating 100 nodes there on one free address and pulling over all incoming traffic?
I don’t think that would be efficient.
I wonder if these are coming out of a VPN. That would explain the clumping of some nodes together in the same subnet and not others.
Why you don’t think that would be efficient?
Someone found how to register 2000 nodes in less than a hour
Someone started them.
If one node consumes approx. 300 Mb of RAM it is almost 600GB of memory. Very expensive hardware, my friend!
Someone put their efforts into doing all this automatically, by bot or via ansible. And for sure, for the sake of such a thing, there is a fault-tolerant server with an Internet channel reservation. It’s not just a miner from a data center, it’s a whole breach in the system, and someone is trying to use it.
And if each of the 13 nodes at the ip address xxx.xxx.xxx.2 has the same distribution in the network as one node at the ip address xxx.xxx.xxx.3, then here the entire range / 24 belongs to one person. Something has to be done about it.
I would suggest when counting neighbors to divide traffic not to all nodes in one / 24 subnet, but to all addresses in /24 subnet. Because one IP address is 1 computer or server, if there are 13 nodes behind 1 IP address, then there cannot be 13 mans with 13 servers. And the distribution by IP addresses looks more honest and understandable, it corresponds to the goals and objectives of the network and the interests of operators.
It’s not efficient because all those nodes get as much data as one node on a separate subnet. Since margins here are low, operating so many nodes in a single subnet is not a good use of resources. It only really makes sense if the other nodes are full and arre providing egress. And one node is accepting ingress.
Your concern that one person may control an entire subnet does not endanger the network at all. It just limits other node’s ability to get ingress if they are on the same subnet. But that is by design to prevent consolidation of data.
1 Like
What tool is this?
I find it also curious that these 2000 nodes have not been reflected by storjnet.info. It reports both the official number of nodes (which got higher at the beginning of January), but also, I guess, some empirical number (which did not). Before January these two modes of measurement were more or less tracking each other, but not anymore.
No, you don’t understand a little what I’m talking about. Here is an example - my personal IP address, my node is still here alone, but the closest neighboring IP to me is at the other end of the city. xxx.251 in the south - xxx.252 - in the north. If another person comes and puts a second node, it will be tolerable, but if such a spammer comes and puts 100 nodes on one IP address, my incoming traffic will decrease 100 times, and it will not make sense for me to keep a node.
Yes, the margin is small, and IP addresses cost money - it’s a fair game: if you want to win, buy an IP address or install a server in a data center.
But if you install 100 nodes on 1 IP address, it’s not fair to me, because I’m out of the game, and the network thinks it has 100 nodes left, but in fact it’s 1 node with 1 IP address, which is physically in 1 place, connected to 1 outlet, rather in total, this is 1 person, 1 internet provider, 1 motherboard and 1 RAID controller. It may fail at once.
I found several subnets where dozens of Storj nodes are hosted on 1 IP address. I can give you their IP addresses. And it would already be clear that if this continues, and if all nodes within 1 IP address have equal rights with nodes on other IP addresses in the common /24 segment, then sooner or later the network will be spammed.
Why wouldn’t someone run 2 nodes in the same /24 segment? Because incoming traffic is divided in half. OK, we will bypass this restriction by launching 100 nodes, and we will receive all incoming traffic on them, and let the other operator close its node… Is this normal?
Yeah, I understand that this scenario isn’t “fair” to the node owner. But you could run a hundred nodes as well and strip the spammer from making any money… But you won’t because the margins are too small to bother. It would make more sense to put each node behind a virtual server or VPN so that they are all distributed on separate subnets.
The single actor taking over a subnet is only receiving a small share of data regardless of how many nodes he runs under that subnet. So the network is not at risk even if that subnet goes offline. We have done studies on entire countries, regions and large network blocks going down and data is still secure.
I understand that it would be nice if node operators could have data spread more evenly. Various ideas have pros and cons to the overall health of the network. Things are fluid, it may change at some point if it makes sense for the health of the network to do so.
2 Likes
The battle of 100 nodes vs 1 node would make sense if all nodes are started in the same time, or the 1 node is not vetted yet. If it’s vetted, no danger. Those 100 nodes will finish vetting in 100 months; untill then, they just take 5% of ingress.
4 Likes
The best explanation is that some guy didn’t read the docs carrefuly, and soon he will realise the mistake.
4 Likes
Well, this is not really true.
It was true in the past and I also experienced that until the vetting was not fully done, the new node do not receive the same amount of ingress like the old node on the same subnet. But not any more.
Let me give you an example of my own 3 nodes with Ingress graph for each:
-
node. About 10 month old. Due to the recent deletions it had enough free space to take ingress in January (avg disk space value is inaccurate due to version 1.70.2, but the graph is ok):
-
node. Started around late sept/early oct. Fully vetted, as you can see on the graph, the used space is continously increasing:
-
node. Started on january 2nd. Brand new:

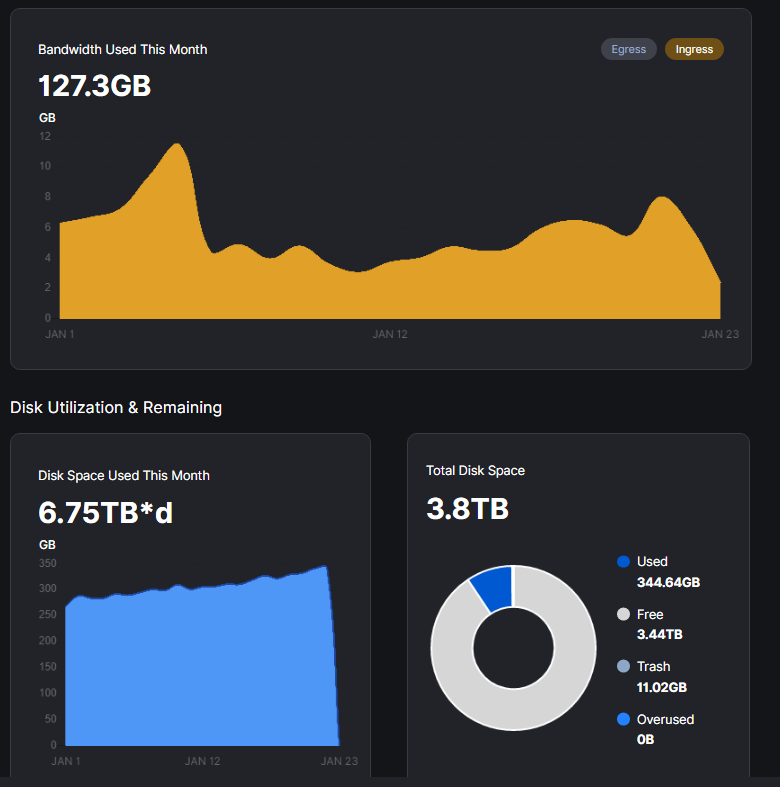
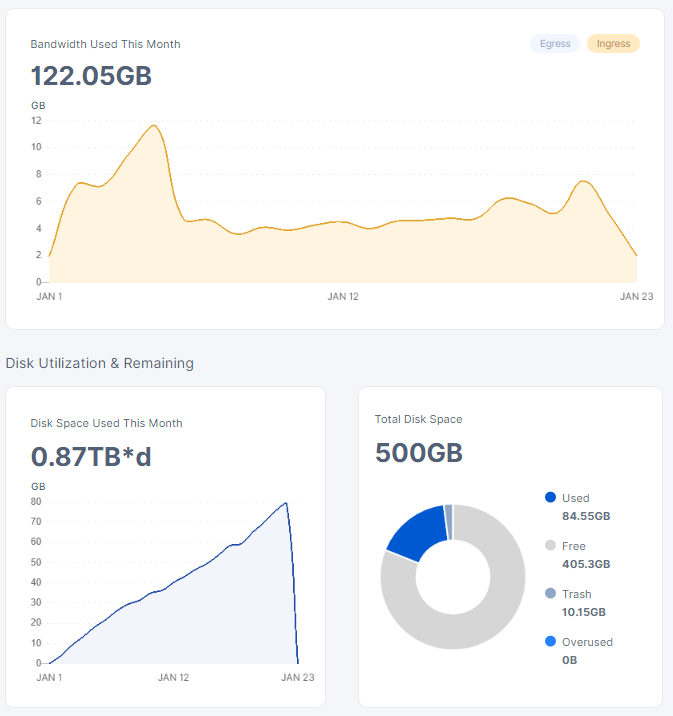
All of these nodes are behind the very same IP, but on different hardware/HDD. I have total 6 nodes, including this 3.
So, based on my experience if you are alone on your subnet you receive 100/100 of the ingress of the subnet. If someone is starting up 100 brand new node in your subnet, you will receive 1/100 of the ingress since that.
Maybe, there is one exception in the system that explains my situation: When there is a vetted node behind the IP, then STORJ system accept any new node behind the same IP as vetted from day 1.