Yeah that is a fair point, was doing a bit of math on if the regular avg drive latency could have something to do with it, in some cases…
with a regular 7200rpm drive the avg latency is 4.17ms so basically, near zero or max 9.4 which means 1/100th of a sec and thus 1/100th of bandwidth.
and if we assume i had ns rather than ms, then with my 400mbit connection would be able to move 480kb and then each file is split into 91 pieces… but for ease of math lets call it an even 100.
so any file less 48mb would be uploaded before the other guy could even access it…
in theory… i think i might need a better l2 ARC xD
ofc on avg it would be only half that size so 24mb with avg 7200rpm seek time.
l2arc only helps with downloads
for uploads you’d need a ZIL
But yeah… one of my nodes is on my main zfs drive and there was not much difference despite the ssd cache for read/write. but it is full now so I can’t compare since 3 months.
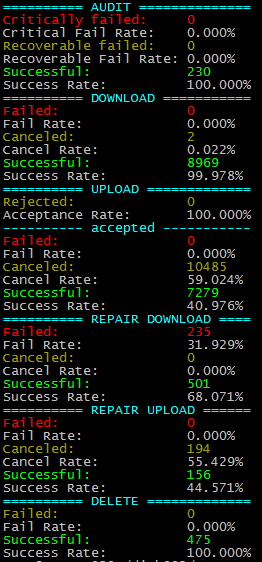
My upload successrate is 38% and my ping times are worse than yours:
kevin@droidserver:~$ ping 95.217.161.205 -c 5
PING 95.217.161.205 (95.217.161.205) 56(84) bytes of data.
64 bytes from 95.217.161.205: icmp_seq=1 ttl=50 time=111 ms
64 bytes from 95.217.161.205: icmp_seq=2 ttl=50 time=55.2 ms
64 bytes from 95.217.161.205: icmp_seq=3 ttl=50 time=70.1 ms
64 bytes from 95.217.161.205: icmp_seq=4 ttl=50 time=98.6 ms
64 bytes from 95.217.161.205: icmp_seq=5 ttl=50 time=337 ms
Your gear should win every damn time…
now even your ping is better than mine XD
PING 95.217.161.205 (95.217.161.205) 56(84) bytes of data.
64 bytes from 95.217.161.205: icmp_seq=1 ttl=46 time=34.4 ms
64 bytes from 95.217.161.205: icmp_seq=2 ttl=46 time=33.10 ms
64 bytes from 95.217.161.205: icmp_seq=3 ttl=46 time=33.7 ms
64 bytes from 95.217.161.205: icmp_seq=4 ttl=46 time=37.4 ms
64 bytes from 95.217.161.205: icmp_seq=5 ttl=46 time=34.3 ms
i do have a ZIL, i don’t think zfs will allow me to run a L2ARC without it…
or i mistakenly did so, at first but then it didn’t work, but i duno… not very well versed in zfs.
a full cache is a good thing… it means your system is ready to deliver the most recently accessed data…
Super weird calculation there if you take into account disk read latency but completely skip over the internet latency between uplink and storagenode. The 4ms you mentioned is pretty insignificant compared to latency introduced by the internet connection.
yeah theory doesn’t always work in the real world heh, tho everybody would have internet latency… even if its different from place to place and isp to isp… many factors to take into account was just doing a bit of a back of the envelops math to see if the numbers was really relevant or not, in regard to upload speed to user file sizes…
Im running 12 nodes (12x8TB HDD) on ubuntu VM. All of it is just ext4 partitioned drives with some of them connected over USB3 port (external drives). Internal drives have much better performance but no difference for Storj. I do have some system level optimizations that I hope is helping with success rate.
I suppose next step would be evaluation according to latency to the different satellites, one option could be bad latency to many of the satellites, against node located with low latency many sats.
the battle for next time lol… anyone got a link to a nice script for latency
Only latency that matters is one from customer to nodes. Latency to satellite is not important at all. Since customer is likely to chose satellite closer to them, there will be some correlation between the satellite latency and success rate (just because customer is choosing ones closer to themselves.)