tho i bet it would be faster i doubt it would ever hit theoretical speeds, there are a lot of compression and such also affecting transfer speeds…
if its raw easily compressible data it might transfer very quickly… seemingly faster than your bandwidth could do, because it’s compressed for transit often.
while other file may be highly condensed / compressed data which then cannot be compressed and so … well good compression is like 10x and 2-3x live so can change a lot… not sure how good a bus compression is…
never the less… it would have been much faster as one file… i think… i sure do plan to fine out… i will be setting up a 3rd node anyways… so why not do tests like this… then ill have a node stored on a dual raidz1 pool (my main node), 1 stored on a mirror only pool to estimate performance gains against the raidz1 and then the last one for now will be a one file vm disk of some sorts.
that will give me so nice data points in the next year as they grow and ill need to migrate them also.
Node’s data are encrypted - so I wouldn’t count on compression effectiveness probably just more usage of bus processor that tries to compress it during the transfer
I found one idea that might be interesting but don’t know yet how to set it up on one computer.
It is used to send many small files over the net without chocking it because of the metadata.
This method uses setting a tar/zip software listening for a stream of data (with no compression set up) and sending it to second computer to another tar/zip software that also is listening for a stream then it it unpacks the stream and writes files on new drive.
Wondering if this could be any useful with such amount of files and size of the node.
yeah there are many reasons storagenodes are tough to migrate… like encryption today tries to minic random data without a pattern which is the adverse to what compression is…
one can do something like that with zfs snapshots i think… not sure it would be efficient on one computer… because eventually it would have to be “uncompressed / unpacked” again.
and the limitation is usually iops on the writing media in most cases, so even if you could send it as one large chunk, then you would still have to write each file, which is the slowest part. because it’s mechanical-
sure the reads are mechanical to, but reads are generally always faster, and the bus basically have no iops limitation… not compared to anything related to hdd’s anyways… the bus will have thousands of times more iops it can handle compared to a hdd.
when sending over the internet the computation on each side is higher than on the hardware inbetween… because each step essentially have to deal with all the bits and pieces…
just like when you try to copy 200mb that has 1.2mil files… it will take hours and hours usually on hdd’s
copying a zfs snapshot might be faster. and you can even copy a single file if you use zfs snapshots.
other than that it might get difficult to transfer a single virtual filesystem.
Well you shouldn’t. SNOs make decent money on their hardware now. Which means the base of SNOs will keep growing until that stops. It’s not unreasonable for that growth to currently outpace customer demand and I don’t expect that to change any time soon. Expectations of new customers should always be weighed against expectations of SNO growth. I don’t expect things to get much better for SNOs because of this.
Can I congratulate you on your 100th migration yet?
i cannot even remember how many i’ve done by now… 5 maybe 4 the last one lasted a couple of months so that’s an improvement…
done with the first copy… now i just need to somehow put it back… but might end up putting the node on a 4 drive raidz1 and then add the 2nd 4 drive raidz1 after the copy… so thats going to be nice and totally unbalanced… but i suppose with some months and deletions it should slowly start to balance out…
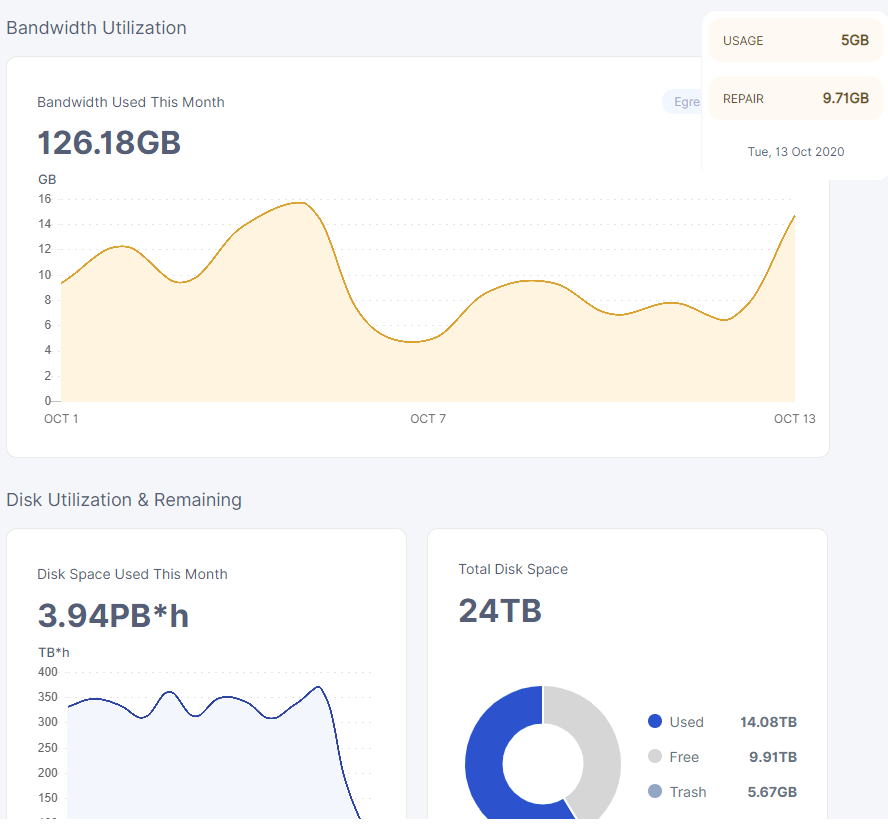
They changed the minimum allowed version from 1.9.0 to 1.14.7 so I guess the repair traffic comes from the nodes that are still below 1.14.7 and therefore offline and their files considered lost.
i would have expected more ingress if that was the case… but ofc there may be a ton more near empty new nodes out there taking up major parts of the shares…
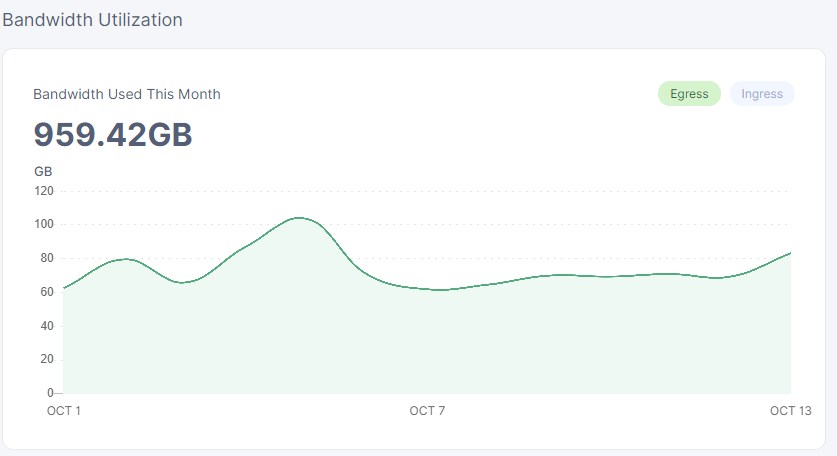
egress have been pretty decent for a while, … like what 2 months now
my egress hit an avg of nearly 2MB/s at the 20th of August
else i have to go back to the 16th of july since it was down below 1MB/s and the 9th it was 465k/s avg
so been a pretty decent run… would be nice to get some serious ingress soon…
my migration seems to be running good after i added a slog device… might be done in a few days only… so thats a win… it will be balanced as shit on a hill… but atleast ill get 20tb free capacity for the main node… and then a mirror pool to test… if i can figure out what to call it…
been thinking of call it chi … can’t remember if thats how its spelled most likely not… but close enough for modern terms… the chinese emperor that made a mercury lake constructed in his tomb…
so a mirror pool is a mercury lake… fast, stable, mirror and pool like
naming things is so hard, apperently its spelled Qin… but it’s where the Chi in china comes from… megalomania much … lol
alexey talked about the other day that, if people are below the minimal version they won’t get payout… not idea about how it all works tho…
the soft reminder or whatever little skunk called it, is at v 1.13.3 now… which is why v1.12.3 nodes and below gets no ingress…
haven’t really dug into what alexey was talking about… but how i understood it was that if you was running like 1.9. whatever or lower now then you wouldn’t get payouts… or something like that…
but don’t quote me on that… i don’t plan on getting that far behind, so i couldn’t really care less…
not getting paid and going offline could very well be the same thing…
but putting nodes offline before taking the data on them would be a bad plan… after all repair costs.
yeah right i forgot about that… they updated to 1.14.3 with some minor changes i think and then accidentally pushed another updated without changes to 1.14.7 by mistake, and now thats just the new version number
Yep I confused minimal version and minimum suggested version, my bad.
But you’re right, in theory we should see more ingress as well because those nodes went offline.
Also storjnet.info is offline, I wanted to check if it showed a substantial decrease in the number of online nodes or something but the page gives me a weird error…
i don’t think any of us have enough information to conclude that… but maybe
also we have to consider there is test data in all of it also… so we really don’t have any clue about whats going on from looking at the ingress and egress
ingress going up and up… wonder if we are finally going to actually get some ingress then… would be funny that the numbers started rising sharply from the 13th… because that would make it the exact 3 month mark from when my egress rose sharply…
ofc seeing it highly accurately isn’t really possible on the proxmox yearly avg graph
but it’s pretty clear what its saying, and the jump is quite visible
I went through the dashboard and it looks like europe-north and saltlake are responsible for most of the repair ingress on my node but didn’t upload much new data.
However ingress usage did triple for asie-east, us-central and europe-west, those are customer only satellites right ?
does sound familiar yes, i think some satellites are dedicated to test data… like saltlake… not sure which others there are…
asian is a huge market… if they suddenly thought tardigrade was great then it could give a ton of traffic from one day to the next… tho it exactly 3 months since egress spiked… would be weird if it changed today and wasn’t a test… ofc it could be a enterprise test not a storj test… we cannot really know stuff like that…
people like those building the 1 sq mile telescope will produce more data than the entire internet has today in a few years every year… so they are looking towards how to store it.
but who knows… sure does seem test related if it shifts from one continent to another on the exact day 3 months later…