Well, then we should have a community scheme for setting up surge nodes. I recall one being offered too.
No surge nodes are needed.
Per IP ingress (no neighbors): max was ~55Mbps, with the average being ~5Mbps. This is since the beginning of the year.
To put that into perspective: if tomorrow there was 30x the max ingress per IP, it would still not be enough to fully saturate a decent 2Gbps connection. Let me repeat that: if tomorrow there was thirty times the max throughput we saw since the beginning of this year, it would still not saturate a 2Gbps connection.
Wake me up when we get to 20x the max throughput, at least then we’ll manage to fill up 1Gbps connections.
1 Like
I think surge nodes were for if someone like Vivant started to fill the fast-SNOs quickly? So the concern was those fast-SNOs wouldn’t add fresh capacity quick enough… so slower and slower nodes would be used (and large customers would notice decreasing performance)?
Yeah, we don’t have that problem ![]()
3 Likes
It would still saturate I/O throughput of nodes configured in less than optimal way. We’ve got quite a lot of improvements since then, for example the hashtable-based storage.
Hashtable was explicitly implemented for the select network. Guess why? Remember the customer with supposedly such a high I/O needs that we had that joyful summer last year? Remember that they ended up choosing the select network instead? My hypothesis is that the select network also underperformed, and so some way to speed it up had to be implemented on top of whatever optimizations were implemented on the community network.
I have a proposal: Let’s actually see at least one disk being bottlenecked by incoming data, then we can work on ideas to add the second node on the same IP. If that doesn’t work, we’ll add a third node and so on.
Hell, if 10 nodes on the same IP are still bottlenecked, we’ll even consider migrating to hashstore. Or adding more nodes on top.
I have seen mine. Ended up adding the SSD cache because of that.
No disks here showed wait shooting up, even during the tests.
The only “load” the average node sees… is when used-space-filewalker runs after automated upgrades every couple weeks. Customer IO is basically nothing.
3 Likes
And GC/trash emptying. But yes, I agree 100% that customer load is basically non-existent.
1 Like
That’s why we need more customers and not staking for SNOs.
3 Likes
I wouldn’t say underperformed. The select network was mirroring the same issues we have seen in the public network. In parts it was entertaining to see a similar conversation internally. It took the devs a moment to understand that piecestore was the problem and even if you throw hardware at it the problem scaled exponentially with the amount of pieces stored on disk. An average select node is holding about 30 million pieces if I remember correct. Good luck trying to handle that with piecestore.
2 Likes
Why exponentially? Where did exponent come from? I’d expect linear to logarithmic scaling, not exponential, especially if slightly deeper directory hierarchy would be used to avoid millions of files in a single folder (b trees size optimization).
Do I misremember or was it possible to specify how deep should the directory structure in the blobs folder be?
My average node at home holds 60 million files with a piecestore and I see absolutely no performance issues, even with the inefficient shallow directory structure:
% time find /mnt/pool1/storagenodes/one/blobs -type f | wc -l
63915168
sudo find /mnt/pool1/storagenodes/one/blobs -type f 0.01s user 0.01s system 0% cpu 42:33.42 total
wc -l 32.83s user 2.13s system 1% cpu 42:33.42 total
1 Like
I believe the root cause was that the inode tree was getting to big and also fragmented over time. At first everything will run fine. TTL cleanup and garbage collection are fast. The more pieces the node stores in the same satellite namespace the slower these jobs will get. Lets say deleting a file takes just 1ms at first but at some point 10ms and so on. That part will scale linear. The exponential growth comes from the fact that each day 1/30 of the data expired. That is a second linear factor. Now you have 2 linear factors multiplied together and that makes it exponential. At least in this case with a fixed 30 days TTL and just scale up the amount uploaded to the node.
2 Likes
Two linear factors together make it quadratic. O(n2). Exponential degradation (O(2n)) is drastically more severe, and cannot result from the process you described.
One of those factors should be possible to mitigate by deeper directory structure. Was it tried?
@littleskunk’s explanation is indeed a bit imprecise. Saturation can make a linear increase of input data into exponential increase of latency.
3 Likes
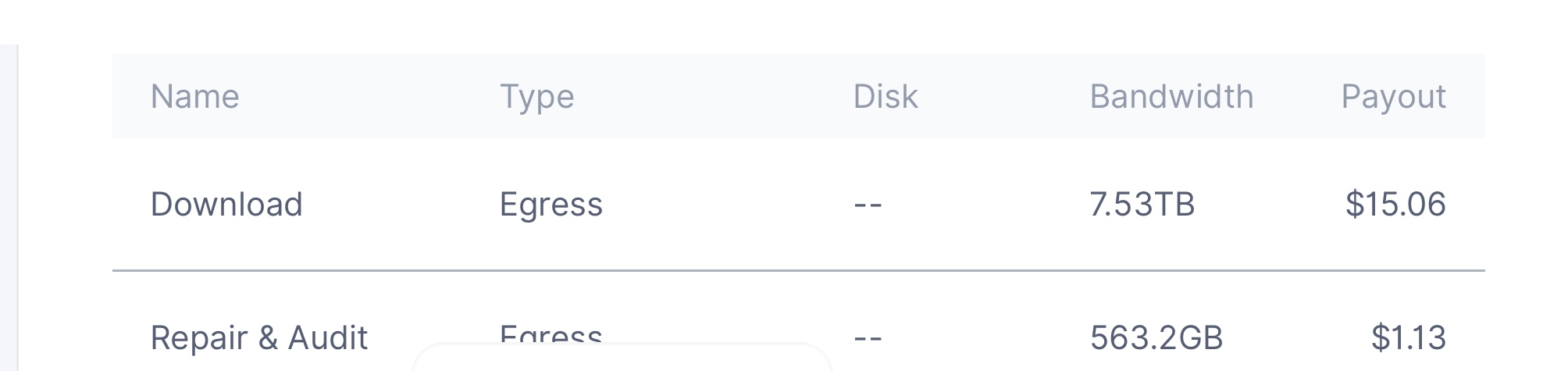
After 4 years, one node per IP, the stored data capped at 9TB. So no matter how huge is your drive or internet bandwidth, 10TB seems to be the limit at which stored data and deletes cancel each other.
Going with bigger than 12TB drives seems a waste of money and space.
6 Likes
This seems to be true accross all my nodes.
I got the larget one that has ran for the longest at 10TB used space- never seeing it grow.
I run many nodes pr IP, so I can’t really say what the max usage is, but I have several IPs with over 15 TB total ![]()
2 Likes