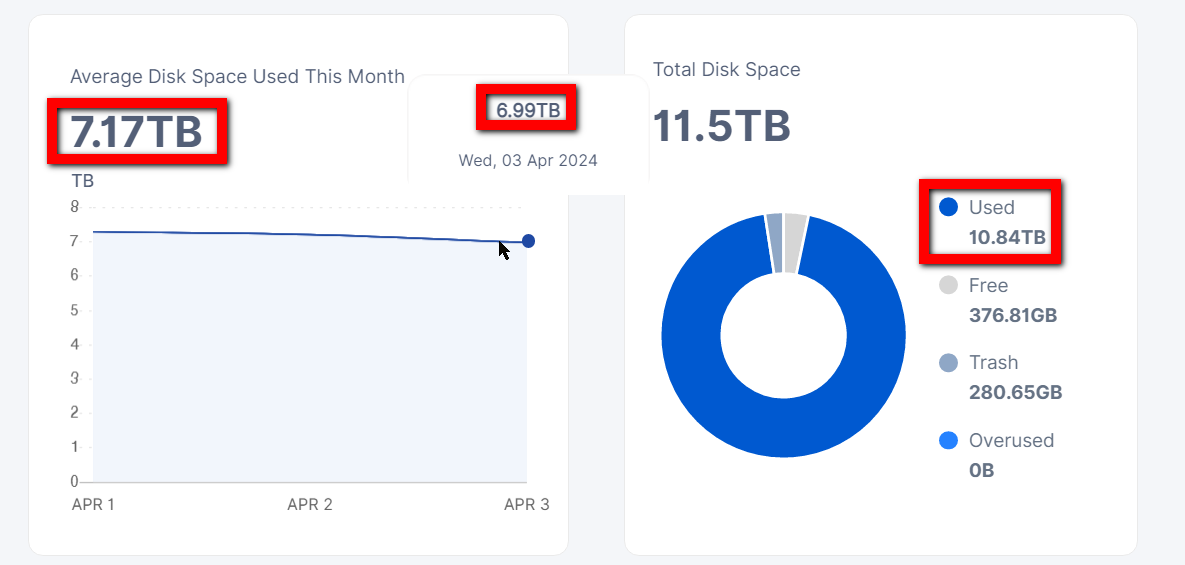
The value shown as disk space average is the average over the daily values shown in the flyout.
In my case this is now 7.3TB, 7.22TB and 6,99TB. This is ((7.3+7.22+.6.99)/3) 7.17TB and exactly the value that is shown as average.
The reason why the last value is now 6.99 is that in the meantime satellite 3 of 4 has reported a value for today.
Of course this increases the total average value. But that is the nature of it. My images clearly show how that value goes up and down depending on the last (todays) value.
Now the question is, what are these values from the flyout? These correspond with the values from the API named atRestTotalBytes. To my know knowledge these are simply total bytes stored, not byte hours or TBms. Therefore it is the space considered as used by the satellite. For this node this is 7298952533883 (7.3TB), 7215653316853 (7.22TB) and 6985311315769 (6.99T).
So what I see on the left side of the screenshot are daily used disk spaces and an average calculated from them.
I don’t see TBMs in the graph. Where I see TBMs is at /api/sno/estimated-payout. This tells me that my current disk space for payout is 0.56TB. This is clearly a TBm value and corresponds fully with the estimated expectations of ~ 11 USD. (11$ / (24hrs * 30days) * 36hrs) ~ 0.55 TBm.
And as I see the graph as display of daily used space, of course I believe that the 10TB shown on the right, should show on the left as well, assuming the 10TBs are the correct value. If the 10TBs are not correct, but the 7 TB then the question remains, why is there 3 TB more data stored than it should be.
@littleskunk It’s running the used-space one at max 1MB/s (average ~500KB/s). They both need to be killed if the used-space will finish sometime this year
@d4rk4 I use SMR the correct way . They should NEVER be used in ZFS of any configuration. Your resilver times will be in years (no, I am not kidding). If you do run SMR disks in any ZFS environment, I STRONLY suggest you stop everything you are doing and begin migrating data off them right now. You WILL lose data on that ZFS vdev, I can guarantee this.
I am on the other end of the spectrum. I have donated way too much RAM to my system. And 75% of that is allocated for caching. GC usually just takes seconds maybe a few minutes at most. However I still reduce the GC concurrency down to 1. The outcome of running up to 4 GCs in parallel vs running them in sequence is the same. Just that running it in sequence might be a bit faster. For that reason I would recommend to reduce the retain concurrency.
Would the upcoming changes (progress saving) come into play if the retain concurrency is reduced? ie would they start one after the other? If that’s the case, I will reduce it on that node to keep it online.
I don’t need to do that on other nodes, their disks are plenty fast for anything storj can throw at them.
The code’s comment says: “AtRestTotalBytes is the AtRestTotal divided by the IntervalInHours”
“atRestTotal”:111951343245587.67 (in TB, well, bytes) divided by “intervalInHours”:36 (in month, well hours) = “atRestTotalBytes”:3109759534599.6577 (in TBm, technically B/h)
The databases are in a ramdisk and are deleted on every host restart. The node clearly has no idea what data it has on it (there aren’t any databases to refer back to), so it gets this data from somewhere. What I suspect is happening is that the satellite says “you should have this much data on April 1st, this much data on April 2nd, and this much data on April 3rd”. The left side is an average of those three values. Yes they are reported in bytes, but they are used as TBm. Ie at the end of the month it should match.
Untill now I took Storj’s side, agreeing that they should not pay for trash, because the trash is not payed by clients, and after 7 days you get rid of that trash, and the space is free for new data. But in the recent months, the trash is almost never empty, and takes space from our storage daily, space unpaid for.
Clients keep deleting data day by day; it seems that the Storj’s usecase starts to change from cold storage to hot storage, with more data kept for a short to very short time.
This reflects in increased Trash and more space unpaid for not by the clients and not by Storj.
The only party that looses money here is us, SNOs.
The agrement between us and Storj is very simple: we provide storage space and bandwidth for data, and they pay the space and bandwidth used by their service.
Now, we somehow deviate from this simple agreement, and we provide also space unpaid for, which increases more and more.
WE REALY DON’T KNOW WHAT TRASH IS. It could be also undeleted data, that is just moved by Storj there to be unpaid, and moved back before 7 days passes. IT CAN BE ABUSED. So it’s very unfair to us to have an unlimited storage space unpaid, unaccounted for, that could be used for anything.
All the space used by storagenode should be accounted for and paid by Storj. We realy don’t care how that space is used, storage space is storage space, each byte is equal to another byte as storage value and capacity.
What you are saying was correct a few month ago. For a long time the average disk space graph was showing what ever the tally job on the satellite side has calculated. The problem is the duration tally needs. Lets say you have 1 TB stored for a month. Tally takes 23 hours to run. For 23 days in a row you would see 23TBh but one day tally will finish early in the morning and 23 hours later a second time on the same day. That would be 46TBh on that day and a strange looking graph on the storage node dashboard.
We fixed that. Side by side with the 46TBh result the storage node also gets the tally duration from the satellite. In this case 46h. 46TBh/46h=1TB stored on that day. So the graph is showing you what the satellite has seen on that day. Just a bit of math to eleminate the tally runtime from the equasion and the graph can show you how much used space tally has seen on that day.
Suppose I have a 10TB node, and I intentionally reject every garbage collection request by killing the garbage collection process, so over time I just have 10TB of trash. Should STORJ pay me for this? If not how can they know how much trash a node actually has, while accounting for node errors?
That’s not what my comment is implying, you are definitely risking your node, but when was the last time satellites suffered a major failure that required recovery of pieces from trash?
I don’t have to manage the data on the storagenode. That’s the Storj’s job. I just rent storagespace and run their software.
If shtf than they can’t blame me to mess with their data.