I started normal filewalker, it trashing disk but doing the work faster, as now ingress gone down, it better to make work done
1 Like
my piece_expiration.db shows a lot of pieces with expiration date set to 9999-12-31. First piece with normal expiration date is 2024-07-06. Lets wait to see what happens this saturday ![]()
First stress test seems to show some cracks in the design
Hi,
are you currently having problems with the shipment of Bloom filters? I haven’t received any since 29.06. With some satellites I don’t even have any trash because I haven’t received any for over 8 days, at the same time I have a lot of uncollected trash.
Here is the trash list of my 4 nodes
.
├── pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa
├── qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa
│ └── 2024-06-29
├── ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa
│ └── 2024-06-25
└── v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa
└── 2024-06-29
8 directories
.
├── pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa
├── qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa
│ └── 2024-06-29
├── ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa
└── v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa
└── 2024-06-29
7 directories
.
├── pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa
├── qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa
│ └── 2024-06-29
├── ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa
│ └── 2024-06-25
└── v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa
└── 2024-06-29
8 directories
.
0 directories
The fourth node is very fresh
The folder 2024-06-25 is currently being deleted.
1 Like
This never worked as it should. ![]()
1 Like
yes, but I don’t think I’ve ever had so few
Hi, i have 30 nodes on windows and i have disable lazy fw on all my nodes. I had the incongruent space for many nodes. After 250 hour of normal filewalker and the version of node 1.105.4 a node of 12 TB is returned to normal capacity and i viewed in dashboard the correct data information. Then for normal fw is about ten days for complete the filewalker for a node of 12tb full.
do you have 30 nodes on 1 PC?
I think it was combined with High ingress, so worked very slow.
Absolutely not, they are installed on various HP Proliant dl380 G8 servers. Dual processor with 24 cores/48 threads and 256GB Ram and various HP StorageWorks D2600. I have various Windows VMs on ESXI and each disk is passed through raid 0 to the VM and the disks are managed by a SAS controller with 4GB of cache. I have multiple servers in various locations but which also perform other functions. On each VM I have a maximum of 8 or 10 nodes, and each VM has a dedicated SSD for the DBs and has 48GB of RAM with 12 cores assigned.
1 Like
I hope my will end faster, as mostly i have 4tb-6tb hdds, some 3 tb, some 8,10, 18,20
I would wish to have setup like yours, but i made my mostly from parts I got free.
But slowly upgrading controllers to HBA better HBA, and DB from os ssd to NVME, as today DB want more and more.
2 Likes
I know this isn’t the best setup for managing nodes but since the servers have to stay on to provide other services, I took advantage of the infrastructure to add nodes that pay me back in part for the power I use to keep them on.
I just bought 10 x 8TB SAS disks at a good price and so I can increase the capacity. ![]()
1 Like
I have 100 nodes around 534 TB
1 Like
I have 30 nodes for around 130TB but I’m replacing the 10 x 8TB disks I bought with the 3TB ones I have. Then I see if I reactivate the disks that I remove or sell them and buy new ones with larger capacities or reactivate another 10 nodes.
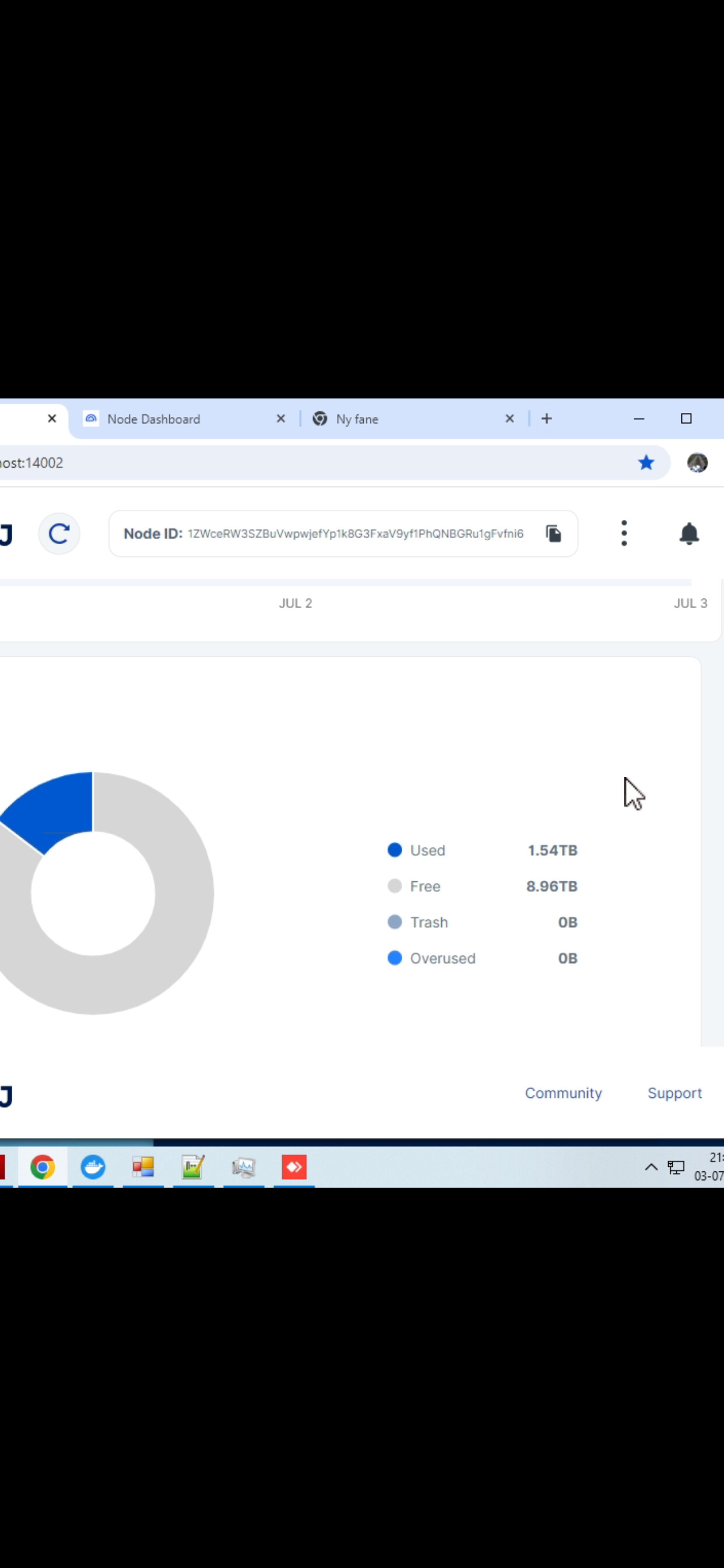
I have my node that has started to sway away from the dashboard number. The used on the actual filesystem is 7.8T as compared to 2.45T on the dashboard. Is there something I need to do or execute?
Linux Filesystem
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 15T 7.8T 6.0T 57% /mnt/storj
Dashboard
Total Disk Space
15.07TB
Used: 2.45TB
Free:12.55TB
Trash: 76.51GB
Overused: 0B
Hey, I helped my friend make his first two new nodes. They are about a week old. The largest looks like this:


How can this be?
Database is on ssd
The rest is pretty much untouched.
Both nodes have same issue, file system is NTFS.
have you ever finished a lazy filewalker on one of your nodes? I wonder how long they take.
are the node disks all simple NTFS disks?
I have 17 nodes with half your capacity. ![]()
1 Like
You likely have errors in your logs related to databases/filewalkers.
Please search for them (PowerShell):
sls error "$env:ProgramFiles\Storj\Storage Node\storagenode.log" | sls "database|used-space" | select -last 10
Seems the USB disk doesn’t have this option to enable a write cache.
yes, enable a scan on startup if you disabled it (it’s enabled by default), save the config and restart the node or just restart the node if you didn’t change the default option. If the used-space-filewalker would be able to finish scan for each satellite, it should update databases. If you also do not have errors related to databases, they would be updated.
It’s both. When you restart the node and if you didn’t disable a scan on startup (it’s enabled by default), it will fully scan all pieces and will attempt to update databases. If there were no errors related neither to a filewalker nor databases - the stat will be updated.
During the usual work each operation updates databases too, i.e. if the customer would upload data the usage will increase, if the GC would move data to the trash, it will update databases too, the same for the TTL collector and the trash filewalker.
So, basically if your node was able successfully scan all pieces and update databases, the scan on startup would be not needed, unless it have errors related to filewalkers/databases or we have a bug with updates of the databases (and we have at least not updating databases on removal of the TTL data in version 1.105.x, it’s fixed in the next release though), or you have a third-party usage on the same disk (VMs or Chia, etc.).
Right now the scan on startup is strongly recommended, until all issues are resolved.