All I can say is good luck bro
Hi, the suggestion is the same
Node dashboard still reporting larger than real used space.
So, will this ever be solved?
df -T --si
/dev/mapper/cachedev_2 ext4 8.6T 5.4T 3.3T 63% /volume8

Hello @humbfig,
Welcome back!
Please enable scan on startup, if you disabled it (it’s enabled by default), save the config and restart the node.
Wait until all used-space-filewalkers will finish the scan for each trusted satellites without any errors related either to a filewalker or databases. This may take several days.
1 Like
Hi Alexey!
I was sure I had the scan enabled, but it wasn’t… ![]()
Anyway, it’s been like that for a few months, and I have seen “scan compatible” activity in this disk a few times since. Also, I recall having read somewhere in the forum that a certain new version would force the scan somewhen…
Doesn’t matter… right now it is scanning for sure. I will report the result once finished.
I have another node (that I can not access in this moment) with 600GB in the trash that will not vanish (also for a few months). Any thoughts on that one?
the activity spikes could be from garbage collection btw, since the used space filewalker usually starts only at the beginning of the node and then never again until a restart.
1 Like
yep, you’re probably right… in a week (I estimate) I’ll know for sure…
This node requires to run the scan on startup at least once. The scan will correct all discrepancies - in used space, in free space, and in space occupied by the trash.
If your trash really takes up 600 GB, then you need to check which folders took up most of the space, perhaps you have data left from decommissioned satellites. In that case you need to use this guide: How To Forget Untrusted Satellites with a --force flag.


Yesterday the node did a restart, I was wondering that I lost a couple of GBs. But something is still there


Saved the logs but dont show any result with this command
docker logs storagenode 2>&1 | grep error | grep -E “filewalker|database” | tail
Somehow the blobs are quite big
19G /mnt/storj/storage/blobs/qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa
132M /mnt/storj/storage/blobs/pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa
64G /mnt/storj/storage/blobs/v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa
365G /mnt/storj/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa
446G /mnt/storj/storage/blobs
Did you enable the scan on startup before restart the node?
You may track the filewalker with these scripts:
I guess scan on startup should be on, I have standard Docker conf.
I was scrolling the logs a bit there was an update, the filewalkers were runing several times yesterday. Today I did a full shutdown of the system suddenly there was more space used ![]()

Do not use a scroll ![]() , use scripts:
, use scripts:
Hello,
For a long time on one of the node the filewalker was turned off; I turned it on and ran it several times over a month with parameters storage2.piece-scan-on-startup=true and --pieces.enable-lazy-filewalker=false. There have already been many gc filewalker runs, but the difference between avg and the occupied space is still very large. There are no database errors in the logs, old satellites have been deleted. How can I bring the node to the real value before migrating to hashstore?
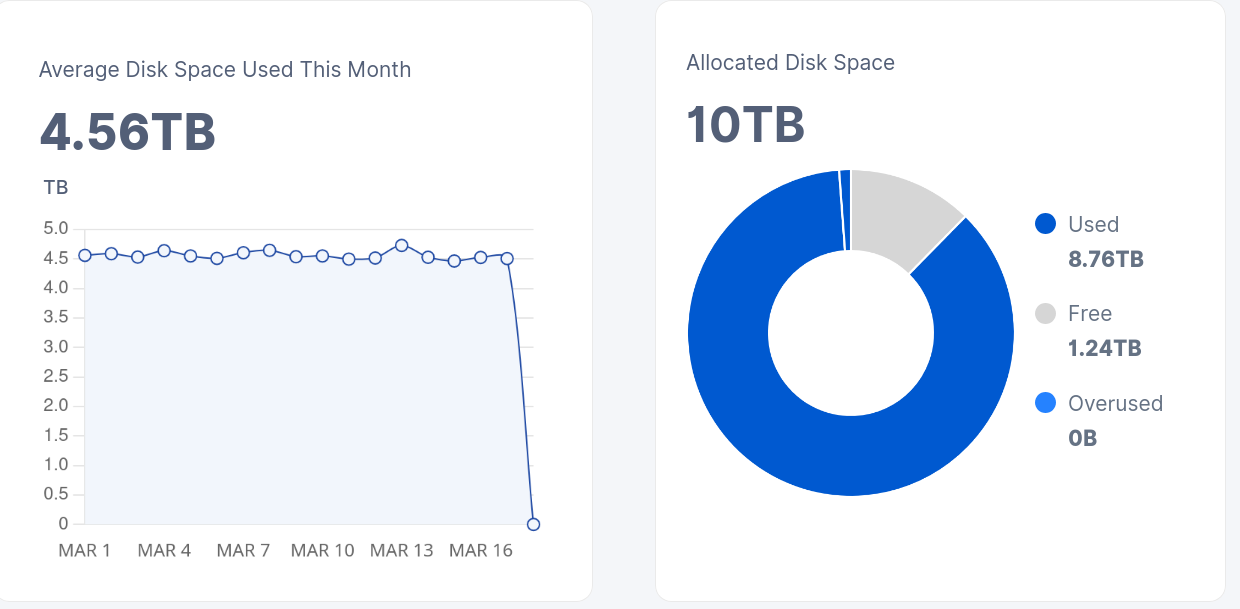
Thanks
Stop node, remove node, delete databases, start node with FW on, lazzy off, let it run.
Hello @mr.Viking,
Welcome back!
You can stop and delete the container, delete the prefix database, and restart it - this should recalculate the space used. Lazy mode can be turned on by the way. Thankfully to the cache realized in a prefix database it should be much softer and quicker.
This is a less drastic step than deleting all databases.
I’ve already tried removing the DB prefix. ![]()
Can all DB files be deleted? It seems that somewhere it was discussed that some one cannot be deleted, I can be wrong
An important remark, the disk actually takes up almost 9 tb of space.