have the same issue- even on raid drives
I have something like that on several nodes, it just turn off node, in logs i see cant write in 1 minut.
checking drive no errors, just start again and working.
1 Like
I’m escalating to the engineers/developers.
2 Likes
Other than daki82, do any of you have reduced audit scores / suspension on gateways due to these connection resets? We know that the NOISE protocol is causing some of these additional errors in the logs. They are benign. So, at the moment, not sure daki82’s errors are the same as the ones you all are reporting. Let me know if you are seeing audit scores going down.
Good afternoon,
The same thing is happening to one of my 6 nodes. At first it was connected via USB 3.0. Seeing the error, I changed it to E-SATA but the problem persists.
I’ve been since 03/24/2023 That every 6-8h gives the error: (FATAL Unrecoverable error {“error”: “piecestore monitor: timed out after 1m0s while verifying writability of storage directory”, “errorVerbose”: “piecestore monitor: timed out after 1m0s while verifying writability of storage)
I also have to say that it was when node was updated to version v1.75.2
Luckily I have a script that checks if the service goes down, tries to start it again and thus I have managed to minimize the impact of being offline a bit.
The node ID is: 1UfmVMbXsTedg5PXBNZ3fs1gc6QfjJ1FhX3VQjKmAi112bGYtb
Attached image the current state
All the best

Thanks, your online score isn’t the same as suspension. Your node may have been down during the update or if your ISP was performing some work. See if this improves or continues to get worse and let us know. It’s not unusual to see a minor drop in online scores like this. The Europe North is a bit more interesting, but that may be the result of low traffic.
Hey , i´m also a newcomer . Operating a Node just for 3 months now , until the update to 1.75.2 everything was running smoothly .
Now i got the same error as above mentioned
2023-03-28T12:24:28.639+0200 ERROR services unexpected shutdown of a runner {"name": "piecestore:monitor", "error": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2.1:150\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2:146\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75"}
2023-03-28T12:24:43.652+0200 WARN services service takes long to shutdown {"name": "orders"}
2023-03-28T12:24:43.652+0200 WARN services service takes long to shutdown {"name": "gracefulexit:chore"}
2023-03-28T12:24:43.652+0200 WARN services service takes long to shutdown {"name": "piecestore:cache"}
2023-03-28T12:24:43.652+0200 WARN servers service takes long to shutdown {"name": "server"}
2023-03-28T12:24:43.707+0200 INFO services slow shutdown {"stack": "goroutine 998 [running]:\nstorj.io/storj/private/lifecycl
and also in the Dashboard , it the Used Disk Space is before the Update by ~1.8TB but the disk has now already 1,98TB .
i got also some E-Mails that my Node is Offline … and some minutes later it´s online again.
i do have a workaround atm , just restart storagenode service if it fails… but it´s not the yellow from the egg… because my online status is going down slowly …
all suspensions are above 99,5% except one from eu.1.storj.io:7777 it´s @94,97 (online 96%)
all others are around 93,8-95,46% Online
if u need node id i can also send it with 100mb log file
1 Like
My Audit Score and suspension is at 100%
1 Like
mine looks verry similar, suspension recovered fast and online degreasing slowly maybe because the constand restarts every day. drivescan etc.
and i had nearly perfect scores over one year exept the windows updates and one relocation. also my dsl connection is ok, as i work in this field. and check it over the fritzbox7590ax. connected via lan.
i think i had the first outtake because of the 24gb log file on a 8gb ram pc. or vice versa (noticed the big logfile after the service stopped).
my internet connection was always up in the last year, exept while new router installation. (long ago score was all 100%)

Also suspension as the node fell out in the middle of the night 2 or 3 times recovered full.
us1 and eu1 now at 95% suspension with red mark sadly.
let me know when a new version comes out.
the autorestarts of the service could prevent autoupdates.
I would check your Windows Event Log to see why the service is stopping. I run windows nodes and they don’t just shut down the service. You might be able to tell more about the error from the event logs.
Under System eventlog I got “Dienst “Storj V3 Storage Node” wurde unerwartet beendet. Dies ist bereits 1 Mal passiert.” nothing special is happening befor that.
My case is exactly the same, the eventvwr shows me every time the error has occurred. about every 6 hours
Attached image

Подтверждаю. У меня тоже такое замечено на нескольких узлах.
Наблюдаю такое последние 2 суток. Возможно это было и раньше. На одном узле из за этого произошли приостановки по спутникам
Это происходит только на v1.75.2

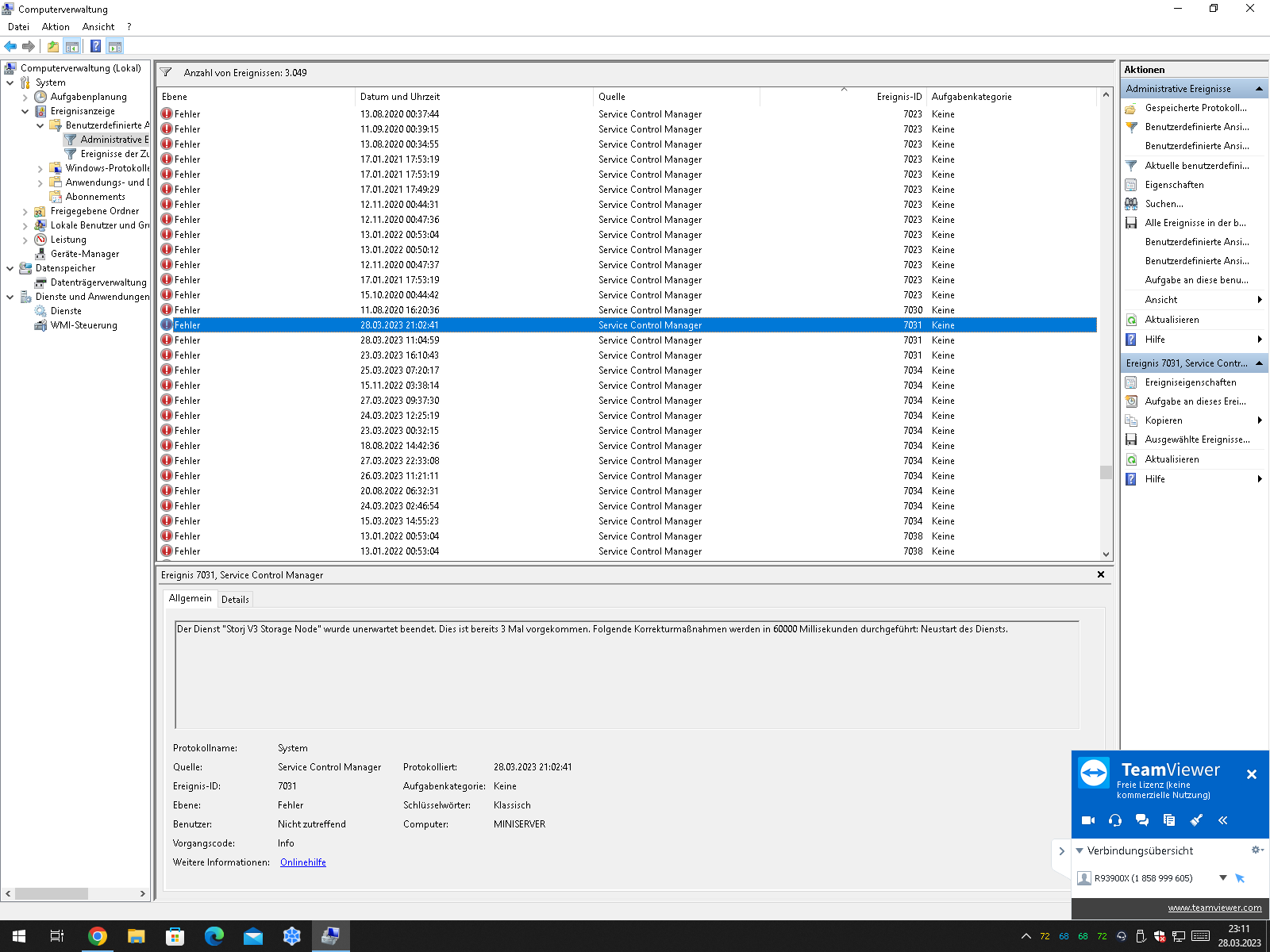
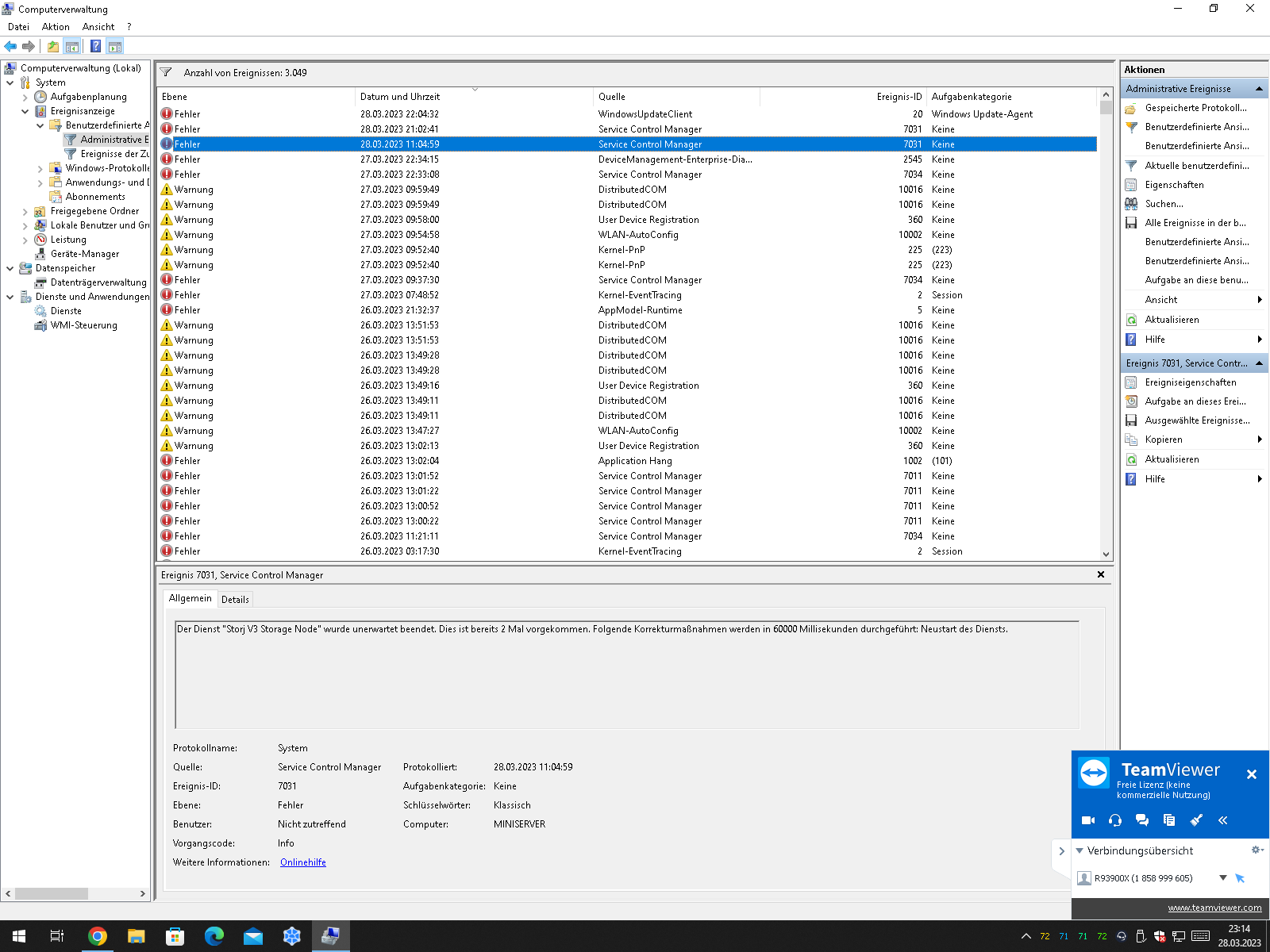
As you can see: here i marked the unexpected closing of the storj service, also nothing around last 2 crashes hapened in the chronoligical sort.
today(28.03.23) 2 crashes one at 11:04 and one at 21:02
at 15.03.23 was an windows update. maybe this one is unrelated to the error
think it all started to go down at the 23.03.23 or 24.03.23 my guess
hope that helps.
Is this happening only on Windows nodes?
I am experiencing the same issues with a FATAL error stopping the node.
FATAL Unrecoverable error {"error": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying readability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func1.1:137\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func1:133\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75"}
I have also seen errors where the issue is writability, not readability.
I ran chkdsk /f and no errors were noted. All databases are intact as per sql3lite integrity check commands.
Windows Server 2016 OS
storagenode.exe version 1.75.2.0
Storj volume is an internal SATA drive
These errors have only been occurring for the past couple of days.
Similar to others I have set up a scheduled task to frequently restart the service as it has been dying every couple of hours or less.
Run with /b or at least /r flag, if you want to catch alleged media issue.
Another possibility is your disk is overwhelmed with IO and delays requests beyond threshold. You can tweak the threshold
(Don’t remember how to do that on windows) or add some sort of caching solution (like Primo cache). Either way, start with monitoring disk performance stats with windows perf monitor.
1 Like
as there are already (4) users with the same error, and the disk is nowhere near its max capacity (paralell use possible) and the serice is just stopping, my guess is its the service overwhelmed with noise connections, also the dl-bandwith is not sufficient to spam the drive (100mbit=~10MB/s vs 250MB/s)