No worries, sorry for derailing the conversation.
Let me try to fix that.
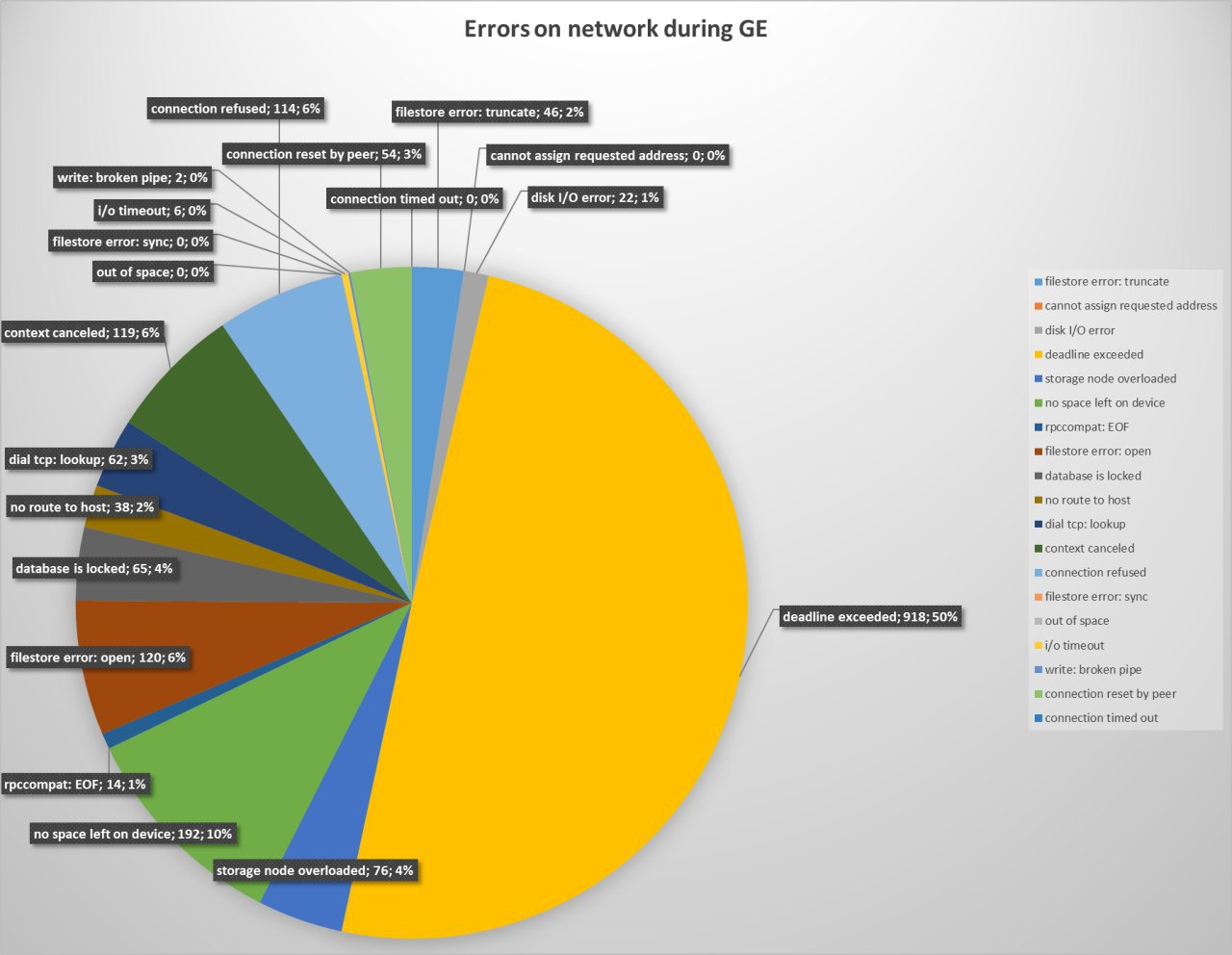
I don’t think there is currently anything implemented to exclude these in node selection or better even, include only IP versions that the transferring party supports (either uplink or GE node). But perhaps I overlooked something when I looked into the node selection. This implementation has recently also significantly changed with the implementation of node cache and I haven’t looked at it too closely yet since. From what I could tell the conditions for node selection have remained the same though.
I know for sure full nodes are explicitly excluded in node selection. Seeing that the amount is relatively low, I think this is caused by a delay between the node being full and the satellite being updated with this info. This update doesn’t happen instantly. They’ve already added a buffer so that selection doesn’t take place if there is less than 100mb available, but I don’t think that is enough.
This one will hopefully be fixed soon by moving the used serials to RAM, but honestly I’m surprised by how low this number is considering how much it’s been talked about on the forums. Very interesting.
I have no idea how this could have happened as gracefully exited, disqualified and suspended nodes are explicitly excluded from node selection. Very weird indeed.
I responded mostly to the issues related to node selection, as I’m not entirely sure much can be done about the others and I’ve previously studied the code for node selection. My source for the info is the code itself. Conditions are listed here and contradict some of your findings, which I find quite curious. Not sure what is going on here.
Hope this made up for the slight detour earlier in the topic. ![]()