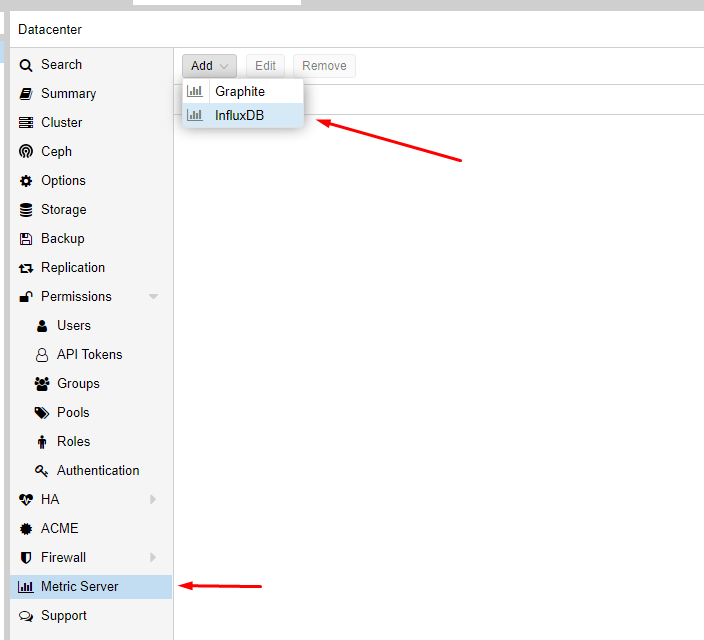
@littleskunk here is a good examples of how it can be sent directly on other systems:
TrueNAS
ProxMox