I had this behaviour. Once I stopped node and removed “used_space_per_prefix.db” and started node. This fixed the incorrect allocated space issue.
I wonder if it would help to run the filewalker more frequently.
Anyways this is not a good behavior for the migration and should be fixed.
I think it was more an issue with my database than a software issue.
Storj node “App” on Truenas (or docker) is not shutting down properly - leaving databases not closed properly.
But others reported a similar behavior that the nodes are going to show as full while migration is ongoing which means ingress to go down to zero. This does not make sense.
I assume you have started the migration. Do you confirm this behavior on that node?
My migration is currently to messy to draw any conclusions from it.
But I have seen nodes where the used space went up but on others it did not.
I have seen 2 out of 20+ nodes showing strange numbers for used space and stopping ingress. One was showing twice the real number after migration. I solved the problem by recreating the databases.
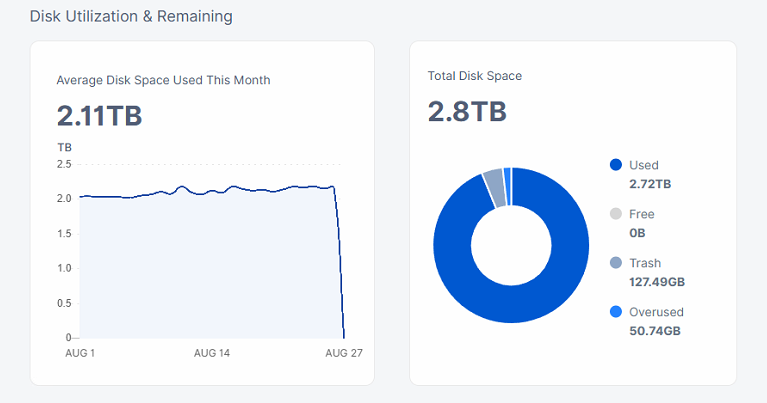
it is 3TB hdd, and hdd has 645 GB free, databases are on NVME
this node has 675GB converted to hashstore.
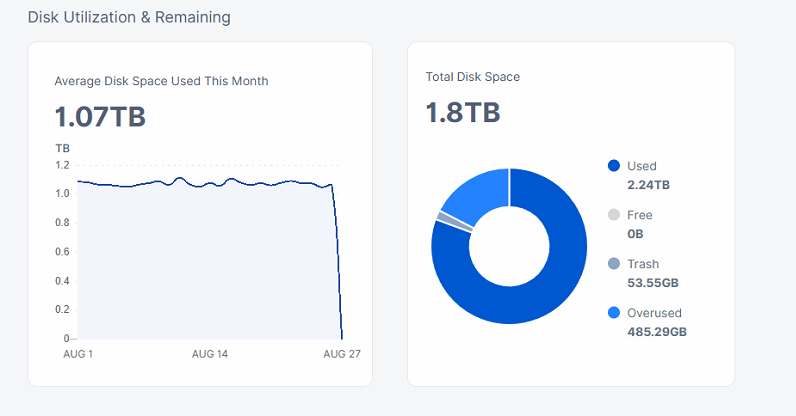
Node is on 2tb NVME, databases on separate NVME
this behavor started after conversion, and some restarts of PC during conversion.
Update: this node is ended conversion, and error not fixed itself, so i needed to delete Dbs, then it gone OK in 1-2 min.
This is exactly what happend on my nodes too. They showed double used space for me. So some nodes were able to still get data if I remember correctly. It fixed itself eventually.
I had this issue to. It happened for few my nodes,when node restarted while active migration in progress. Nodes that not restarted, migrated successfully without this problem.
So far I migrated several smaller nodes without any problems. But I’m wondering, after the migration I checked if there are any left over files in the blobs folder and there are none (which is good). But after the migration I’m left with 4096 empty directory’s (1024 per satellite). Can I safely remove those?
I’m referring to the two character directory’s in for instance: blobs/pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa
The following quote triggered my question
I don’t know how this process exactly work, but its a waste of compute resources if a proces start scanning 4096 empty directory’s, every 10 minutes….
Yes you can. Safest option would be find blobs/pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa -type d -empty -delete
There also might be leftover files in some of the directories, usually with 0 byte size. Some might have non-zero file size as well.
For all these the log will be saying these can’t be migrated because some size (like header) is not matching some other size (file size?).
In my case I’ve delete them all with 0 impact on audit scores and this was many months ago while I was migrating nodes to hashstore.
So don’t be surprised if find -type d… won’t delete all the directories in blobs folder and you will have to do some additional cleanups.
Especially on ext4, where it might be expensive to check (even empty) directories if they contained millions of files earlier.
You can delete the empty prefixes (we may add some automatic deletion in the future…)
I may have missed it, but once migrated to hashstore, is it safe and easy to change from memtbl to hashtbl and back?
In my case I can imagine one node that would always be memtbl, two that would always be nashtbl, and another couple that may vary depending on system’s drive and ram needs.
Thanks.
First I checked with find ./blobs/ -empty -type d | wc -l
If the answer is 4096 (so far it is after 6 migrated nodes), I removed those directory’s with :
cd ./blobs/
find ./pmw6tvzmf2jv6giyybmmvl4o2ahqlaldsaeha4yx74n5aaaaaaaa/* -type d -empty -delete
find ./qstuylguhrn2ozjv4h2c6xpxykd622gtgurhql2k7k75wqaaaaaa/* -type d -empty -delete
find ./ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/* -type d -empty -delete
find ./v4weeab67sbgvnbwd5z7tweqsqqun7qox2agpbxy44mqqaaaaaaa/* -type d -empty -delete
This do leave a empty directory per satellite. I don’t know if it these 4 are still necessary, but I can live with 4 empty satellite directory’s ![]()
So far its going very smooth without any leftovers, but it would be nice if I could speedup the migration proces. The bigger nodes are going to take at least a week (maybe 2) to migrate. I don’t mind some harddisk noise, but this is going to drive me crazy. But that’s a problem for an other time
Yes you can switch both ways. Just be aware that it doesn’t happen on the next restart. It will happen on the next compact job. → It takes a few days to run compact on all 8 hashtables you have on disk.
So that there is no ambiguity in postponing hashstore on a Windows native installation:
The Windows system environment variable to set ‘true’ is:
‘STORJ_STORAGE2MIGRATION_SUPPRESS_CENTRAL_MIGRATION’, and NOT simply:
‘STORAGE2MIGRATION_SUPPRESS_CENTRAL_MIGRATION’
-2 cents,
Julio
I think it is safe to confirm it no. Unless there is massive new data that brought the node down zero space left, then there is this issue.
What is the fix? Restart to trigger filewalker?
We can’t go days or weeks without ingress.
This should also include removal of files that cannot be pieces e.g. zero header ones. I see many of such errors. What would be the point to keep them if they cannot be migrated anyways?