yeah so making a map is easy, having the information of how many nodes that are in an existing nodes particular subnet should be a rather trivial thing to add, and it would make good sense to do so… it could be very useful information for some people…
like say if i had my 1 node and shared a subnet with somebody that had 9 nodes… then i would only get 1/10 the ingress… and have little clue as to why and everything would seem to be working correctly…
well this thread took an interesting turn
checking how many nodes are in my subnet was actually more an explanation of the context of my problem but still an interesting discussion.
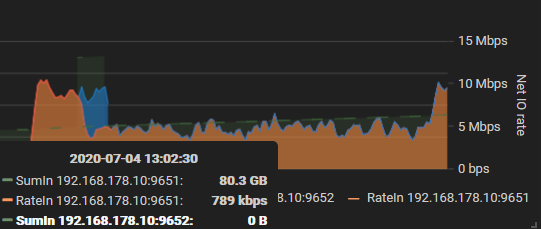
So turns out the satellite will try to upload to an offline node for 4 hours:
So for 4 hours my ingress was still 50% on node 1 while node 2 was offline again. After 4 hours it went back to 100%.
To be able to do so, the customer must have an API key on the said satellite, otherwise it will not be trusted and do not receive needed information regarding either satellite or the node. Otherwise the mentioned site already would have this information in place.
The satellite operator of that site is not trusted entity, this is why his stat is very limited.
and i would almost bet that the 4 hours that are missing will be pushed on to the down node when you online it again…
atleast thats that would sort of fit with what i have seen during extended dt… it will give a boost… atleast after a while… because after all my crashes it does seem like i am falling a bit behind the avg… but still need more data on the bandwidth utilization comparison tread i made…
it is rather interesting tho, it seems like multiple nodes have an advantage against single nodes… but jury is still out, since it’s only data from 3 SNO’s thus far… not that good for statistics xD
Judging from the code there is certainly a difference in probabilities in cases where the subnet has only new nodes, only reputable nodes or both. Essentially it seems that new nodes only compete with other new nodes, and reputable nodes with both.
What’s a thing I’m sure of is that in case two SNOs compete within the same subnet, it is beneficial for them to have as many nodes as possible.
no because that is impossible. The satellite does not cache uploads in any way. If a node is offline during the time of the upload, the data will never get back to the node.
There also won’t be any boost, it’s the same algorithm for node selection on every upload. Some kind of weird boost would be an immensely complex addition and a waste of development resources.
i mean it keep a tally on how much data your node should get during a day… or simply has a target number based on node age… tho from the data we have thus far kinda rules that out…
it seems that it has a daily target… and if your node is offline for 4 hours then it will get more data assigned when it’s back… but yeah you are right the satellites doesn’t cache data…
well i’ve seen the boost repeatedly when i had many extended downtimes trying to get my hardware upgraded and my pools working…
i would be offline for a while and then come back after some hours and i would get high increases in ingress… and it was a certain thing at the time…
ofc the code is continually changing so i cannot say if its still there… i also think it was one of the things that really helped strangle slow nodes… like those having smr drives…
so they wouldn’t be able to keep up and thus end up having more assigned data than they could take… causing them to slow down even further and that would result in more being assigned that they would never catch up to and thus leaving them at 100% utilization for ages maybe forever… just trying to keep up…
it was also mentioned to some of the storjlings, so it may have been changed…
been a while since i had extended downtime… server crashes on the other hand…Grrrr
died again… just now…even after i pulled the damn gfx card…
Are you sure that the increased traffic was real ingress data? Or did you only measure the I/O of the docker container?
Maybe the node does some synchronisation when it comes back online and therefore has some I/O, but that‘s actually not „real“ data that will be stored?
Just an idea…
this was on one of my network loggers / graphs… it was a quite clear trend… and at the time only thing running on the server at the time was the node… happened like 4 - 7 times during extended downtime… took a few times before i started to pay attention to it…
if it was real data i cannot say, but the graph usually fits with the ingress… roughly… haven’t exactly checked the accuracy 100%… i mean the node could be verifying some of the last data received or doing something else that requires “ingoing network bandwidth” that i cannot say… the allocation of data hypothesis just made good sense, since V3 aim’s for equal distribution of data between SNO’s
easy way to solve that issues is to simply have a number that should be attempted reached, and handing out data based on that and some sort of query depth thing…
but again i think it was partly what choked SMR drives so not sure it’s around anymore… but my V3 node isn’t that old… i doubt they changed so many things already… but who knows what kind of stuff they did change…
That will get you at best a 5% ingress boost and if you look carefully there is a deduplication later in the code that will removed duplicates from the same subnet. Not really worth it, especially since those nodes exit vetting at some point anyway.
That sounds like a very good reason to not provide this information to SNOs as it would give a perverse incentive.
It’s open source code… I really suggest you look at the code before making such claims to begin with as it’s definitely not true. Node selection essentially selects random subnets and then picks a node within that subnet. There are filters for offline, suspensed, disqualified and full nodes etc. But that’s it. You’re seeing patterns where there are non.
Indeed, I’m not claiming the difference is big. But claiming it’s at best 5% is wrong, because the actual percentage will depend on number of subnets with each type of nodes.
Consider the following situation: there is 100 subnets with a single new node and 10k subnets with a single reputable node, assuming first that there is no overlap between lists of subnets. Also assume we have 100 subnet slots to fill. Then it turns out a given new node has bigger chances of being selected (5%) than a reputable node (0.95%). Any overlap will only increase this difference.
It would be a funny project to try to measure the actual number of subnets with new/reputable nodes statistically, from what can be observed either as a SNO operating in a single subnet or as a customer. For example, maybe there is a way to figure out, from the customer’s perspective, whether a given node is a new one or a reputable one. I would suspect that, assuming the list of candidate nodes received from the satellite is ordered, the first 5% of the list are the candidates from the new nodes list.
It is indeed perverse incentive, but it’s not like this information is not public. Besides, I’m not sure it is possible to avoid this problem either.
I think you made a very big assumption there that 95 reputable nodes and 5 new nodes are selected. I don’t think we have any way to know the settings the satellite uses for those values. And I’m fairly certain last I heard more than 100 nodes were selected for each transfer.
really doesn’t have to have anything to do with what you mention… i just know what i saw happen, repeatedly… i have no interest in digging through the code (something which i will have no future use for), besides understanding one bit of the code, doesn’t mean one understand the behavior of the entire system…
was it real… who knows… sure seemed like a repeating pattern after extended down time
should be pretty easy to test… ill try to document the effect when i next have extended downtime, if its still there… haven’t had extended dt since around when V3 went into production…
That’s the thing with code. It’s exact, you don’t have to guess. The only way to get data is for your node to be selected for upload. That selection doesn’t take recent down time into account at all, just the current state of your node. I don’t have to know the behavior of the entire system to know that increased ingress after downtime isn’t happening. I just have to know how node selection works. And that just happens to be one of the areas I paid a lot of attention to in the past. If you’re not willing to look at the code it seems a bit silly to argue about that with someone who did do exactly that.
Unfortunately I don’t. Since the settings storj uses aren’t part of the code. But I would hope that that 5% number that has been mentioned is about actual amount of traffic and not that 5% goes to new nodes. If it were the latter there could even be a scenario where new nodes get more data than existing ones.
ill try to document it… it very much looked like it was a thing until recently… i duno why
also seems silly to take down my node for like 6- 8 hours just to prove you wrong lol
i suppose it could be some sort of windows vm or server linux os thing… downloading stuff when it gets back online after extended downtime… my node isn’t exactly separated in the network bandwidth usage graphs, and i cannot remember if i checked if it was actual node bandwidth …
also not sure if the windows vm was on auto startup at the time… don’t think so… but if it was, that could make the “download” bandwidth go up
but those are pretty obvious things i’m fairly sure i would have checked… but who knows lol
it didn’t seem like an important think that was useful for anything…
for a brief second i was considering if that was a way to boost node ingress… but it seems like it was less data than what one had missed out on during the dt… so that didn’t go far…
Oh, yes, I agree. Though given that the NewFraction setting is defined as it is, I strongly suspect Storj folks talked about this number exactly. As far as I understand—and I might be wrong, as I haven’t spent too much time reading the code—changing this setting would require restarting the satellite, so I doubt it would be done often.
And if you wanted to preserve the 5% number as an actual fraction of reputable node’s traffic going to a new node, you’d need to keep changing it as the numbers of new and reputable nodes change.
Such “boost” can came from a test traffic uploaded by StorjLabs, not from a normal customer traffic.
If satellite running a test routines have some sort of “plan” how much test data should be placed per each qualified node during programmed batch - then it can result in higher traffics on nodes which “lagging behinds” test schedule due to being offline for some time after they come online again.
and where do you get that “logic” from? I seriously doubt that storjlabs keeps track of how much data each node has stored and then uses a “manipulated/changed” satellite and uplink software to specifically choose nodes with less storage for additional uploads (and when doing so, it needs 34 more nodes to upload a file).
The programming effort for something like that would be huge and completely unhelpful.
(apart from that you can see in my charts that I got absolutely no boost when my 2nd node came back online…)
I’d appreciate it if more people would just not try to create weird theories based on “feelings” instead of proper research and reading the code or relying on what storjlings tell us.