The worst thing about it is that there is absolutely no need to implement it in such a way that it turns out to be a stress test for the drives.
It is basically the same when the regular filewalker started to create problems.
Maybe at the beginning such implementations were fine. But now with growing nodes and of course increasing load do to more customer demand, this sounds like the wrong way to do it.
These kind of file traversing processes generally must run with the lowest possible priority and as rarely as possible.
1 Like
What’s filesystem and OS you have used? It doesn’t sounds like a normal.
Do you use any kind of RAID?
TrueNAS Core. No raid for storj drives.
No errors… nothing. Just locks up. If I turn nodes off it runs fine. I can stress the system in every other way I can think of and it’s fine. CPU, RAM and file transfer stress tests all run fine.
I would assume that you use zfs there. It requires tuning to work normally, like a record size for example.
See Topics tagged zfs, and Notes on storage node performance optimization on ZFS in particular.
I hope @arrogantrabbit or @SGC can give you more advices how to tune it.
Usually your system could struggle with disks subsystem, when there are some issues, may be even with disks or hardware. It should not hangs on filescans, especially so tiny ones (it traverse only across the trash, not blobs).
If your system cannot deal with a few GB of files on disks, it doesn’t sounds right.
1 Like
Yes zfs. I use 1M record size, lz4 conpression, atime is off. All drives are new Exos 18TB as of a couple months ago. Sequential transfer speeds of ~2gbps. Run a storj node on it at the same time though and that drops to speed of snail.
I’ve also experimented with other zfs tuning in the past but didn’t really see any benefit to most of it.
The problem is there is no sequential reads or writes most of the time, it generally always a random access for not big files. So, zfs there is not helpful much especially as an simple pool. For such cases ext4 would be much better. However, I’m sure it’s tunable, especially when you have enough RAM.
I can only suggest to read the linked post, where you can find useful options. And lets wait for other Community members with suggestions how to improve your zfs drives. Such a powerful system cannot be so slow (I did not have any issues even with Raspberry Pi3 with only 1GB (but it uses ext4)).
The filewalker on startup is a killer, thats just a matter of fact no matter what you a running.
I run with atime=off, zstd-1 or 3 i forget, i keep it low to have it similar in draw to lz4, will give better compression results in some cases, ofc most of storj data won’t compress so less important, but one has to run some kind of compression for zfs to do some of its magic, like dynamic recordsizes.
xattr=off,
logbias=throughput i’ve learned a while back that it supposely is a bad idea, but its a major performance boost. and i’ve not seen any detrimental effects from it for the years i’ve been running it now.
Recordsize=64K, tried most of the other settings for long periods… started at 512K, however larger recordsizes creates a caching issue and also creates more fragmentation long term.
bigger records will however speed up stuff like migrations.
a l2arc is a nice little extra thing one can add some extra reads, but it also wears on the ssd a bit.
special vdevs can be really cool, but again they wear the SSDs pretty extreme, i got a 1.6TB SSD i’m in the process of replacing, because its gone through its rated 5.5PBw life…
initally i was hoping to run other stuff of the same storage pool as storj, but in the end its just a bad idea most of the time, storj iops is killer.
my pool manages, but i also run a lot of nodes, but its also a crazy setup… i mean it has 224GB RAM of which 112GB is always allocated for ARC.
a SLOG can also help with performance, but its one of those things that logbias=throughput bypasses… is that good or bad… well that might be a tricky question.
right now my pool reads are 783 ZFS record reads and 303 of those comes from my L2ARC
then ARC most likely takes a few thousands.
so my disks are mostly just focused on writes of which there are 7100 of which 5000 goes to my special vdevs for small blocks anything less than 4k will go there.
but yeah… zfs can be great for larger setups and its certainly good for keeping data safe.
its faster for some operations and slower for others.
you can also do
zfs set sync=disabled poolname (WARNING DO NOT USE FOR EXTENDED PERIODS)
this basically makes the zfs pool cheat… it will just say its performed a sync writes even tho its actually in memory.
its nice if one needs extra speed… i use it on occasion… it almost never lost me files ![]() only a few lol
only a few lol
1 Like
The file walker would not be a problem if we had a purpose-built file system. One that would store inodes within direntries—as this way there we would save all the seeks necessary to read inode data usually scattered across the whole drive. Though, having inodes within direntries makes hardlinks impossible. Storage nodes don’t need them, but because hardlinks are a wanted feature, none of the popular file systems do so.
FAT derivatives do so, but they don’t implement a tree-based file name lookup, so they’d be slow for regular upload/download operations.
If there was enough money in hosting a Storj node, I’d maybe build a file system with the necessary properties. From a purely technical perspective it’s not that difficult with FUSE. Though, it’d still take some time making sure it’s reliable, and getting an SSD cache is cheap workaround, so there’s not much point in doing so.
Elaborate on this one. if you are using single drives with your pool you are limited to 200iops. This is very little. Slow storage will cause huge memory usage, evicting your ARC cache, causing everything else to die.
I’m seeing significantly higher utilization – on 8 drive array I’m seeing about 40-50 IOPS on drives, and about 100-150 on cache and/or special Vdevs – 200iops is likely not enough.
I also don’t see any issues on startup – storagenode is using 100% of a single core for about 2-5 minutes, reading metadata from drives, aparently.
I was seeing same performance before and after adding special VDEV. There is 32GB of ram on the system, out of which 20 is available to ARQ (that is periodically evicted by SMB caches). Before adding special vdevs I had L2ArC, but removed it later, as it wasn’t making any signigiant difference.
This is unnaturally extreme indeed. Have you overridden ashift to the 4k when adding special device? Most SSDs report 512e, and that will murder them very quickly.
I’m seeing consistent 80 IOPS/ 2MBps writes on special devices. In 5 years this will write 2/1024/1024/1024*3600*24*365*5= 0.3PB. Write endurance of my drive is 8PB (this is DC S3710) – not even close.
I agree on disabling sync for dataset storage node is using – there is zero reasons to do synchronous write with it, ever. But definitely not on the whole pool. Unless your whole pool is for storj. It’s not cheating, it’s optimizing for the task: storj can tolerate data loss, no reason to pay for iopf to avoid something inconsequential that is also extremely rare
There is no need to invent another filesystem when existing ones work just fine.
If after implementing all those suggestions you guys are still seeing performance bottlenecks with current level of storagenode traffic – something else is terribly wrong with your hardware. FreeBSD included excellent dtrace based performance analysis tools: it’s time to use them and find the bottleneck: storage node load today is miniscule, any decent system shall be able to handle it.
3 Likes
I just had to reboot the server for unrelated reasons, so here are some plots.
Storagenode on startup was consuming 100% cpu for 10 minutes, during which time it was reading from metadata device at ridiculous rate, peaking at 3k IOPS:
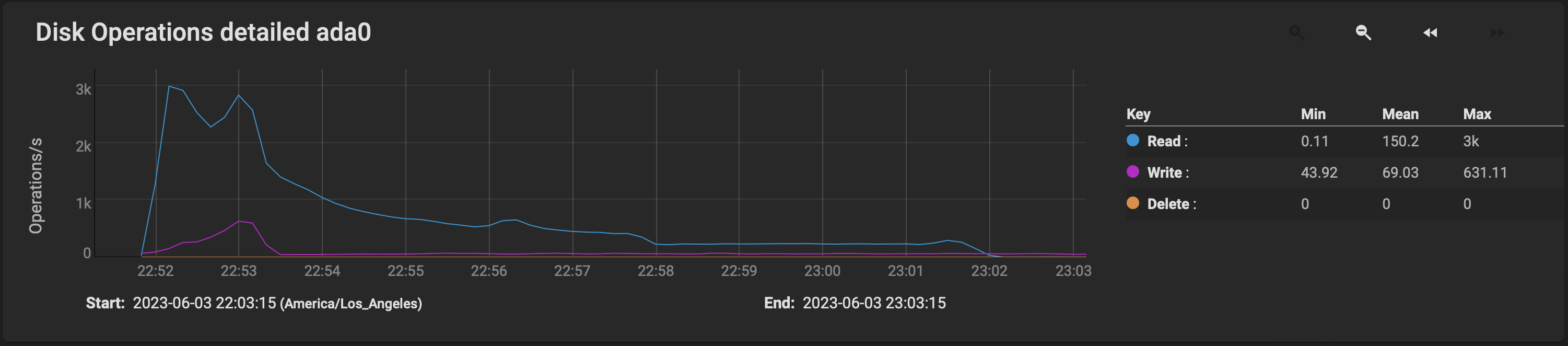
This is the activity on one of the HDDS on the array during the same period:
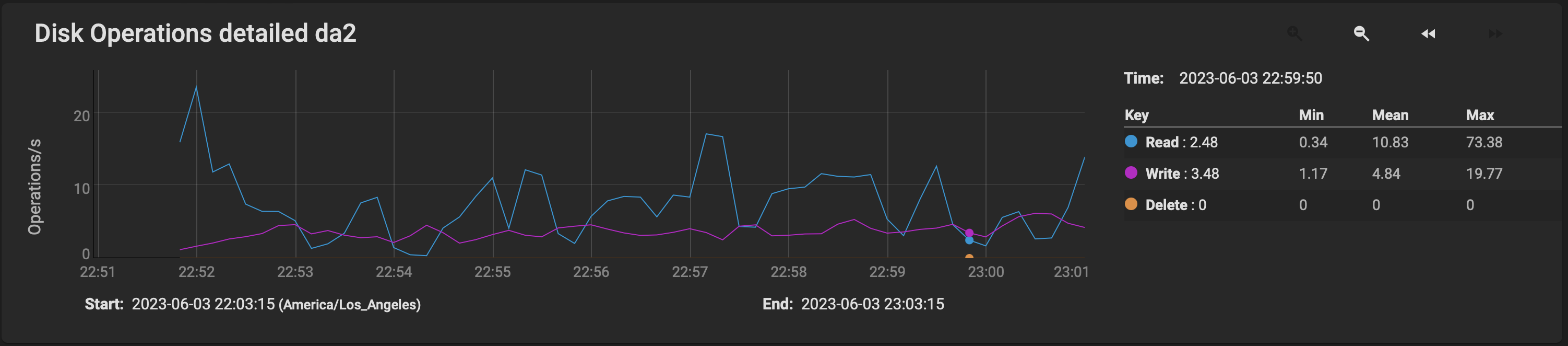
I.e. big fat nothing.
This confirms that the storagenode startup is metadata heavy: moving metadata to a fast device (cache or otherwise) removes any impact of a storagenode cold startup.
Curious behavior of ARC during this time:
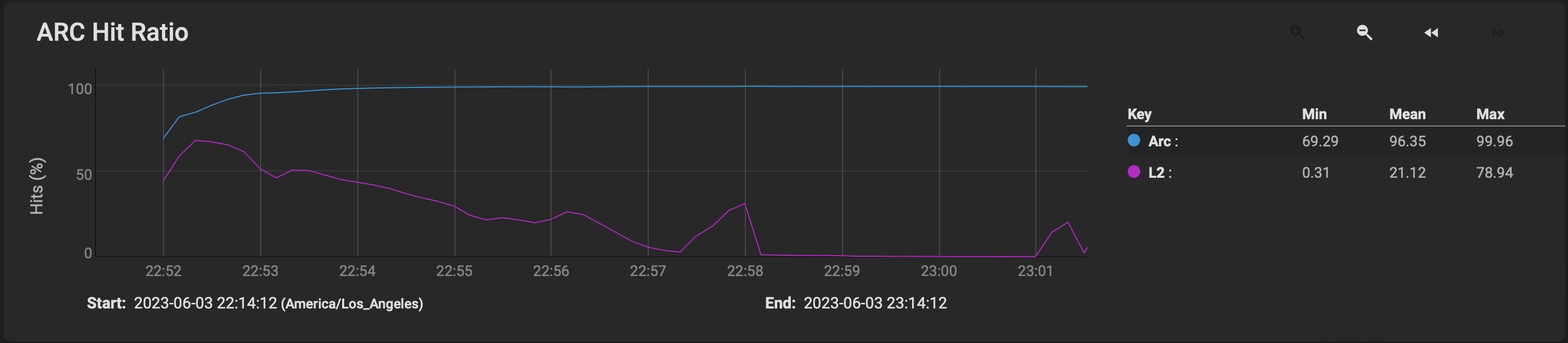
This node holds just short of 12TB of data, and startup took just over 10 minutes, on a 2012 era hardware.
1 Like
I think that’s what we are talking about.
The question is, is it the regular startup filewalker in your case or the crazy trash chore?
In any case history has already proved that these filewalkers are terrible and can cause problems. That was the reason for much complaining in the past and the implementation of the option to turn it off and now the lazy filewalker.
There is almost no reason to believe that other filewalkers which are implemented by the same original concept would magically cause less issues.
These filewalkers must be reduced to an absolute minimum. and when they have to run they must run with the lowest possible priority.
2 Likes
Good question. I’m not sure how to verify that. I guess I can disable file walker, restart node and see what happens.
I agree. Not just with lowest priority, but also likely throttled, literally limiting IO rate. There is no rush to complete this in 10 minutes; this should not preclude node startup and operation, so if it takes one months – so what.Running this on startup seems like worst possible time to do that – likely everything else is also starting up so this background maintenance definitely out of place there.
2 Likes
I don’t know if throttling is necessary. I agree that there is no need that such a filewalker has to be finished as fast as possible or in a certain amount of time. But if there is nothing else to do like when client activity is low why not let it run as fast as it can. Let the OS decide I’d say. if there are other tasks of higher priority then slow it down or even pause it otherwise let it run.
2 Likes
Hey guys, thanks for the input. Sorry, I’ve been busy so haven’t had time to post. I was able to get my system stable. I just waited for a bit after startup then spun up the nodes a couple at a time and let them settle down before starting others. Been ok since. In the meantime I got another server in and installed that yesteray with TrueNAS Scale. Going to try migrating some of the nodes to that and see how things go. Almost twice the cores and 4x the RAM. Although my cpu and ram usage are relatively low, there is still a lot running on the server and I do have spikes sometimes so maybe offloading some of that will make the difference. Now to go figure out how to migrate nodes from bsd jails to docker containers.
This should not be an issue.
In docker nodes all data is inside a storage folder (databases, blobs, trash, etc.).
So basically you need to transfer everything “as is”, and use the correct paths on your new setup (you should provide a parent directory for storage in your mount option).
Well although I use docker for many things (currently running within a VM on Core) I’m not a docker expert by any means. I’ve only really started something in docker and kept it there. I’ve never tried migrating something into it. Probably not a big deal, I’ve just never done it. Thanks for the info though, it’s always appreciated.
1 Like
Apparently they aren’t, if we have so many threads about that. Besides, we can throw resources (RAM caches, SSD caches, redundancy schemes) at a problem until it disappears, but the key here is to solve a problem with minimal resources to make it profitable. ZFS is great at throwing resources at a problem, but it should not be necessary to have a 112GB ARC to run a node.
Agree with that, but disagree with this:
File walker is just a distraction, it is not a big deal an can be trivially fixed, but it highlights underlying issue – slow random IO. (And 112GB is not necessary - see below)
Look, it’s very straightforward:
What is the [most?] important property of a successful node? Ability to win races. This means short time to first byte when randomly accessing stored multi-terabyte volumes of data, compared to the time to transfer said data. This is a rather unusual requirement in the world of consumer electronics where storage nodes whose owners create threads you referred to. Yes, including “prosumer” solutions, like Synology. Those are optimized for totally different tasks (and even there first thing to improve performance is to throw a lot of ram at the problem).
How can we solve this? Obviously, reduce local delays. You can’t do anything about network or distance.
Simple expensive solution is store all data on SSD. Overkill, but will work fast. But large SSDs are expensive. We want to store most of the data on a cheap HDD.
But HDDS are horrible at seeking, so we want to avoid reading small data (where seek time will be much larger than transfer time) from them as much as possible, and only read large blobs from there (where seek time will be insignificant compared to transfer time).
What is small and being read even more frequently than data itself, and happens to be random as well? Metadata. So, let’s not read metadata from HDDs.
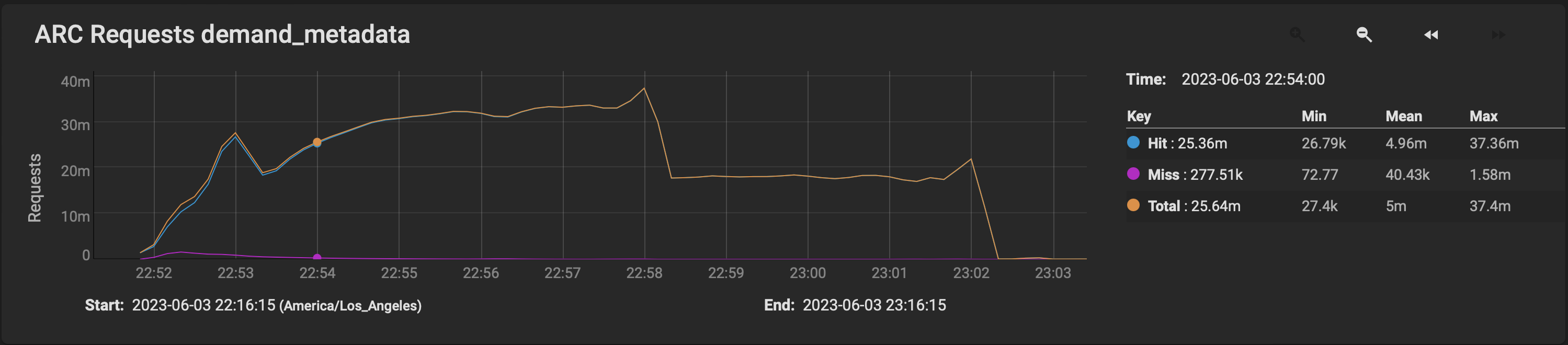
How? One way is various ram caching solutions: if all pages with metadata fit in ram – problem solved. But as you said, 112GB of ram is overkill. It is however, overestimation: If you look at graphs above it’s clear that after about 1-3 GB worth of pages with cached metadata the ingestion rate drops drastically – most requests are now served from ram. 1-3GB is not that big of a deal.
But OK, you don’t have even that ram to spare. What is the next best thing we can read metadata from? SSD. ZFS happens to let you place metadata and other small bits and pieces to an SSD – exactly what storagenode needs. If you don’t have enough space for ARC you would see most requests served from SSD. On my graph above file walker will probably display sustained 4000 IOPS load – and that’s OK, our goal to speed up small data transfers compared to HDD – and SSDs do that by multiple orders of magnitudes.
So, it appears ZFS is a best filesystem to host storagenode data from the perspective of that chosen metric: to reduce the time to first byte to a fraction of transfer time. All you need is add a small SSD (64G?) to your huge HDD(20T?).
It’s hardly “throwing resources” at the problem as much as “carefully choosing hardware and software configuration most appropriate and cost effective” for a specific problem.
Evidence is in the plots above.
1 Like
The plots you have prepared are for that device with a huge ARC. With a smaller ARC you’d have significant cache contention.
12 TB of node data is, taking the numbers from my nodes, around 32M files. Even if you assume a best case general-purpose metadata of, let say, 300 bytes per file (sorry, I don’t know the actual number for ZFS, I believe this would be a good estimate if you want a general file system with modern semantics like ACLs, extended attributes and such), this is almost 10 GB of metadata to cache. Careful setup of ext4 can go down to ~170 bytes per file while sacrificing some features. So, sorry, but I don’t really believe you can do that in 3 GB. I suspect you have disabled the disk usage estimation and only count the trash file walker, probably after some large removals.
I actually used to think that a carefully formatted ext4 would be good enough. Then my nodes grew to >25 TB on an old machine that has only 16 GB of RAM and cannot be extended. Had to add an SSD at that point for caching metadata, otherwise my drives were absolutely trashed. I spent time on learning ext4 data structures and figured we could do quite a lot better than that.
A purpose-built file system could do the job in ~44 bytes per file overhead, and put that all tightly in a single place on a HDD, making any file scans a breeze even without SSDs. Metadata still could be cached in RAM to have the time-to-first-byte low, sure, why not—but it could focus on caching metadata for actually frequently used files, and cache would not have to be trashed by a file walker process every so often. So, my Microserver gen7 with 16 GB of RAM could then manage ~120 TB worth of nodes while keeping all metadata in RAM. Or, going by the same numbers, an RPi4 with 4 GB of RAM would be enough to have ~30 TB worth of nodes. In both cases reaching the same effects as your ZFS setup. Or, in both cases, manage even larger datasets at the cost of occasional metadata lookup, probably mostly for audits and repairs, as customer traffic tends to have patterns.
Of the general-purpose file systems, ZFS is good enough for nodes given decent hardware specs, as your setup shows. Can’t disagree with this statement. So is ext4 though, given the same setup: large amount of RAM for disk cache or a standard block-level SSD cache.
2 Likes
Additionally one thing needs to be taken into account: We are talking about a single satellite provider.
Now with Storj shifting to make satellite providing available for everyone, noone can say to how many satellites a node is subscribed in the future.
And every satellite provider might have his own policies and issues he has to deal with.
So maybe a setting that works well with Storj managed provider might be a problem with another provider. I just mention when Storj had turned off garbage collection for a while and when they turned it back on the nodes got hammered like crazy with trash tasks.
Imagine such a scenario if your node has to keep providing data to clients from another satellite. That will be fun.
So on the node level the implementations where a SNO cannot influence what a satellite provider is doing and what load from what task can be expected, it must use as low resources as possible. And what we see here is certainly not.