well for me running zfs and a few other things it can load my cpu’s quite a bit… so i like to have plenty of processing to spare so it doesn’t slow down my system… ofc this is for way more than just storagenodes… but my current node migration is using like 20-40% of cpu capacity and because i f’ed up the first copy and picked 16k recordsize, it forced me to copy it twice, so i’m closing on a 10 day data transfer… yay… not going to go back to small recordsizes again any time soon…
Something bothers me though, we’re basically saying that considering the nature of how Storj nodes work, adding more and more nodes to a single machine will not increase significantly the amount of CPU needs because all the work requested by the network will stay the same, scattered amongst all the nodes.
At some point it would become an issue of course, but as an example: considering the above, maybe running 32 nodes on a RPi 4B (4 cores, 4GB RAM) wouldn’t be an issue CPU wise.
Then why do StorjLabs specifically state in their TOS (Node Operator Terms & Conditions) that:
4.1.4.1. Have a minimum of one (1) hard drive and one (1) processor core dedicated to each Storage Node;
?
- Considering how the processing power can be completely different from one CPU to another, I don’t get how this term is useful - if one doesn’t give enough power to their nodes, they’re simply gonna lose a lot of races, that’s it.
- Basically, if I’m running 5 nodes on a 4 core CPU, I’m violating these TOS, right? Then what? Can I get disqualified because of that?
Sure but in this case the node would become unresponsive and it would be fair to suspend it I guess. Or it would simply lose a lot of races, so it wouldn’t earn much. Seems to me like if one were to steal too much CPU power from their nodes, they would simply not be able to have a proper experience as SNO.
So maybe StorjLabs could review these terms to state that Nodes should have available CPU cycles at any time… ? Allocating one core to one node really doesn’t sound necessary. On my RPi 4B (which is pretty weak machine), the CPU is 80~90% idle most of the time, or waiting for disks.
1 Like
There is a difference between what gets you disqualified and what’s in the ToS. The only thing that gets you disqualified or suspended is bad performance of your node on the audit and uptime metrics.
ToS are often written base on the CYA principle. It helps give Storj Labs the right to suspend you and gives them something to point to. In general I think the level of CYA in the Storj Labs ToS is actually pretty minimal. But that is still generally the the goal of such documents. I seriously wouldn’t worry too much about it. If you follow the spirit of the ToS, nobody is going to come after you for it. In generally the golden rule of “don’t be an asshole” should suffice. (This is not legal advise, lol)
But yeah, run a good faith and healthy node and don’t try to cheat the system. Follow that and your node will prosper. Don’t follow that and then you’re going to have to worry about the ToS.
6 Likes
![]()
Alright, you’re probably right! ![]()
1 Like
I am currently testing this by running 10 nodes on a raspberry pi 4 4gb.
The disk activity is quite painful after a reboot but the cpu are not in pain.
I could go to 20 if it would help resolve anything?
2 Likes
Thats very nice ![]()
What is total size of those 10, and how much is filled up at the moment?
1 Like
4.5g 1.5g .8g .55g .5 and bits .2 - .05
plenty of space on the drives yet!
edit: whoops showing my age I mean tb not gb…
2 Likes
it would suck to run out of processing capacity on a host… ofc isn’t the real question here then… how much is the ratio… between running say 40 containers with 500gb nodes and running 1 x 20tb node… or something like that…
is there infact something to be saved or is it just an illusion we attribute to the system…
ofc testing that exactly would require a extended period of like months and two perfectly similar system, on two subnets running the same OS and settings…
ofc a shorter test time might also provide useful data… but still need two systems or vm’s i guess could do… and two subnets for data to be evenly distributed
what does one really pay for running all the containers… i suppose that data can be gotten from other sources also, and it’s most likely not much…
then it comes down to if the storagenode requires more depending on stored data or if its the same… and really if one doesn’t make a million containers with small nodes, then i doubt it’s a real problem…
and when the cpu is loaded one will start to see cancelled uploads or downloads… not sure how bad it is… but i can see a difference when i turn my vm’s on… but it may be more down to the pool latency because the vm’s share the pool with the storagenode
but i’m pretty sure there is at the very least 0.5% drop even when i isolate the vm vhdd’s on another pool
not sure if thats the maximum extend of it, i suppose i could try and run some cpu load tests.
1 Like
apperently that did nothing…
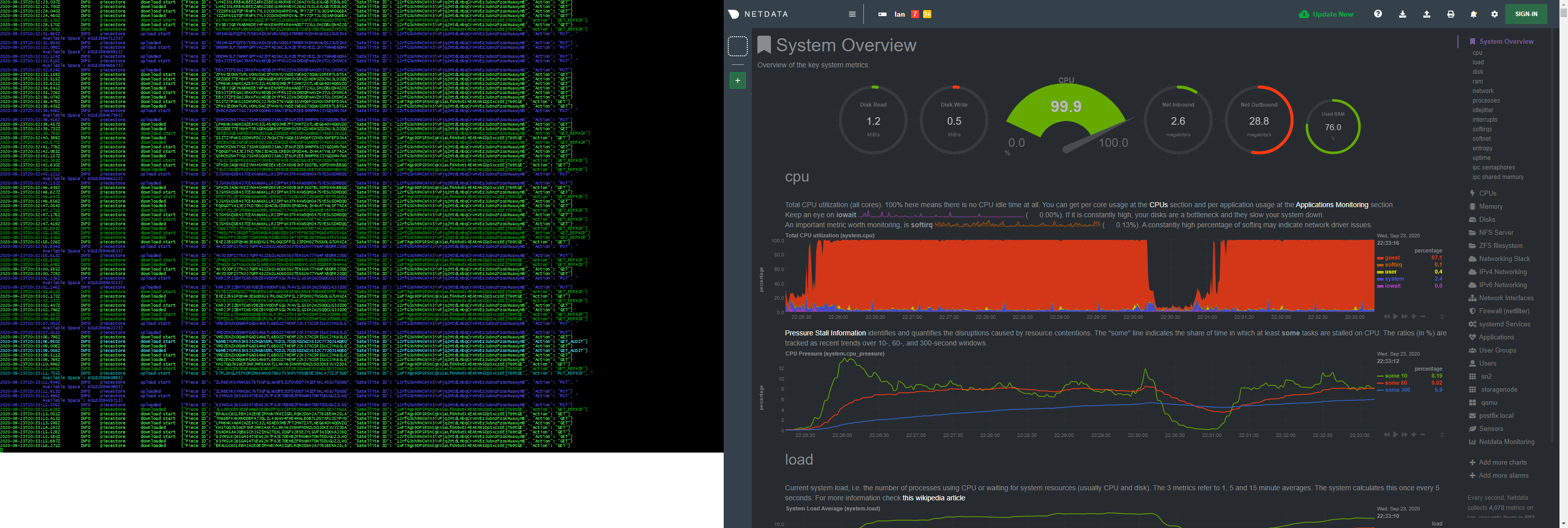
ofc that doesn’t mean that running multiple vm’s or containers doesn’t have different effects on cpu latency… but clearly pegging the cpu utilization didn’t have enough effect to even loose a race…
might be down to that it would always be a 50/50 split between kvm and docker…
1 Like
It will be disqualified instead. 4 failed attempts to audit the same piece with 5 minutes timeout each will considered as failed audit. Too much such failures in a row - your node will be disqualified.
1 Like
maybe it’s really max capacity in relation to processing power…
granted i do use zfs so i see a lot more overhead from dealing with the data, it wouldn’t surprise me if in my case it wouldn’t matter much if i split it all into multiple nodes or ran a single one, since it might be the overhead of managing the data that will get be the final limitation of my server…
but again having many nodes would also mean that if there ever was a like say 100% increase in activity or cpu use for whatever reason, like say during boot of the storagenode / 's
then one might quickly run into some sort of issues…
which kinda makes a good argument for the server actually sharing multiple tasks aside from storagenodes, so that there can be plenty of cpu time, and if even if the other vm’s are pulling max, it will always get like 25% or 20% or whatever for the nodes, but in almost all cases there would be much more…
but generally i would just say… don’t peg the cpu, i wouldn’t even feel comfy getting past 50% utilization when running 24/7 utilization, because imo it doesn’t leave much room for error…
i think my avg is like 1% or 2% utilization with a 14tb node… ofc i got dual xeon’s even if they are old junk with a meek total of 16 threads, i would be very interested to see what the minimum cpu somebody has a sizable node running on… and what their avg utilization and peak utilization looks like
but yeah i think atleast when running zfs, the limitation will be the size of the storagenode in relation to the processing, rather than the number of nodes… sure the number of nodes might offset the result by some amount… but i seriously doubt it will be more that 1/3
1 Like