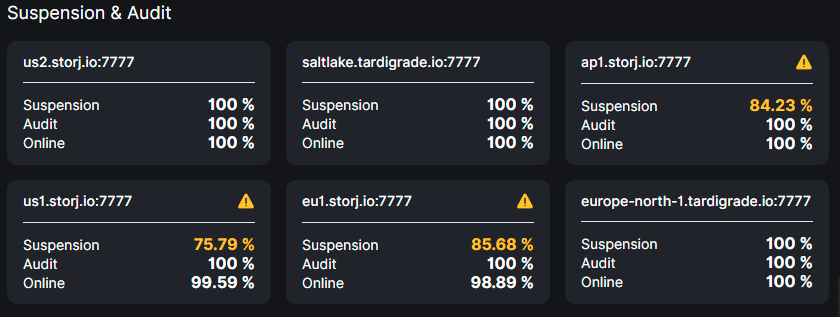
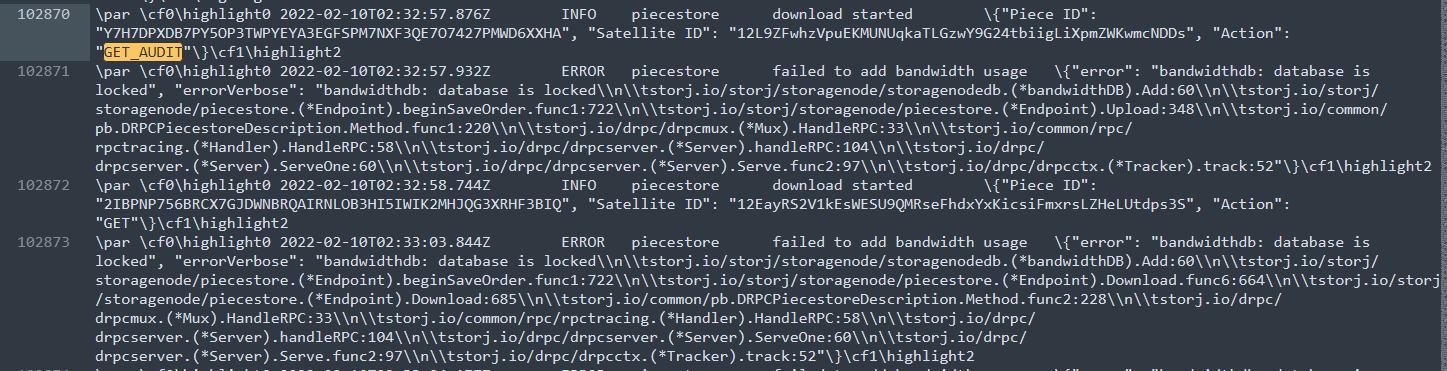
3 months isn’t really that long for a node, and doesn’t really prove that it works reliably or not.
also the 2TB max drive size was to do with a maximum number of sectors that could be allocated, if something doesn’t support bigger than 2TB drives you can only bypass it by using larger sectors, because the limit was a max number of sectors.
ofc then you run into the issue that most stuff that old will most likely not support 4kn hdd.
also keep in mind that if your control is just working as a HBA then it will be the OS which defines the max HDD sector allocation.
or something like that.
i initially also tried to run my storagenode over SMB… can’t remember if it would work or not… i think it ran just fine… but due to the database issues i wouldn’t want to take the chance with something that is as long term as running a storagenode…
since it has to be stable and working for years without issues to really see optimal returns.
Yeah, that question could have been more specific. My bad. I meant would that 100% prevent corruption caused by smb?
I don’t think there is any way around the lock contention and some of the things you mentioned could actually make that worse, because it slows things down.
I guess it doesn’t matter much because when your node gets a bit more data and gets busier, it will lead to problems even if it doesn’t corrupt the DB’s. So long term it isn’t viable anyway.
Just as using 10 year old hardware, it can fail any time.
Right now, given that it is now possible to have databases and blobs on separate locations, I see nothing wrong with using SMB as blob storage. The worst that will happen is a slow file walker.
Even with SMB, what SQLite developers say about networked storage can be mitigated in case of Storj. Their warnings are mostly about concurrent access from different machines, file locking and file paths. The first one does not apply to storage nodes, the second and third can be mitigated with a conservative approach to configuration. The only drawback left is then speed, which is what actually makes running node databases undesirable.
Well for now everything is working. Ideally I would like to have the container and the storage all on one machine without having to use smb, but for some reason the docker container for storagenode-v3 alone was using 95% of the cpu out of the blue. A six core xeon silver with hyper threading shouldn’t be getting the crap kicked out of it from one docker. Ever since moving the docker to my dual xeon server everything has been working except for this one event which seems more like there was a satellite issue or something cause I checked everything recommended and everything passed. It is either that or during the parity check it was too much. Once I get the cpu upgraded in my main server I would move the docker container back to the same machine but for now smb is working perfectly
If you plan to keep using SMB for now, I recommend to at least move the db’s to the system running the node. You can find instructions here: How to move DB’s to SSD on Docker
The post is about moving to SSD, but could be used to move them to a local HDD too.
Using the db’s over SMB has caused a lot of problems for nodes. At the least the locking issue is just going to get worse the more data you get.
You’re right, it shouldn’t. This is not normal behavior. People are running nodes without problems on raspberry pi’s.
Since you mention a running parity check, it’s possible that a combination of the storj file walker process or garbage collection with that parity check led to high IO. The 95% CPU could have been just IO wait. In that case upgrading the CPU wouldn’t do anything. But even without that I’m certain a 6 core xeon silver is already overkill for a storage node. If you want a new CPU for other reasons then it can’t hurt, but buying a new one for Storj wouldn’t be worth it.
This processor was never meant to be the permanent solution for this server so upgrading it would be more than just for storj. During the parity check that specific disk was not being utilized fully and the high cpu usage started happening 2 days before the parity check started. I started moving other containers to the dual xeon server first but the cpu usage was not going down so it came down to the only other process then the base os was storj, and when I moved that over the cpu usage dropped to 3%. While on the dual xeon while only storj is running cpu usages is around 8%.
That sure is strange behavior. If you find out more about why that may have happened I’d be curious to know. Hopefully the CPU upgrade will do the trick.
3 months ago I deploy a new node. All was working ok, the last update bring an error on the dashboard. I Replaced “-p 28967:28967” by “-p 28967:28967/tcp -p 28967:28967/udp” fixed the issue. Now QUIC is ok. I’m not sure if it is just me, but is harder and harder to keep the node.
This morning I got the message node was suspended. Login stop/start the node.