It certainly doesn’t need it. However, I was imagining what it would be like to be a large SNO… with 100+ nodes. Knowing the pain of 9-months-holdback, and say an average of 2-3 years to fill 10-20TB HDDs (ignoring recent test ingress)…
…at some point would you want some nodes: perhaps just the full ones: to have some redundancy? Just to avoid maybe losing a full 20TB node and having to fill it again?
I can imagine deciding that RAIDZ1 for every 8 HDDS (so capacity of 7) would be worth it to protect full nodes. They’d be lower-IO anyways if they were rejecting ingress most of the time.
Don’t mean to derail the ZFS discussion. I can just see that at some point a SNO may decide to give up some capacity to protect all the time they spent growing nodes.
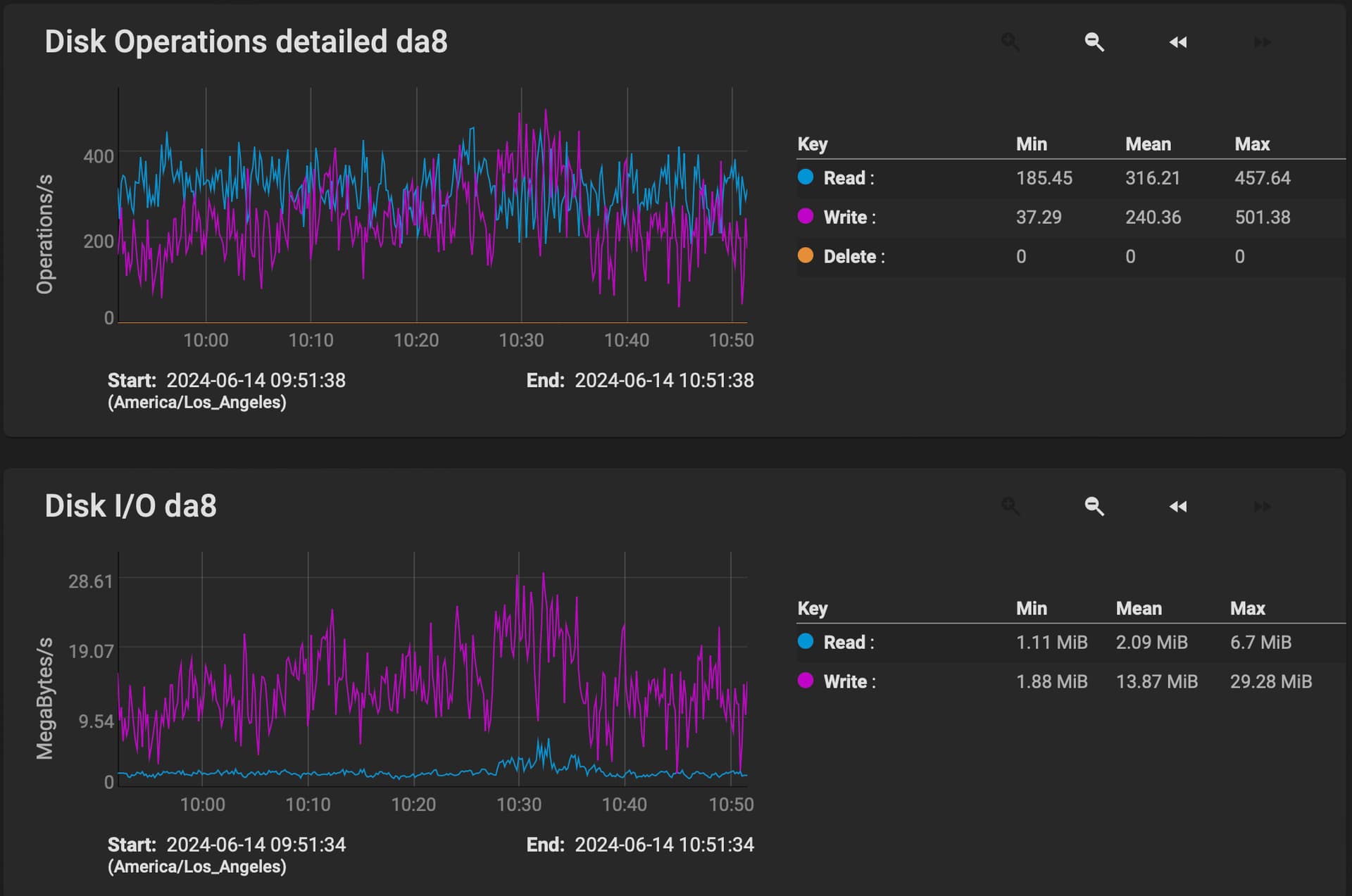
The smallest raidz I can think of would be a 2+1 setup and than maybe a lot of them in parallel. It still means you get just 1/3 of the IOPs you would get from 3 single drive setups. And for a storage node that slowdown should get noticable for garbage collection runtime and other stuff. And this is the lowest IOPs impact I can think of. If you add more drives to one array it will be even worse.
Plus you don’t have the full capacity available.
Plus single drive disks can run even months after they start showing read and write errors. In a single drive setup you can risk keeping them running until the node gets disqualified.
I don’t understand the question. Do you mean zpool create SN8 /dev/disk/by-id/... ?
What I also did was adding a 8 TB sata SSD and split that into 8 1 TB partitions. Now each drive has an l2arc cache on a single SSD. This should also work with smaller SSDs. Like 20GB for a 20TB drive. You can configure that this cache is used for metadata only. It will boost filewalker performance a lot. You can do the same with RAM but the RAM cache will take hours to fill again after a restart. The SSD metadata cache will allow you to finish the filewalker in a short time even after a restart.
Yes. So you have one pool per disk. In a 48+ disks system you need to create 48+ pools with 48+ partition for L2Arc. Nothing impossible but not clean and I want to use special dev (after reading @arrogantrabbit experience) not L2Arc.
The hit ratio might be a bit misleading in my case because I am storing more than just metadata in the cache. Still 50% means less IOPs on the disks. It is 50% of the arc misses. So almost no reads at all. The big advantage of having some kind of l2arc is that I can restart my server without the big filewalker penalty I would otherwise have.
You mean record size? Leave it at default, and keep compression on. This will result in a most efficient space utilization. On storagenode datasets I’m seeing 1.18-1.28 compression ratio.
It depends on file size distribution in those 10. This is what I saw empirically:
When I allowed files smaller than 16k to go to 400GB special device, at about 20TB worth of storagenode data the special device filled up.
I have disabled sending small files to special device, rebalanced the datasets (zfs send | zfs recevie) and now the same 400GB seem to be sufficient to hold metadata for about 30TB worth of node data with room to spare.
I don’t do anything special for storj. I have one pool for everything. The pool contains three raidz1 vdevs, each of 4 drives. It has special device (mirror of two SSDs), and recently I added L2ARC because I just had an unused 500GB SSD.
One of my servers runs TrueNAS Core and all the nodes on that server run on single disk pools. Works perfectly fine, you obviously just don’t have redundancy. They’re all mounted to a single jail with each node running in separate tmux sessions. Just make sure you delete the scrub tasks that are automatically created for each ‘pool’ as there’s no need for them.
Having a SSD as the special metadata device lets it hold pretty much everything the filewalkers care about (and even the small files)… while leaving the HDD with the medium+large files that it works better with. Plus if you have a lot of RAM the ZFS ARC will help with everything. It’s a clever config!
I’d get my systems to 128GB RAM first though: reboots are rare and memory trumps all!
I have 128, and it seems it’s overkill. 32 was definitely not sufficient. 64 is probably optimum.
And for storing small files on the special device I totally agree it’s definitely the way to go. I however ran out of space on 400GB special device and had to limit it to just metadata.
But now that you mentioned it again in such a concise form — I’m thinking to get a pair of 2TB p3600 off eBay (they are under $100) and migrate special device with small files there.
Personal preference really. I have a python program that manages nodes across multiple servers and that’s just what I chose to use for simplicity. Create a new tmux session with the storagenode run command… that’s it. No need for more than one jail.
tell zsh to run a command to start storagenode with all necessary arguments
redirect output to log_file &>
background the process &
get its pid $!
print it to stdout
disown it
exit.
As a result, only storagenode process is left running, and you have its pid to send commands to it.
Separate problem there is no way to tell storagenode that you want to rotate the logs, and if it crashes – to restart it. So you would want to run it under daemon utility anyway. And if you do that – might as well do it properly via rc.d.
You may run a node any size. Just make sure that you do not use the same pool for more than a one node (otherwise it will be the same as running multiple nodes on the same disk), and do not use bypass methods for /24 rule.