Hi again
I come with some more information… but even more confused than before 
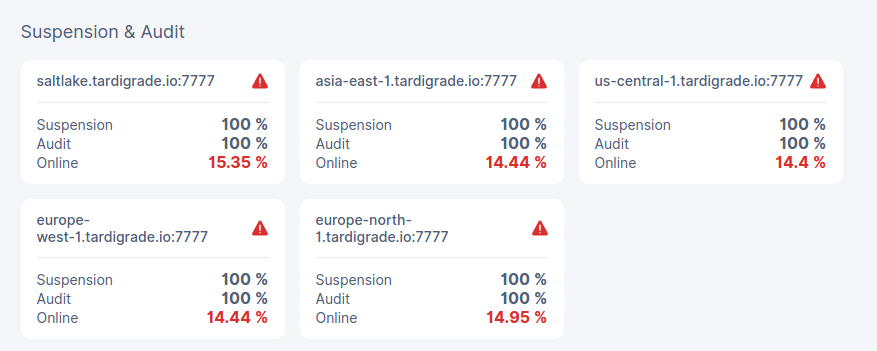
After one day left it to work, dashboard shows “offline” status.
But the logs show that I have healthy traffic anytime I look. Is it offline but exchanging packets like: ?
2020-12-08T16:56:28.933Z INFO piecestore downloaded {"Piece ID": "A727EZTULHDASQPJ35B4Q4VZY7AYNNRTWENUTXWRCHK37P6IAEYQ", "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Action": "GET"}
At the same time I find some errors if I try command:
sudo docker logs storagenode 2>&1 | grep "error"
Like, for instance, this one:
2020-12-06T01:25:38.884Z ERROR piecestore upload failed {"Piece ID": "UBBHFYXPBTP7EGLFALVBGYHXGNF7P33RRXDIDQNHYI6CKWAXRSXA", "Satellite ID": "12rfG3sh9NCWiX3ivPjq2HtdLmbqCrvHVEzJubnzFzosMuawymB", "Action": "PUT_REPAIR", "error": "tls: use of closed connection", "errorVerbose": "tls: use of closed connection\n\tstorj.io/drpc/drpcstream.(*Stream).RawFlush:287\n\tstorj.io/drpc/drpcstream.(*Stream).MsgSend:325\n\tstorj.io/common/pb.(*drpcPiecestoreUploadStream).SendAndClose:1064\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Upload.func6:407\n\tstorj.io/common/rpc/rpctimeout.Run.func1:22"}
or
2020-12-06T11:19:27.988Z ERROR piecestore download failed {"Piece ID": "DKXXYPTSOKOKZBU66PVT4YIPVEGGKAGELTKHXDIAXKMTU7MTU6EQ", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "GET", "error": "write tcp ((some-ip)):28967->((some-other-ip)):37192: use of closed network connection", "errorVerbose": "write tcp ((some-ip)):28967->((some-other-ip)):37192: use of closed network connection\n\tstorj.io/drpc/drpcstream.(*Stream).pollWrite:228\n\tstorj.io/drpc/drpcwire.SplitN:29\n\tstorj.io/drpc/drpcstream.(*Stream).RawWrite:276\n\tstorj.io/drpc/drpcstream.(*Stream).MsgSend:322\n\tstorj.io/common/pb.(*drpcPiecestoreDownloadStream).Send:1089\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download.func5.1:580\n\tstorj.io/common/rpc/rpctimeout.Run.func1:22"}
In general, during this year, node seems to be offline, then I restart, but indicators are always near 100%… really it doen’t make any sense to me.
EDIT: 10min after what I told you, dashboard shows “online” ¿?
EDIT2: Now I see some suspension notification…