Now I see, you just argue here to flex with your numbers. Of course it makes sense to you to use RAID when you have 30TB free space and another 40TB of disks laying around unused. But it’s just wrong to generalize your case and say it applies to Average Joe SNO who only has a few old hard disks laying around and wants to maximize profit.
One more point, what happens when all the bays in your server are full and and all space is filled with date. Good luck replacing all hard disks with bigger ones. With one node per hard disk you just replace them one by one as they fill. You need to replace all of them before you can grow your usable space.
Edit: cdhowie’s analogy with home insurance fits quite well. I personally will never in my life take out an insurance for something which is manageable to replace. In the long run you save money by not having insurance. In my last job we had ~30 blackberries and paid an amount equivalent of buying 4 new blackberries each month. We had to replace at most 1 of them per month due to one breaking, getting flushed down the toilet, … After taking these numbers to management we quickly cancelled the insurance for all phones.
I agree with everything you said, but this wasn’t necessary. If @Krey wanted to flex it would have been mentioned much earlier in the conversation and this simply gives context to his situation. Which you seem to have actually picked up on in the rest of your response.
I’m left to conclude that based on this @Krey is indeed not taking the cost of purchase of HDD’s into account. So… yeah, quite obviously if your redundancy is free, then it’s better to use it. End of discussion. For anyone who doesn’t have more storage than they know what to do with, I stand by my previous post.
As for the insurance argument, I completely agree. (Pro tip: open a savings account and whenever someone tries to sell you purchase insurance, simply ask what the premium is and pay that amount into that savings account instead. Do that a few times and it will have more than enough money to cover the small stuff.)
But insurance companies by definition make money, so it averages out to a net loss for customers. This isn’t necessarily the case with RAID. In fact in most data projects it’s completely flipped, which is why RAID is pretty much the default for most things. So doing the calculation is warranted. But if you actually sit down and do it, it turns out the insurance comparison applies to Storj, because the cost of protection is indeed higher than the average cost of loss. (if you take the cost of HDD’s into account)
My best two nodes hold 343.82$ and 310.10$. Add to this the drop-down income for the period of growth of new nodes to 5-10TB and it cost and you get thousands i’am talking about.
My earnings never depend of count hdds i have. I will connect as many disks as the Storj can fill with my channels. And so do many. Look in the relevant topics, petabyte for the farmer is not the limit but the near-future goal.
You maybe know from my scripts, I have been engaged in automation of these processes and monitoring for a long time.
I never say and scale down to this level. I talk about professional SNOs who stay here to earn money.
RAIDs i suggest to all farmers include newbies, right. But my digits it is answer to one concrete message about my tone.
With 5 disk which i usually operate (RAIDZ 4+1) about the same but much faster. These are in-home where space is limited. In the country, I just add another case with 16-24 hot-swaps bays.
Nope… Divide those numbers by the number of HDDs in your array, since all other HDDs/nodes would still be up and running. Also why are you picking the most profitable ones instead of just an average? Seems like you’re intentionally skewing the numbers.
And evidently some they can’t fill as well. Btw, do you have a contact for those free HDDs you’re getting?
Can you explain how these two statements don’t contradict? Because it seems like they do.
Why i must divide? One node per hdd you prefer. This means that 343.82$ one 8TB hdd, and 310.10$ another one 8TB hdd. If i loose 2 hdd in this case i loose this nodes. and proportional income from this on 5-10 months or more.
In my case each of it node stay on 5x3TB disk (total 5 disk array more cheaper at all and more times faster). I loose two disk in past month and 3 for year. (last was replaced some days ago). I loose nothing.
It may seem to you that I play the numbers of disk failure. This is not true. The last two times when I bought myself seagate, all 5 out of 5 bought failed. I know a person who has failed out all of 30+
This is for ST3000DM001. Other models and other brands more reliable and failed rarely, but when you have dozens of spindles, the failure of the drives is so ordinary.
For house i gut external 8TB WD USB drives from amazon for 115$ each.
For country i bye old enterprise 3TB+ SAS drives from ebay.
I mean that RAID more profitable in long term even for beginners. For pro, near-industrial SNOs this is must have. For proSNOs where one exception - when you have dozen free public IP networks around a world.
You forget about Merphy’s law. And of course i count risks at its maximums.
My averages just make more dust. I prepared many nodes for new locations. I growing.
But if you want i can post my relative averages from my script. But it seems to me that this topic, in addition to my desire, turns into a topic about me.
You must divide because the alternative with the sand hardware would be to run 5 nodes on a 3TB disk each. Those nodes would share the same traffic and thus hold 1/5th of the data and have 1/5th of the held back amount. If you lose 1 HDD you only use 1/5th of the amounts you mention. Not all of it, the other nodes would work just fine still. And of course you also still have 3TB of additional space to share.
You may have lost nothing so far, but raidz1 isn’t perfect. There is still a non-0 failure rate. There is a reason raidz2 and raidz3 exist. Both of which also have non-0 failure rates. And while that risk is much smaller, the impact of that loss will be much larger, because you’re losing 5x as much data and held back amount.
That thing was a disaster. Leading to class action lawsuits. Yes I think you’re cherry picking the wrong examples again. But this is not at all an argument for raidz1. An array with those disks would still have a significant failure rate, especially if the HDDs were bought in the same batch. And it would take all data with them instead of just the disks that failed.
Yes, but that same scale means it also averages out. Especially if you mix drive models to spread the risk. And currently that averages out below 2% annual failure rate.
Don’t just claim this. Prove it! Show your calculations.
Alternative to what? Nodes are not divided, there is no partial exit. They grow with those who earn money and stop where the place ends with those who walk out with home NAS’es. I don’t want to offend anyone, but this is a different calculation and different priorities. And that’s why we don’t understand each other.
Of course you’re right. I have 8 + 2 arrays. But here comes the factor of the murderous storj little pieces who kill any spindles arrays. There are other factors on how to make this work, but it is beyond the scope and not just the topics of this whole forum.
You theorize again. My array on them survived all without loss.
But not for storj nodes. Where some satellites are introduced and others are shutting down and after more than a year I have frozen more than I received.
Your calculations are superficial and completely ignore the specifics of the storj. You count as backblaze, i count as storj SNO.
I already said everything I wanted. Now let everyone decide for himself. I think it’s much more important for a beginner to keep his only one node until it get 50% escrow back than me.
Compared to your calculations that are so far still non-existent despite me asking several times for them. I think I’m going with the data that is actually available. You have yet to show how the storj use case is different from backblaze or any other widely available stats on disk failure rates for that matter.
You say NAS is different without any explanation why. Yet you still tell home users to use RAID despite also arguing that your scenario doesn’t apply to them.
You say I theorize, but I’ve literally shown you calculations. You haven’t provided any supporting evidence for your claims at all. And do you seriously think that not having had a failed array so far means they don’t fail at all? I haven’t had a failed HDD since I started my node. That’s a sample of 9 HDDs over more than a year. Should I also conclude that HDDs don’t fail?
I’m going to assume this is partially a language barrier. I’m comparing your approach with the suggested approach. So 1 node on raidz1 vs 5 nodes on the individual disks. You claim you would lose all income if 1 HDD fails. That’s simply not true because in the individual node setup you would only lose 1 node out of 5. So only 1/5th is lost. (That’s 1/5th you wouldn’t have had to begin with if you sacrificed that HDD to redundancy)
And we don’t understand each other because you don’t explain your calculations. You simply say they are different, without saying why they would be. And I’m sorry… But RAID is RAID wether you run it in a server case or a NAS. There is no difference for the purposes of storj. I’m not easily offended, but I do get a little annoyed by completely unsubstantiated claims. It may very well be that you know better than me and I want to learn. So please tell me where my calculations are wrong and show me the alternatives that show why your setup is more profitable. But don’t tell me I’m just a puny little NAS user who simply doesn’t understand. That’s not gonna fly. As long as you don’t counter with facts and calculations, I have the data on my side.
in frequency does not differ, differs in consequences
Here I am talking about two different scenarios at the same time. Are you answer for only one?
I have small in-house NAS and many servers locally and in-cloud.
I do not consider your calculations for calculations (And I pointed out to you the reason why). I could make mine, but at the level at which I do it it will take too much of my time, probably for nothing. Therefore, I will not do them, just consider everything that I said with my personal opinion confirmed only by my personal experience.
Of course no. But it radically changes the likelihood of getting an escrow by average SNO. And it (+ backed SSDs to win the race for pieces) is reasonable minimum for my current earnings.
This is not a language barrier, this is a mistake in understanding. I talking with you about node to node.
When you replace one big node with 5 smaller nodes, you interfere with many other things, starting from the network and processor performance on hash operations.
Five nodes will consume a lot more resources than one big one, even if they all hang on the same IP. I thought it was obvious.
And obviously you are ignoring the cumulative effect when one large node on one channel makes more money than 5 small ones on the same channel.
I talked about two different scenarios. For home NAS’es, let’s say 4 discs and large racks.
I already said this. In you calculations reputations, vettings, volume gain is absent. It does not take into account surge payouts and errors in the labs payments. You cannot compensate for the loss of the old node with the new five. But you ignore it.
Because you never lost them? I didn’t lose either, but since I try to support Russian-language forums and chat rooms, I come across this constantly. And I sincerely hate this statement “one node per disk” And this is why I generally wrote here.
This may be statistically correct, but it is not correct in relation to new farmers. It’s more correct to say that you can start from one disk, but as you accumulate, if you are interested, it tends to arrays with redundancy.
This is not home insurance, you do not need to pay every month for it. Just buy one disc in addition to four at a time to protect your investments and time spent. This five drive is yours. And after you leave the Storj this drive will remain yours.
None of these claims are substantiated. Most of the resource use is related to transfers and since those 5 nodes on the same IP would get the same amount of transfers as a single node would, the resources for that part would be exactly the same. There would be a slight overhead for running multiple storagenode processes, but take a look at monkit stats. Most of the processes that actually use resources are related to transfers and the additional overhead is small. Since you’re talking about rack servers, I doubt you would see any performance issues whatsoever. So what cumulative effect that makes one node more profitable are you talking about? None of this is obvious at all. And let’s not forget that the advise of the people who made this software is to run one node per HDD. So if you’re going against that, the burden of prove is on you to show they are wrong.
Please go back and read the topic I linked. I took a crazy long recovery period of 2 years into account. This statement is absolutely false.
Right, so it’s closer to purchase insurance. There is still a cost attached to that purchase. Have you calculated the time it takes to get a return on that investment on average?
This is not always true. Most of processor resources waste on cryptography and when more storagenode processes run when more on this stuck on limited SSE cores.
Let’s end with this discussion of large resources, you won’t understand me until you try to get into my skin.
I return them a months ago. Now, I’m just taking half of the income from the Storj into the family, and the second I spend on hardware in the expectation that the Storj will work for all rest of the world.
Ok. i go back and reread.
Ok. do it.
Yes, you took into account the escrow but it does not change anything in my arguments. You are considered an abstract constant income. Which has never happened in the history of the Storj, including V2.
For Example: How you calculations takes into account payments for storage in January?
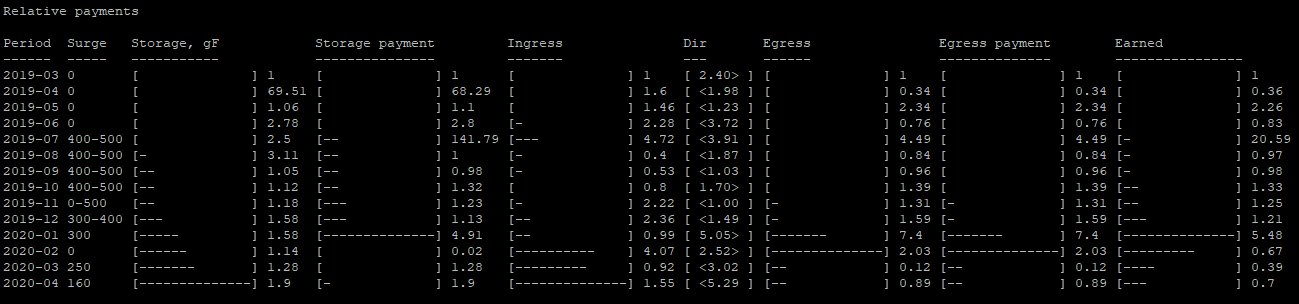
I attach picture from my script. what’s interesting is that no matter who makes it (but near my nodes age) the picture will be similar. It show relative difference for some parameters and storjlabs errors in payments.
if I remove my first node from these statistics, this (relative) picture will not change, but a different graph with absolute values will change, it will change dramatically and I can add the same total earned by adding (more precisely, coping last new nodes) not in the amount of 5 pieces, but what something like 10-20. As you can see, I have calculations, but I can’t formalize them, but everyone can try on their own data. It is open source on Storj/Storj3Monitor at master · Krey81/Storj · GitHub
Which cryptography tasks are you referring to that aren’t related to transfers? I honestly can’t think of any except for identity generation, which is a one time thing.
I’ve been genuinely trying to. The thing is, I’m not going to be convinced by opinion. I need facts and figures to change my mind.
Not just that, aside from the held amount I also took into account the loss of data and related future income from both that data and egress. And I used frankly unrealistically long recovery times just to make sure I’m not using numbers that favor my point of view.
Nope. My calculations merely calculate a relation to the potential maximum income. Meaning it’s completely independent of how high that income will be. Whether the node without any HDD loss would make 1 USD or 1000 USD, the percentage difference in profitability between the two solutions would remain the same.
How do you think the integrity of the pieces in the downloads and audits are checked? It is related to transfers and each minute of node’s working cycle.
That’s my point. That’s tied to the amount of transfers and the total load would be equal between 1 node or 5 nodes on one IP. Besides, most of that takes place on the satellite end for audits. The node just delivers the requested erasure share as is and the satellite checks the integrity. Same for encryption and decryption of pieces, that happens on the uplink side. The storagenode itself requires relatively low computational power to begin with and constraints are mostly on IO during high load. Though again, that would be spread out over 5 nodes, so also not a problem.
You can nitpick that unpredictable fluctuations will impact my calculations. But I’d simply counter with, they would impact your calculations too. The relative percentages would still hold up. So I can’t tell you how much less USD you would make, but I can tell you how much less percent of potential income you would make.
So please instead of trying to pick my calculations apart with arguments that would apply to any calculation, just provide a calculation that shows why your approach is more profitable. The code you linked does not provide that either as it just provides monitoring and not a calculation that compares both approaches. And without that, this discussion is kind of over, because only one side is providing facts and figures. And I’m done arguing with opinion.