Well, I can only tell you that if your node is offline, you don’t fail audits. Just uptime checks. Hence why I asked about the timeout. It’s my guess that your node did respond in some way, but wasn’t able to complete the audit download in time. Hopefully someone from Storj can tell you more.
In the mean time, did you see any additional audit failures since you’re up and running again? That may help narrow it down to only when your NAS was unresponsive.
Morning,
Funny thing is, I’ve never seen ANY errors ever since I moved to Synology.
-
I always used the successrate.sh script (is that still valid to check for failed audits?). This is also from this morning / and so from the last two days (1.5 days)
========== AUDIT =============
Successful: 188
Recoverable failed: 0
Unrecoverable failed: 0
Success Rate Min: 100.000%
Success Rate Max: 100.000%
========== DOWNLOAD ==========
Successful: 10647
Failed: 1
Success Rate: 99.991%
========== UPLOAD ============
Successful: 12566
Rejected: 0
Failed: 202
Acceptance Rate: 100.000%
Success Rate: 98.418%
========== REPAIR DOWNLOAD ===
Successful: 29
Failed: 0
Success Rate: 100.000%
========== REPAIR UPLOAD =====
Successful: 145
Failed: 1
Success Rate: 99.315% -
when I searched for logs this morning this is what I got:
tankmann@Gynology:/ sudo docker logs storagenode 2>&1 | grep AUDIT | grep failed | tail tankmann@Gynology:/ -
Yes my docker / node (whyever) restarts logs every 3 to 4 days, I think there’s a size limit … once the next update comes I’ll put the log to file in the config.yaml
-
I also uploaded the logs from the days of the incident to my dropbox but I didnt find anything weird in the logs, but maybe I’m stupid?

Dropbox - errorlogs - Simplify your life -
Images of the incident
What you can clearly see is that disk utilization / ipos whatsoever dies completely during the swapping period.



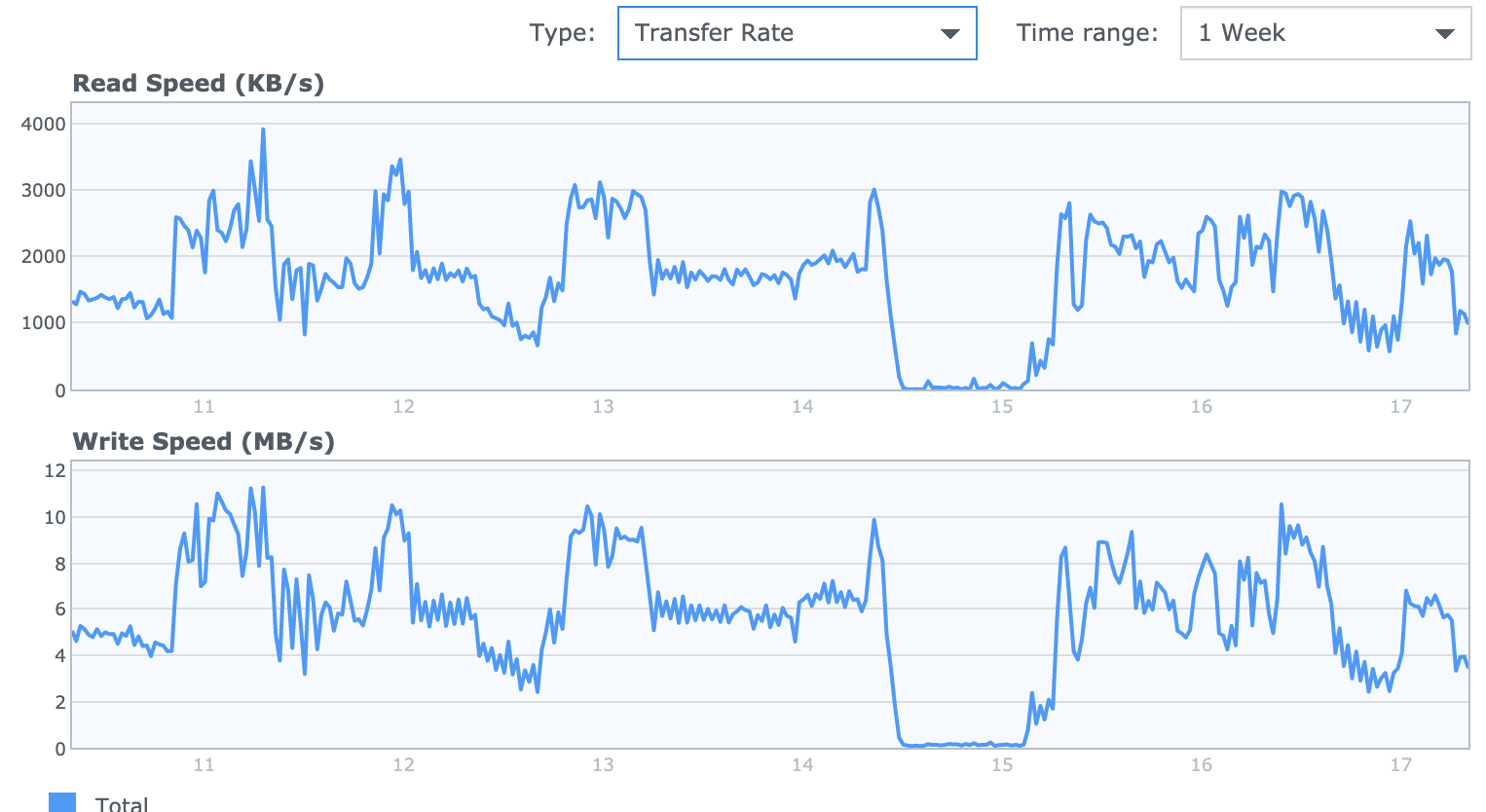

I’m not saying this is not my systems fault but to be honest I’m not convinced that there was for sure data loss?! What do you think?
Since you’ve previously determined the log doesn’t show any errors for the initial problem, I don’t think it’s a good way to check for remaining issues. You can use the dashboard api or the dashj.sh script you use before.
Please check:
- Did the amount of audits increase since last checked?
- Were there no more failed audits since last checked? (you’ll have to subtract success from total and compare to your previous post)
Check 1 will probably not be true for the DQ’ed sats, so focus on the ones that still work. Additionally you could check the scores which should have gone up as well.
Ok great aproach, 1 and 2 is the same if I compare from the above:
118UWp 16298/16127 0.841390 93919/92551 0.991399
118UWp 16404/16233 1.000000 94069/92701 0.998095
Difference audits: 171 vs. 171 (no more audit failures)
Difference uptime: 1368 vs. 1368 (no more uptime failures)
121RTS 345/318 0.598738 48134/47368 1.000000
121RTS 345/318 0.598738 48178/47412 1.000000
Difference audits: 27 vs. 27 (PAUSED SATELLITE // no change)
Difference uptime: 766 vs. 766 (PAUSED SATELLITE // no change even though some more uptime checks)
12EayR 14187/13669 0.598737 101408/100548 1.000000
12EayR 14187/13669 0.598737 101452/100592 1.000000
Difference audits: 518 vs. 518 (PAUSED SATELLITE // no change)
Difference uptime: 860 vs. 860 (PAUSED SATELLITE // no change even though some more uptime checks)
12L9ZF 20395/19852 0.789686 84714/82712 0.991485
12L9ZF 20694/20151 1.000000 85057/83055 0.999729
Difference audits: 543 vs. 543 (no more audit failures)
Difference uptime: 2002 vs. 2002 (no more uptime failures)
So that clearly shows since the swap happened / rebooted synology there was not a single audit issue.
So that’s supporting that in general there’s no issue with my setup right?
I would say that supports the theory that there is no actual data loss, but your node was just temporarily in a state where it was online, but unable to correctly respond to audits. As expected the audit scores are quickly recovering on the remaining satellites.
In my opinion this warrants reinstating the node on the 2 satellites where it was disqualified as I expect its score would recover quickly. But that call is up to Storjlabs. It would help if you could try to find out what caused the memory issues to begin with and prevent repetition. But it seems fairly evident to me this is not an issue of actual data loss.
If accurate… this is a rather serious protocol problem.
I would say it’s pretty much unavoidable. If you allow any way out after the node has received the audit request it can just try to go offline to avoid failing an audit for missing data. I don’t see a way to prevent this kind of cheating while also allowing barely responsive and nearly hung system to still succeed or be allowed to not respond to audits.
If the protocol is designed such that a satellite or customer request data pieces without ensuring that the node is operational… and it’s possible for a node to be “half-operational” … then it’s possible for the Satellite or Customer to erroneously cause reputation damage to a SN. This is just as egregious a problem as a node dropping out of the network in an attempt to avoid being caught without data.
Both sides of the system need to be operational in a trustless way, otherwise, one side of the transaction can “cheat” the other.
There are methods available for ensuring that a data piece has been accepted and stored properly. If the protocol allows for one side to make an unverified claim, then the protocol is fatally flawed since participation in the network requires that both sides of the communication channel know that transactions are ACID.
Got feedback today.
- Unpausing nodes is not possible any longer - hence my node won’t be unpaused
- Paused is also still a wrong wording in the webinterface, will be fixed ‘soon’
I wrote back that in my case I didn’t loose any data which means I should have failed on uptime but not on data loss - even though I understand that my node became unresponsive / didn’t answer properly / swapped which means it’s on my side.
Nevertheless I think data validation should be done somehow ‘differently’ also because I’m holding quite some data on the other satellites which is now not used any more and just drives increased costs for storj.
I just hope (but don’t think so) if new satellites come my node is not getting any penalties - so far both EU satellites are bringing the majority of the test traffic… Can’t wait to see REAL DATA … 
#topicclosed 