From the graph, the growth of disqualified nodes is almost the same as the growth of the total, while EXIT nodes quantity keeps constant.
Obviously, those node owners kill a node and then create a new node immediately. Perhaps, they think those old disks are too small and they want to capture more TEST data by larger disks in time.
Don’t forget that migrating node data files is a painful task. It could takes months .Also, the old disks contained a big portion of uncollected / unpaid garbage. Therefore, they prefer killing the node and start a new healthy one. Graceful exit is not a good option to them because that process requires 30 days. They don’t want to wait.
I don’t think that is a wise behavior. Now the garbage problem almost get fixed. Room is released on old disks. Also, old nodes / disks contain worthy production data, it is much better / stable than those TTL nature.
I was searching for a similar thread before posting, but didn’t find it. Alexey, you can move this topic to there.
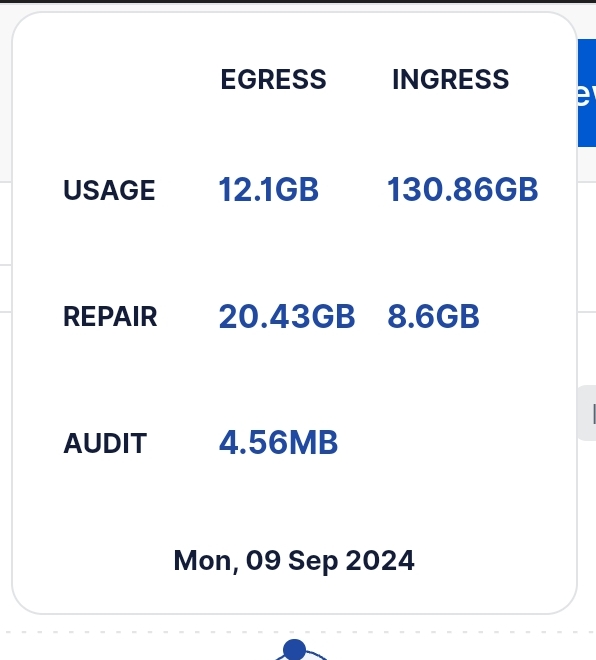
To the topic, I don’t know what the traffic is; I got the numbers yesterday from the payout history page.
Reading the other thread, I see that are speculations about SaltLake. The most repair I see is on my older nodes, on which I GE Saltlake more than an year ago, so no, test data/quitting Saltlake is not the culprit here.
The repair is mainly customer data.
For the 8 month, I GE from Saltlake on almost all my nodes since the begining of the month, but that month seen the biggest repair traffic for me. So again, customer data, not test data.
I wonder if these are the cause:
modified RS numbers, if they are used in production;
async writes or how they were called, that were introduced last months and they speed our nodes significantly, but can loose data when power goes off abruptely.
they are not used in production as far as I know, at least on a regular basis. However, we have a special attribute which can allow us to use a different RS numbers even for the bucket (this feature is not widely available though). Basically we want to have them dynamic, to implement this feature from the whitepaper: