Update: Got’em!
The Windows instances are dedicated to Storj’s node.
Not used by anyone for anything, it’s just an environment for storagenode operation, but Thank You @Dunc4n1d4h0 for input. I tried my best to castrate my Win10’s, and turn off any useless settings. I guess on some instances, its instinct to tirelessly update 24/7 prevailed!
And there i decided to f’kn push that problem off the cliff, and spent some hours today
determinated to find out what’s up, so i watched, and made an observation…
that Win10 PRO version like 1903 or 1909 does not matters,
nor the OS build number,
what matters is what Windows Defender or Microsoft Windows Security is allowed to do,
or break free to do …
i check every node and instance,
for example:
2_5 instance, CPU spike problem occures
w10 PRO 1903
OS build 18362.836
Storagenode 1.95.1
Uptime 42h
(sats online: 100%/100%/99.9%/99.9%)
But few other instances also with same stats, and NOT a single CPU spike problem.
All nodes got min. 99.xx% Online time,
but i saw Uptime someimes 15h, sometimes 42h, only two got like 140h.
So i looked at windows “Event Viewer”.
Not good.
i found that storagenode service restarts sometimes few times a day!
“The Storj V# Storage Node service
terminated unexpectedly. (…) Restart the service”
17.01.2024 02:31 AM
17.01.2024 11:04 PM
19.01.2024 07:43 PM
21.01.2024 03:57 PM
Examples of restarts.
i mean, not a new problem,
2 years ago or so, after arguing in the forum, back and forth about how i noticed this problem started to occur, when no fix, i got tired,
and i set this service just to restart if it crashes
i got 99.9% online stats, but filewalker has hard time to finish its works i see…
So i started to watch.
Aha!
a Windows instance’s CPU goes to 100%, caused by storagenode spike to 70-80%
Couldn’t really find anything correlating in event viewer other than Windows Defender Update just 1 minute before, but that not always happens, and node just restarts too often!
im setting log level to DEBUG now to see more.
i noticed that common settings in nodes where CPU usage spike occures are “debug.addr:127.0.0.1:5998” in configs
so i hashed it for now
hmm seems not helped coz again restart unexpected after 100% CPU usage:
in logs it looks like normal work untill sudden:
2024-01-21T19:34:21+02:00 INFO piecestore download started {"Piece ID": "AT2YZINPJNJ4M3YDJIKVKJALCY6KUVJIGSOGPV3FETS7HSVL2ENA", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET", "Offset": 0, "Size": 9472, "Remote Address": "79.127.201.209:36848"}
2024-01-21T19:34:21+02:00 INFO piecestore download started {"Piece ID": "RTZ47ISKO5TT6ZGITDQJENGX6EVKMJOVMHTBN4QHERHFE6QFY46Q", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "GET", "Offset": 0, "Size": 92416, "Remote Address": "79.127.219.33:52670"}
2024-01-21T19:34:22+02:00 INFO piecestore downloaded {"Piece ID": "RTZ47ISKO5TT6ZGITDQJENGX6EVKMJOVMHTBN4QHERHFE6QFY46Q", "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Action": "GET", "Offset": 0, "Size": 92416, "Remote Address": "79.127.219.33:52670"}
2024-01-21T19:34:23+02:00 INFO piecestore download started {"Piece ID": "OUVBDSSD6JFLHDNNPLHEDMN47LNH7ML225O3GSOSPF7CKMTAI5LA", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET", "Offset": 0, "Size": 14080, "Remote Address": "79.127.220.99:45944"}
2024-01-21T19:34:23+02:00 ERROR services unexpected shutdown of a runner {"name": "piecestore:monitor", "error": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory", "errorVerbose": "piecestore monitor: timed out after 1m0s while verifying writability of storage directory\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2.1:176\n\tstorj.io/common/sync2.(*Cycle).Run:160\n\tstorj.io/storj/storagenode/monitor.(*Service).Run.func2:165\n\tgolang.org/x/sync/errgroup.(*Group).Go.func1:75"}
2024-01-21T19:34:24+02:00 ERROR piecestore download failed {"Piece ID": "BWCU5IJLLYT3ZMFHATXEAAKPNE23DBY6PSJBZ5N5IIR5N3XISWOA", "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Action": "GET", "Offset": 0, "Size": 147456, "Remote Address": "103.214.68.73:59806", "error": "write tcp 10.2.0.2:34887->103.214.68.73:59806: use of closed network connection", "errorVerbose": "write tcp 10.2.0.2:34887->103.214.68.73:59806: use of closed network connection\n\tstorj.io/drpc/drpcstream.(*Stream).rawFlushLocked:401\n\tstorj.io/drpc/drpcstream.(*Stream).MsgSend:462\n\tstorj.io/common/pb.(*drpcPiecestore_DownloadStream).Send:349\n\tstorj.io/storj/storagenode/piecestore.(*Endpoint).sendData.func1:861\n\tstorj.io/common/rpc/rpctimeout.Run.func1:22"}
2024-01-21T19:34:38+02:00 WARN servers service takes long to shutdown {"name": "server"}
2024-01-21T19:34:38+02:00 INFO servers slow shutdown {"stack": "goroutine 944 [running]:\nstorj.io/storj/private/lifecycle.(*Group).logStackTrace.func1()\n\t/go/src/storj.io/storj/private/lifecycle/group.go:107 +0x71\nsync.(*Once).doSlow(0xc004fa1500?, 0xc000396540?)\n\t/usr/local/go/src/sync/once.go:74 +0xbf\nsync.(*Once).Do(...)\n\t/usr/local/go/src/sync/once.go:65\nstorj.io/storj/private/lifecycle.(*Group).logStackTrace(0xc000217eb8?)\n\t/go/src/storj.io/storj/private/lifecycle/group.go:104 +0x3c\nstorj.io/storj/private/lifecycle.(*Group).Run.func1({0x1225658?, 0xc000295f20?})\n\t/go/src/storj.io/storj/private/lifecycle/group.go:77 +0x2a5\nruntime/pprof.Do({0x1225888?, 0xc000074780?}, {{0xc0006bdf00?, 0xc000217fd0?, 0x78bc25?}}, 0xc0006b0f40)\n\t/usr/local/go/src/runtime/pprof/runtime.go:51 +0x9d\ncreated by storj.io/storj/private/lifecycle.(*Group).Run in goroutine 7\n\t/go/src/storj.io/storj/private/lifecycle/group.go:64 +0x509\n\ngoroutine 1 [syscall, 936 minutes, locked to thread]:\nsyscall.SyscallN(0x7ff9481c5f10?, {0xc000095cc0?, 0x3?, 0x0?})\n\t/usr/local/go/src/runtime/syscall_windows.go:544(...God, too long to even post here...)
nothing, beside 10 minutes earlier in events some Windows Defender changin’ some priorities for itself, scheduling itself for some restrat later, crazy stuff!
That theres constant action in the background of a Windows 10, its a f’kn spyware…
For that reason i suspect a Win10 update activity’s are crashing a storagenode.
i restarted the Windows, and got some updates BS popup window, so yeah, M$ definitely had his fingers in it!
I’m looking, im looking, and “Aha, Got it!”
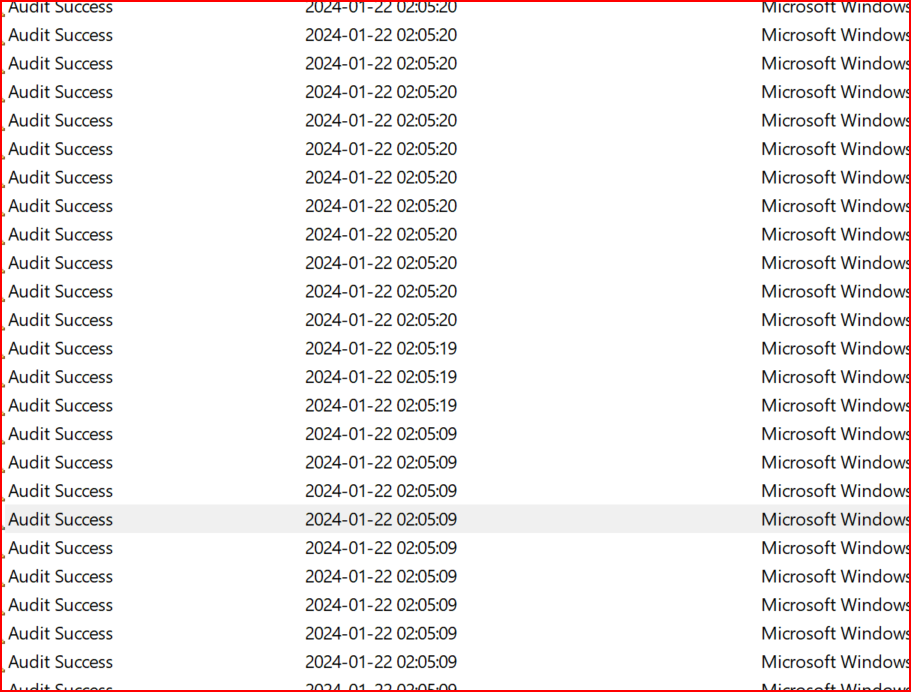
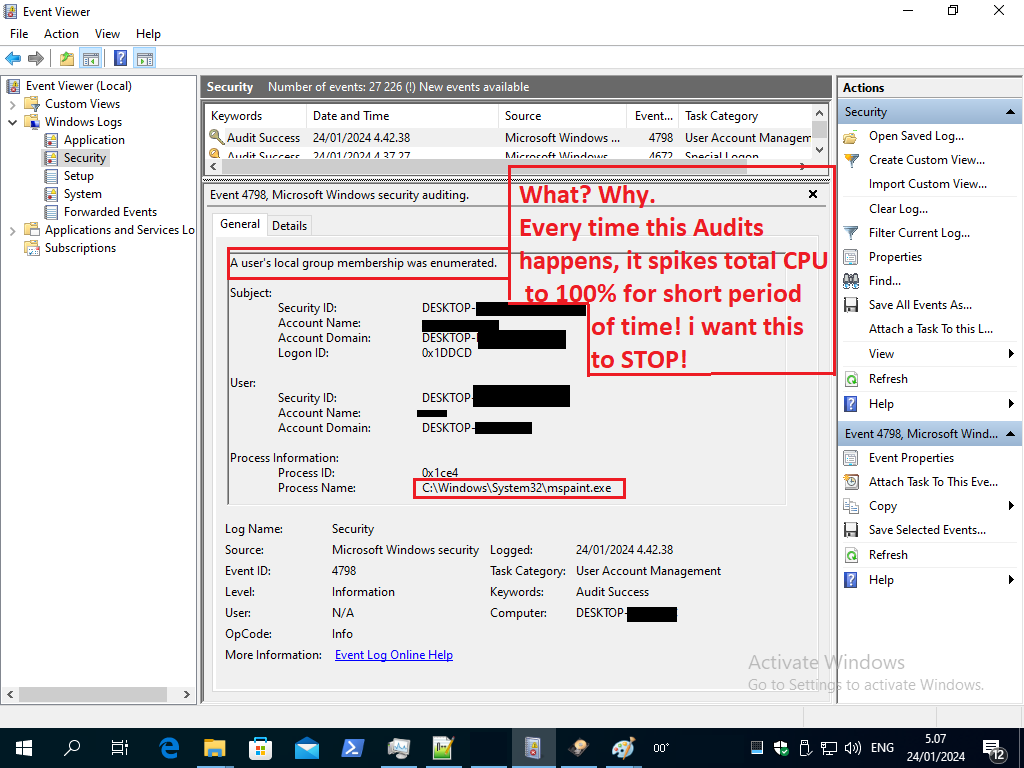
i noticed that in event viewer the amount of “Audit Success” under “Windows logs” folder, are a lot more often, every 5 minuets or so, than under windows instances where problem of CPU spike does not occures, there is a few only Microsoft Windows security audits (with key icon) , and much fewer, every few hours, not minutes!
i kept watching,
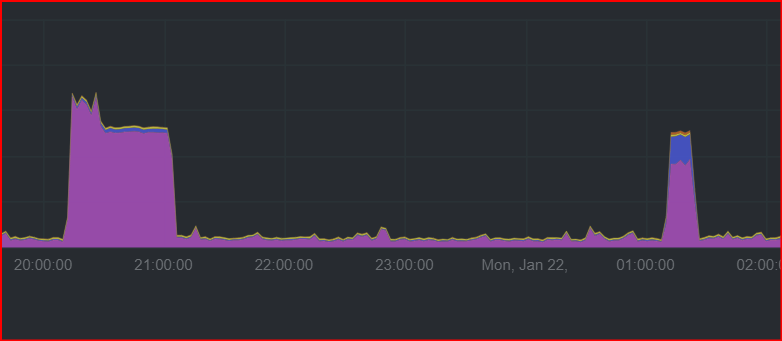
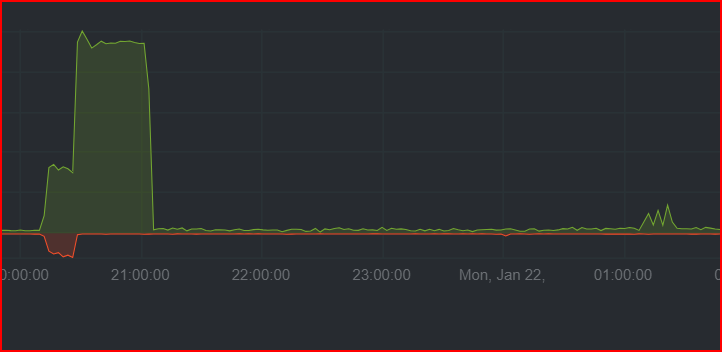
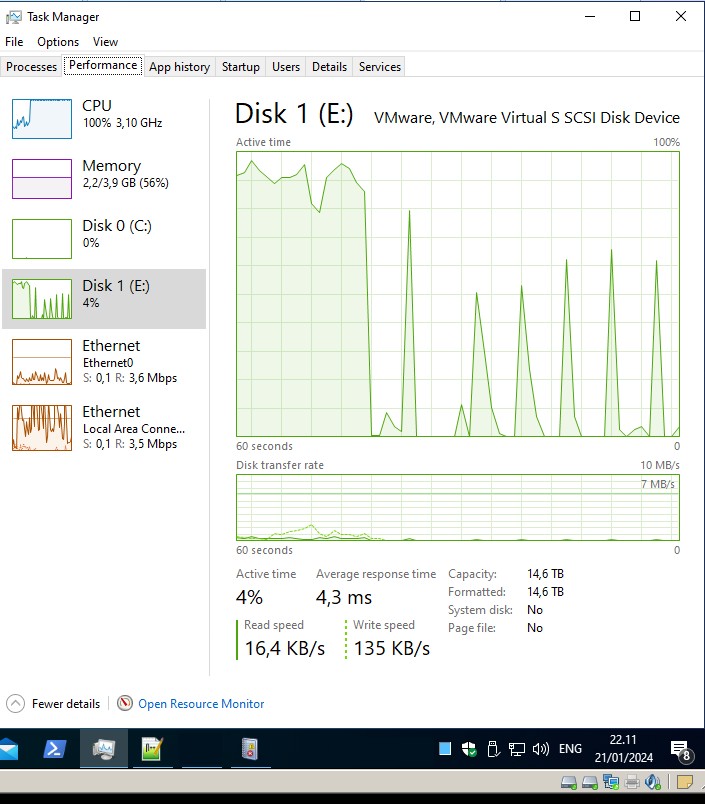
At 22:00, CPU spike 100% for storagenode.exe again,
and HDD activities to 0, for some long 20-30-40sec
did not crashed, but i see how it could!
Event viewer shows again a Microsoft Security Audit Success at 22:00
a 9 of them, and before at 21:50.
Lets wait to 22:10 and see if it will occure again…
nothing untill 22:20
CPU went 100% but for a few sec only,
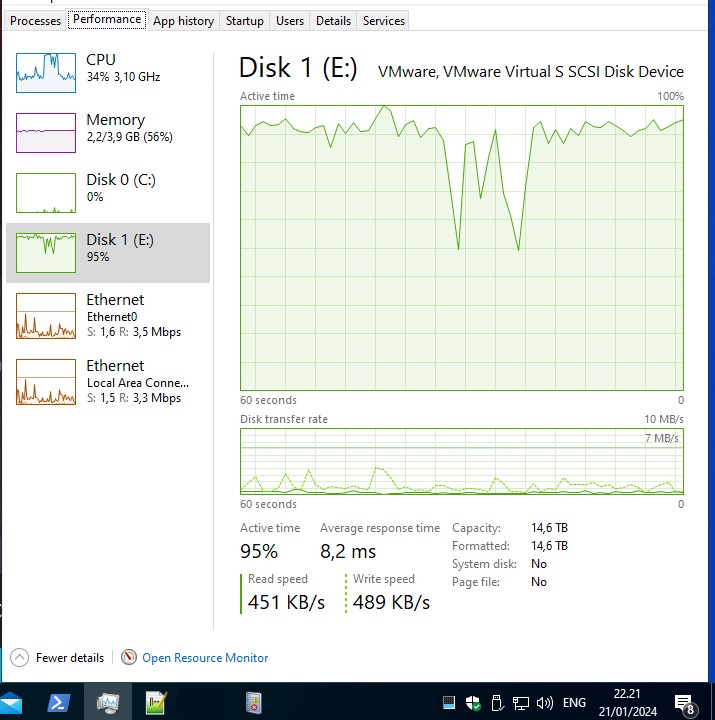
So i waited more.
22:34 couldn’t wait to see, but nothing happened,
i closed the event viewer, and just after that
the CPU finally started to rise

.
and this time, the storagenode didn’t survive that…
after 120 sec as set, it was restarted, but still,
that often restarts, turns into failure all filewalker efforts…
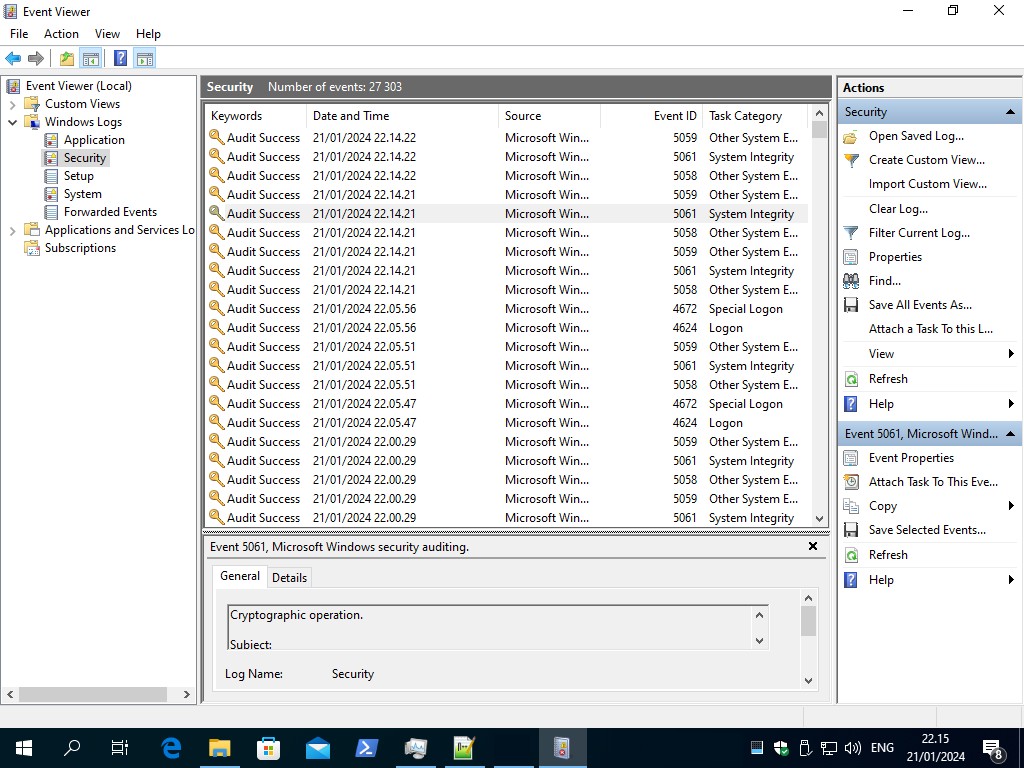
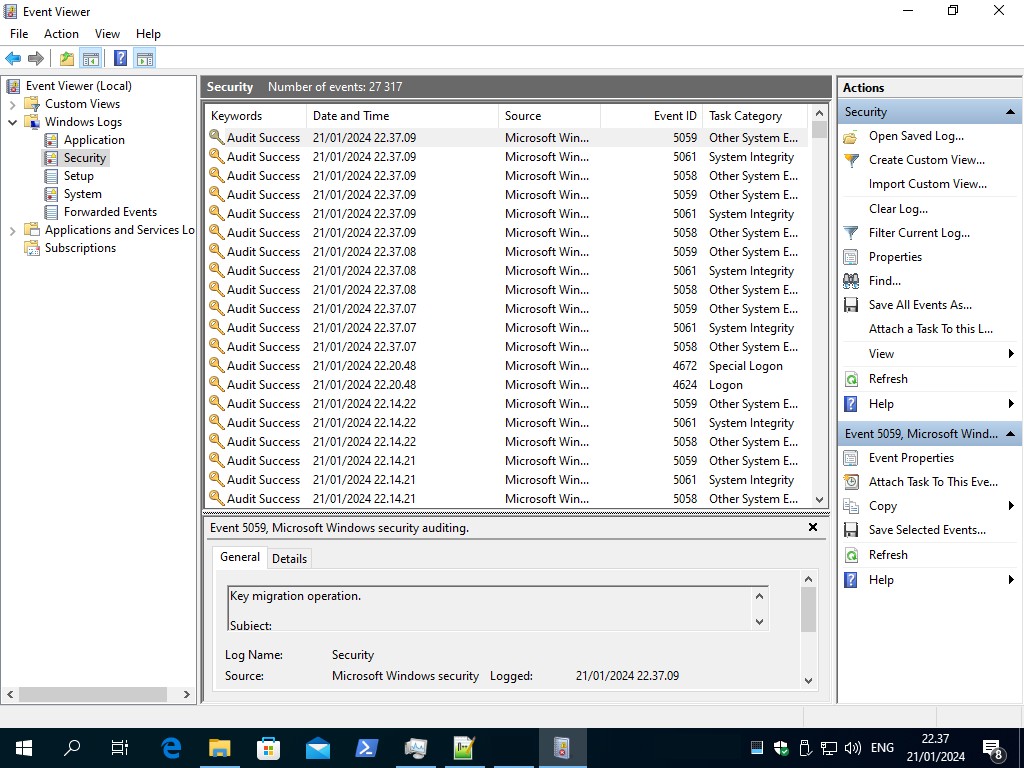
.
it shows 22:37 here, but it started at 22:34 and lasted to some 22:35, 22:36, and i see the posts in event viewer are little late than in fact occurred, but im sure its correlated now!

Everytime the CPU goes to 100%, this audits begins!
This happens only on 3 nodes i observe, and rest 10 nodes are not affected.
I can see that on not affected nodes, these audits happens much less often!
At this time the affected node is at risk to restart every few hours,
not sure what to do with that, to look to disable those audits? or tamper them, how?..