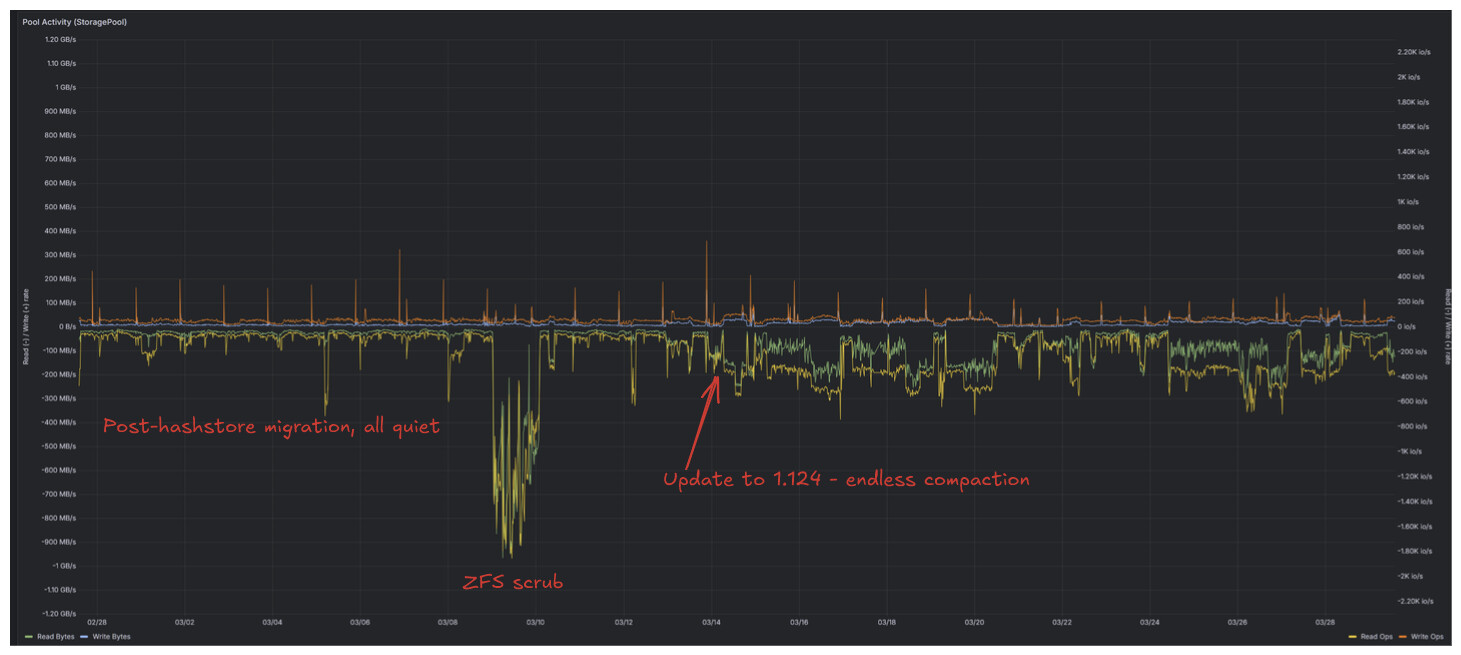
Previous versions were too lazy with compacting, new version playing catch-up, apparently compacting pretty much everything. On my meager 2TB node, it took maybe a day or so, then it calmed down once again.
Just today, about 100GB of trash got deleted and that triggered about 1.5h compaction burst. No small time, that, but nothing like the “catch-up” disk thrashing.
FWIW, I moved hashtables to an SSD yesterday (using symlinks), that may have sped up the most recent compaction some. Quite a lot of hashtable updating going on during compaction, it seems. Anyway, trash deletion isn’t a daily thing - more like a weekly one - judging by my own experience.
Be warned: my node is experimental, I’ve migrated it several times, messed around with it quite a bit, yet it has miraculously survived for almost 2 years. Probably not wise to repeat my moves for “production” nodes… if mine dies, it dies, zero tears shed.
One more year, give or take a few months, and I will have to exit (gracefully, I hope) anyway. Then start fresh after major (about three months) renovations to my habitat. Presumably with much speedier internet connection, upload in particular.
Having said that, I am willing to try memtables once they are released and someone more knowledgeable instructs me how to do that.
UPDATE: While waiting for the official release with memtbl, I scraped together my own “solution”: My "memtables" kludge