well sadly it’s not as simple as that… your hdd will still be writing the data in 512B or 4KiB sectors which represents an IO, and is the limitation… the advantage you gain isn’t a decrease in IOPS, but more an increase in HDD ability to process IOPS when the write is sequential.
in theory the fundamental IOPS required hasn’t changed, but since the HDD will be moving the heads around less, the latency decrease is immense.
Without a doubt i would run it at 4MiB, but do keep in mind if some uploads take 1 minute or 10minutes, not sure what the max is… then each file transferred during that time would require 4MiB
so you might run into some kind of issues with peak loads, i would suggest having a swap ssd just in case.
figured i would dig into that a bit… try and check what kind of number i would get…
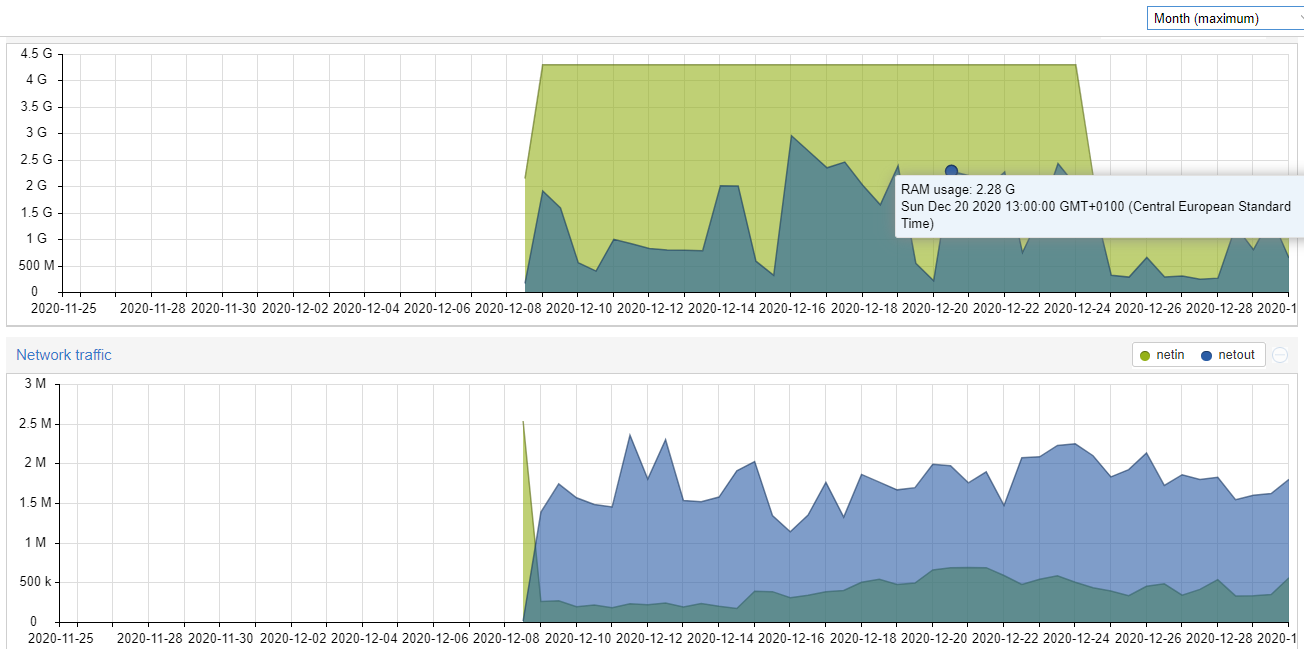
october seems to be the peak month for me in recent time.
with 1.3 mil uploads and with there being 43200 minutes in a month, lets call that 30 uploads a minute as my monthly avg…
so lets say that’s okay, not like 30 files a minute is to much ever… granted some uploads can take a few minutes, so if we say 10 minutes thats 300 files avg and still thats less than 4GiB RAM usage only slightly over 1GiB.
going into detail some days have even more like oct 15th have an avg upload of 40 files a minute.
and around 50 at oct 16th… or 55 to be exact avg a minute over a full day…
that’s 10 minutes essentially filling 2GiB, on avg…
then the peaks maybe 4x that, so 8GiB … ofc in that we are assuming the 10minutes with no uploads being completed, which is ofc unrealistic… but it’s to get a sense, how much memory would actually be required at known peaks.
so at the very least i would say having less than a couple of GiB of RAM might be the limit for using the 4MiB write buffer setting, it’s not easy for me to dissect my logs to a more detailed degree, so i cannot say what the true peaks are, but i doubt most of them will out do our 3 month peak and then over a 10min period.
infact this might be what the storagenode uses RAM for… i suppose node size would also mean a lot… but my numbers is from my 14.4TiB node so atleast in the higher end of the spectrum even tho it’s quite a ways behind the leading pack these days.
and with that in mind, i wouldn’t be against running 4MiB write buffer on basically any system… i doubt, it would ever use more than 1-2GiB and that’s a high estimate i believe…
the benefits tho are increased IOPS / write throughput for the HDD, reduced latency because of less seeks, less work time and wear because of less seeks, improved reads for the same reason.
less fragmentation, which again gives more sequential reads.
this is the same exact reasons why i run a sync always policy and has an ssd write cache, so for me i’m not to sure if there is a benefit.
can’t recommend running sync always tho… unless if you got a good ssd, high sustained iops / throughput, i had to replace my 1 QLC and 1 MLC ssd that i was using as write cache, because they couldn’t keep up and was causing latency on the entire system, even tho they was in a dynamic load balance configuration, so that it would just write on which ever had the time for it… and the QLC was partitioned so that it would run as SLC only.
i would say the benefits of running higher write buffers are without a doubt an advantage, and i would set it at the highest possible advantageous number, which imo would be where one got the most usage… so … there sure are a lot of small files stored in my blobs folder… if each of them would get a 4MiB write buffer, then if somebody was writing like a ton of small files or however they are created, could quite easily go beyond the 1-2GiB avg
ofc something like KSM should be able to recognize that the allocated memory is empty after a while, i’m sure somebody has a list of filesize distribution on storagenodes we can use… my linuxfu isn’t good enough to check that easily.
yep, so as we can see there are quite a number of smaller files also, rough count seems to be somewhere inbetween 40/60 and 50/50 split, so what might happen is that, if your see a big increase in 1K,2K,4K files over a short period, it may allocated a full write buffer for each in memory and your other caches.
this is also the same reason why i limited my zfs recordsizes down to 256K, because running the higher allocation would cause my RAM and Caches to dump their data when prepping for incoming data.
so if i get 100 files in a second, it might prep for that to continue and drop 500x256K in RAM to be able to store the 5 Sec worth my Write Cache can hold.
granted that may not seem like a lot or a big issue, but i got tons of caches and it’s really annoying to see it throw out 4-8 GiB if i basically just touch the server, which was what i started seeing a lot when running 1M and 512K
so tho i would certainly advocate for increasing the number… i’m not convinced a 4MiB size might be the right choice… seems to me that it would be more beneficial around maybe 1MiB - 2.3 MiB at most… especially if it allocates the memory, which it very well might…
else i doubt it would ever run out of memory for this, and remember 256k is double as fast… so 512 is x4 and x8 for 1M, so what you are doing is essentially maybe multiplying your memory usage by 32x
for a benefit of maybe 4x speed… because past 1MiB the returns become greatly diminished.
hell you might see 95% of the same performance with 512KiB as compared with 4MiB at most likely 1/8th the memory cost.
so tho i would advocate to turn the number up if you need to and maybe even for most SNO’s…
then i would certainly be very careful about jumping the default setting by a factor of x32
it just makes any sort of problem you may run into in the future x32 times worse.
IMHO
and ofc i’m not your local witch doctor, financial advisor or psychic
just an interested builder of things.

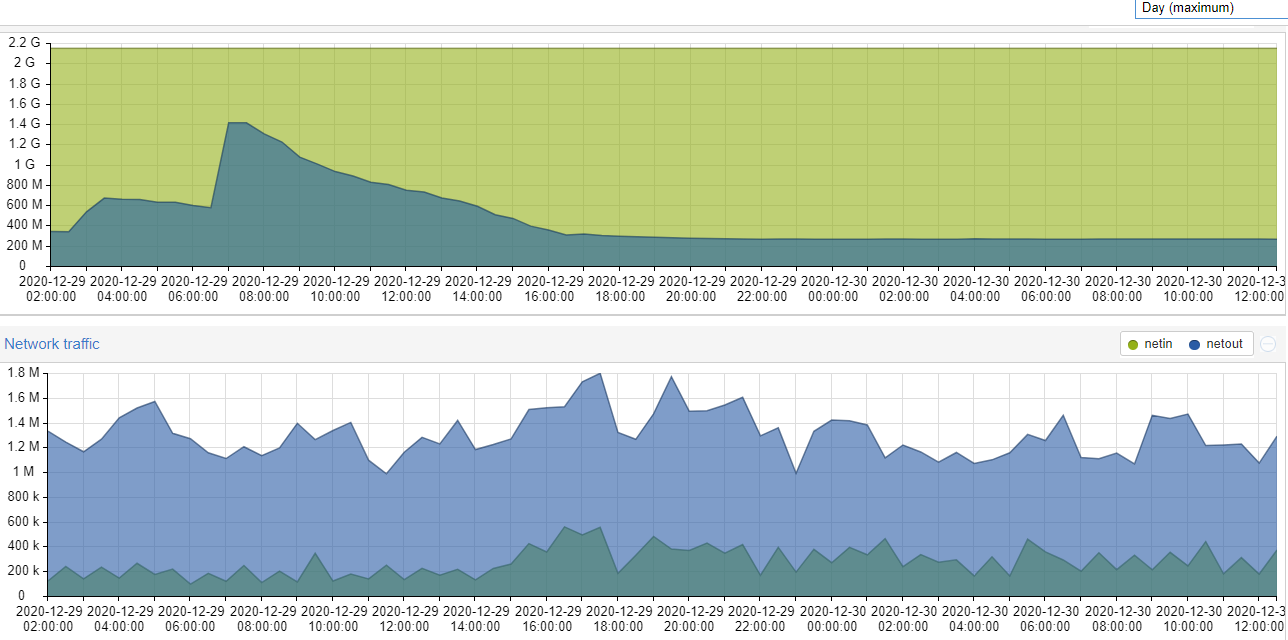
 i figured if the conventional hdd is running at a disadvantage then the SMR should also be so.
i figured if the conventional hdd is running at a disadvantage then the SMR should also be so.