That’s very likely, I restarted a node today for the second time and it barely caused any iowait so I guess it figured out that it didn’t need to run the garbage collector the second time.
Thanks for your answer !!
By the way, when disabling filewalker at startup, does it still run time to time on its own when “needed”? Or is it fully disabled meaning that occupied space might be a bit more wrong on the dashboard after each node restart over time?
EDIT:
According to the following post, satellites kind of ask nodes to run the filewalker for their files only, time to time:
Does this mean that it will also make sure that the reported occupied space by the node gets regularly corrected thanks to that process? Because if that’s the case, I don’t really see why one would want to keep the startup filewalker enabled?
if you got plenty of free space the filewalker is kind of pointless…
so far as i understand it… anyways
and no i don’t think it will run again by itself… it runs at start up only afaik.
but we might need somebody like @littleskunk to give us the exact state of that.
have been pondering just turning the filewalker off because i try to keep plenty of free space for my nodes… so would be nice to know if there actually is any other considerations when choosing to deactivate the filewalker.
No, the processes referred to there have a different purpose and don’t walk over all the files. One only checks the trash folder for files older than 7 days. The other checks a single satellite folder for garbage collection purposes. Neither update the used storage or scan all files at the same time.
But the latter could update the used storage cache, it stat()s all files for the given satellite anyway.
That will make the code more complex. Let’s say in a few months from now the used space on your storage node is incorrect. How do we find that bug if multiple processes are updating the value just because they can? It is usually better to have clear boundaries between packages. The package that deals with garbage collection should have the code in it that you would expect to find there. It gets confusing if packages are doing much more than they should.
Eh, it will still be far from the complexity of the upload path, which somehow runs through request validation, orders logging, bandwidth logging, tons of other stuff, etc., going through defers for finishing the upload, all in a single function.
Besides, the problem of the file walker putting load on storage sounds like there should be a package for file walking, which then sends results to services responsible for GC and space cache.
Sorry for bringing this back from the past; I just stumbled upod the topic. Can you clarify something for noob SNOs like me that don’t read the entire White Paper and don’t understand code?
From reading through this topic I understand that there is this Filewalker process that runs after a node restart, cecks all the space occupied by the files and report it back to satellites. Normaly, it runs after each node restart, but what if it can be set to run only after updates, by making a special file in the Storj directory where the update process sets “Filewalker - ON” after a succesfull update, restarts the node, and than Filewalker checks that switch; if it’s ON, it will start, and after finishing, will modify it to “Filewalker - OFF”. In this way, restarting the node will not trigger the Filewalker, only a successful update will, that happens 2-3 times a month.
And second, I see that they enabled a switch to turn it off. If there is an update, it will run no matter what? Or is OFF for good? Is is bad for the network/ storagenode oparation, if I set it OFF and never switch it back to ON? Is there an official guide to handle this or some official recomandations?
Sorry but we are not all code wizards to understand stuff and make easy decitions.
Official recommendation = default settings ![]()
If you turn it off, your node will have a wrong assumption on what’s used, so your dashboard will show a wrong data and will report to the satellites this wrong data.
However, the cache will be updated every hour (by default) anyway.
It would be great to find the root cause. The storage node is updating the cache value live. So any upload will increase the used space. And delete will reduce used space. If this math works correct the cache value should always be correct without having to run the file walker. There are only 2 ways to get a wrong used space value:
- Manual operations on the hard disk like untrusting one satellite and deleting the entire folder.
- Some kind of bug. Most likely not around normal uploads, deletes and garbage collection. We would have noticed that by now. Maybe something that is less obvious like restore from trash or graceful exit. If that is the case we can fix it so that the cache value will be correct even without having to run the file walker.
My own experience so far looks great. I don’t see any wrong used space values.
Luckily this is not happening otherwise the file walker would run every hour.
We have this parameter:
--storage2.cache-sync-interval duration how often the space used cache is synced to persistent storage (default 1h0m0s)
So, this cache updater is disabled with disabling the filewalker on startup?
This is the first time in 2 years, since I started as a SNO, when I took a closer look at disk statistics on my 9 nodes in 8 Synology machines, some older, some newer. I was shocked to find out how much damage can Filewalker do. This must go!
Nobody touches the storagenode files, nobody deletes them, why check them if they are there?
You must implement some other mechanisms, that dosen’t put the HDD/storagenode through hell.
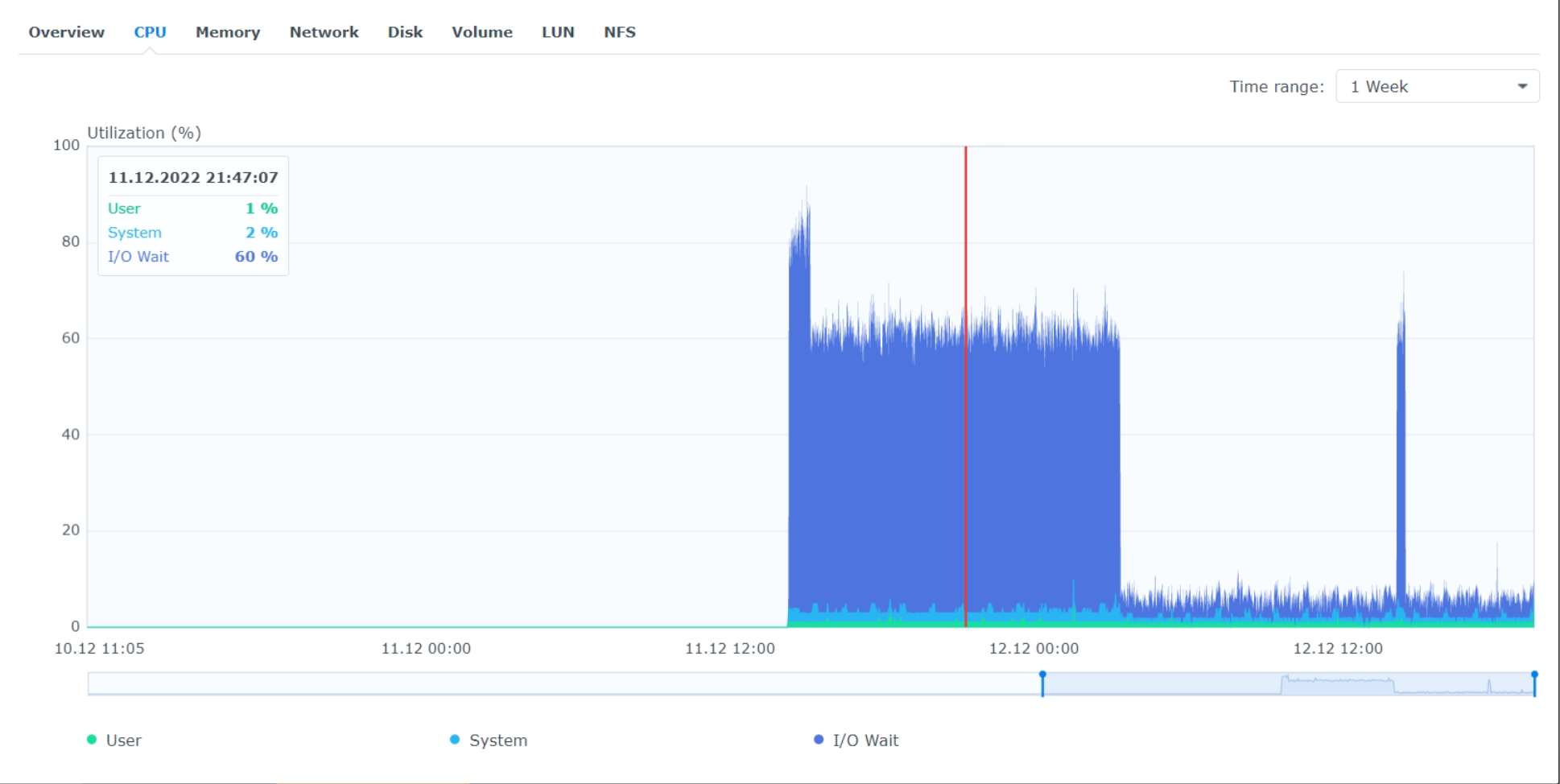
System 1- DS220+, Exos 16TB - 7 TB occupied. Has updated 8 days ago. HDD utilisation 100%!!!
8 days of FW keeping HDD at 100%! Restarted with FW off, and after 15 min of 100%, utilisation dropped to normal levels, ~8%.
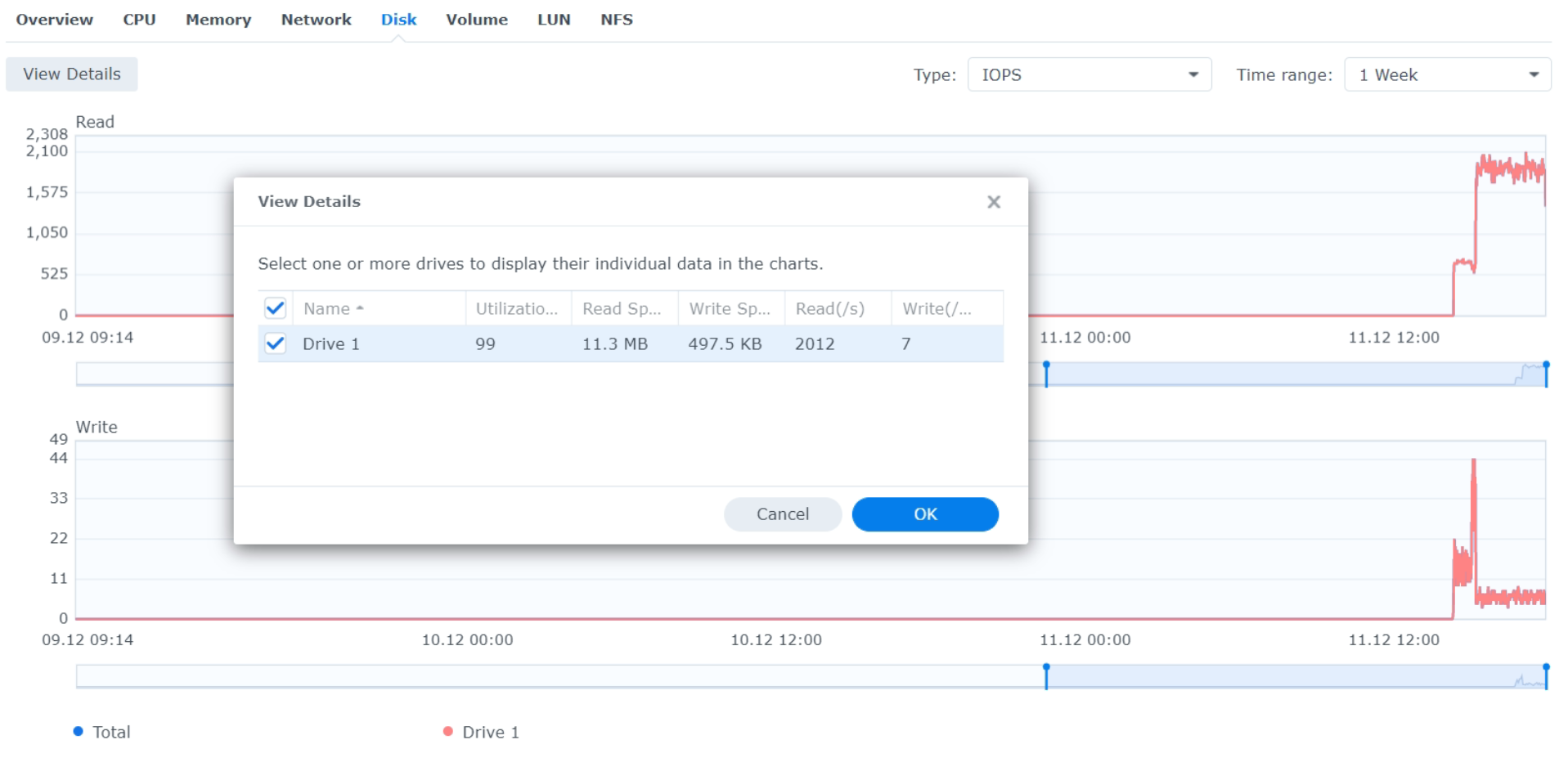
System 2 - DS216+, 2x Ironwolf 8TB - 5TB and 1.5TB occupied. HDD Utilisation 6-8%, 20-30 IOPS. Restarted the 5TB one (Node 1) and activated activity History. After 25 hours, HDD is still at 100%, over 3000 IOPS. The online score for both nodes droped 0.2%.
Node 2 shows QUICK missconfigured. The overall response is very slow, even stoping a node takes 2-3 minutes. Many log errors for downloads and uploads canceled.
I restarted both nodes with FW off and all came to normal. QUIK OK on both. System is responsive.
I restarted all 9 nodes with FW off and I will never switch it back on. It’s a very big problem!
If my nodes get dammaged/corrupted/out of space is not my fault. I allocate 14TB of 16TB, and 7 of 8TB on each drive for storagenode. Plenty of room for overhead.
Imagine if you use for Sorj an hdd with your personal files, and Filewalker starts. You can’t even access them.
I suppose you use BTRFS or zfs or maybe another software RAID for these systems?
Do you run multiple nodes on the same array/pool/volume/drive ? I guess the IO adds up when all of those nodes are restarted at the same time.
Then again, i have a single node with ~25TB of data and filewalker finishes in about an hour, but that’s probably because most of the metadata is cached in RAM as my server probably has enough RAM for that.
None of the above.
1 x DS216+ 1GB RAM, 2 x 8TB Ironwolfs, standard model, no SED.
7 x DS220+ 2GB RAM, 1 x 16TB Exos, standard model, no SED.
Raid type: Basic.
Filesystem: Ext4.
1 node/ HDD.
Record access time: never.
Fast repair: enabled.
No dedicated cash ssd or anything, just the hardware cash of the HDD, which is 256MB multisegmented in Exos, and 256MB in Ironwolf.
They are CMR drives.
Only the DS216+ has 2 drives installed.
I don’t run anything else on them, only Storj nodes.
I don’t know if the above settings are good or bad, but they are recomended by the comunity, in my firsts posts.
Is another setting, enabled by default in DSM: Memory compresion. I don’t know if matters.
The first system can’t suppot more RAM, but the newer ones can take another 4GB stick; should I install it? It’s like 100 $/piece.
The IOPS were like 3000 for EXOS and a little lower (2400 I think) for 1 Ironwolf. That was displayed in Performance monitor, in DSM.
DSM and Docker are up-to-date.
Nothing running as scheduled tasks, other than SMART test once per month on day 15. No Firewall. No Health monitor. No antivirus.
This is very weird. Most of setups showed not more than a few hours of filewalker. Only slow one or network connected takes days.
Maybe it’s fragmentation? Or the memory compretion thing?
The temps are very good too: 30-38 for CPU, 30 for HDDs; cooler is set to Full.
Maybe DSM has something to do with this, if standard Linux systems don’t manifest this simptoms.
I remember one of the first posts in this topic, maybe the first one, saying that he saw 25h FW too.
Try disabling memory compression. Apparently it can use a lot of CPU.
I do not how true it is, but you can test it on one of your nodes - disable it, restart and see how long filewalker runs.
Is there a benefit in installing more RAM?
I tested both configurations, with Memory compresion ON and OFF.
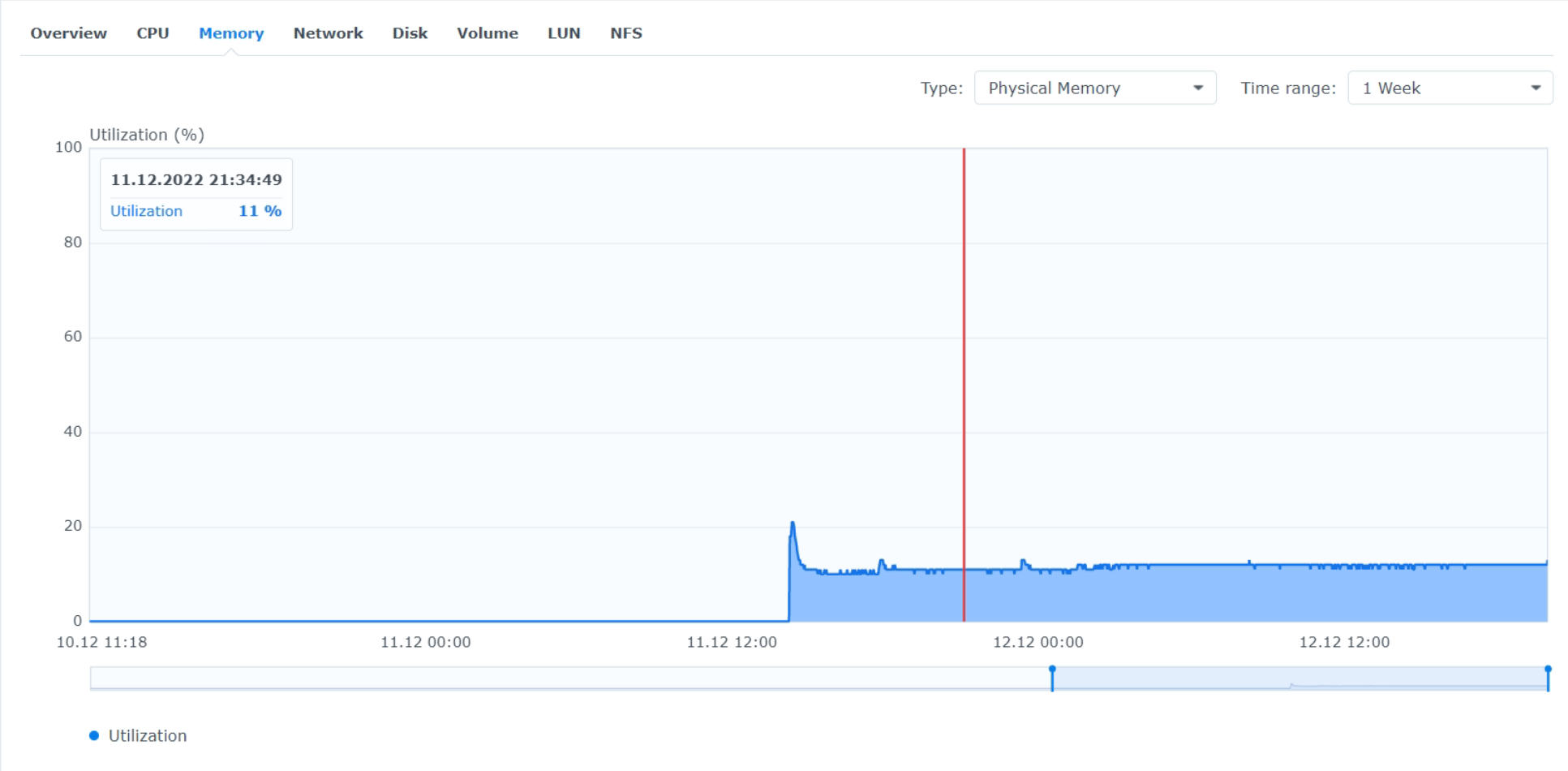
It seems that there is a small benefit in turning it off. Used RAM dropped a bit, from 273MB to 207MB, (from 14% to 11% utilization) and Filewalker took 3.92 hours/TB, instead of 4.14 hours/TB.
But… still FW takes a lot of time. It ran for 11.5 hours, for 2.93TB.
This means that for a full HDD, with 14TB of data, it will take 55 hours. Update happens 1/10 days, so 3x per month. This makes FW run for 7 days/month; 1/4 of on-line time for a full node.
Unacceptable! I will keep FW off for good.
Some RAW data:
Synology DS220+, 2GB RAM, 1 Exos X18 16TB FW SN04, 1 node, raid type basic, FS EXT4, reccord access time - never, memory compression off, no tasks running, no firewall, no antivirus, DDOS protection off, network 450/150mbps, used only for storagenode, ver. 1.67.3. DSM, packages, Docker up-to-date, log level error. No cash set-up, only the HW cash from HDD. FAN cool mode, HDD 30C, CPU 32C.
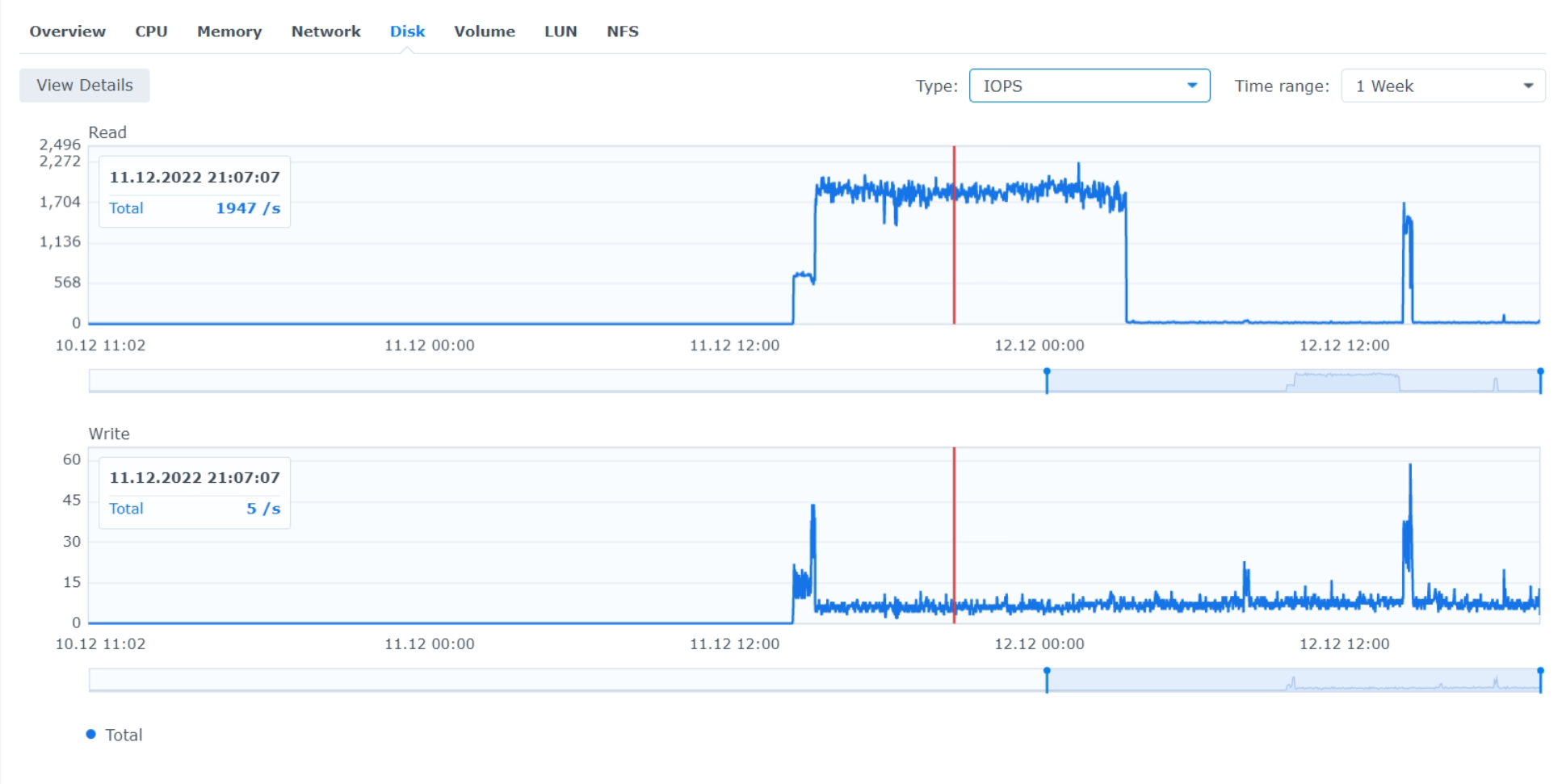
- 2.93 TB data,
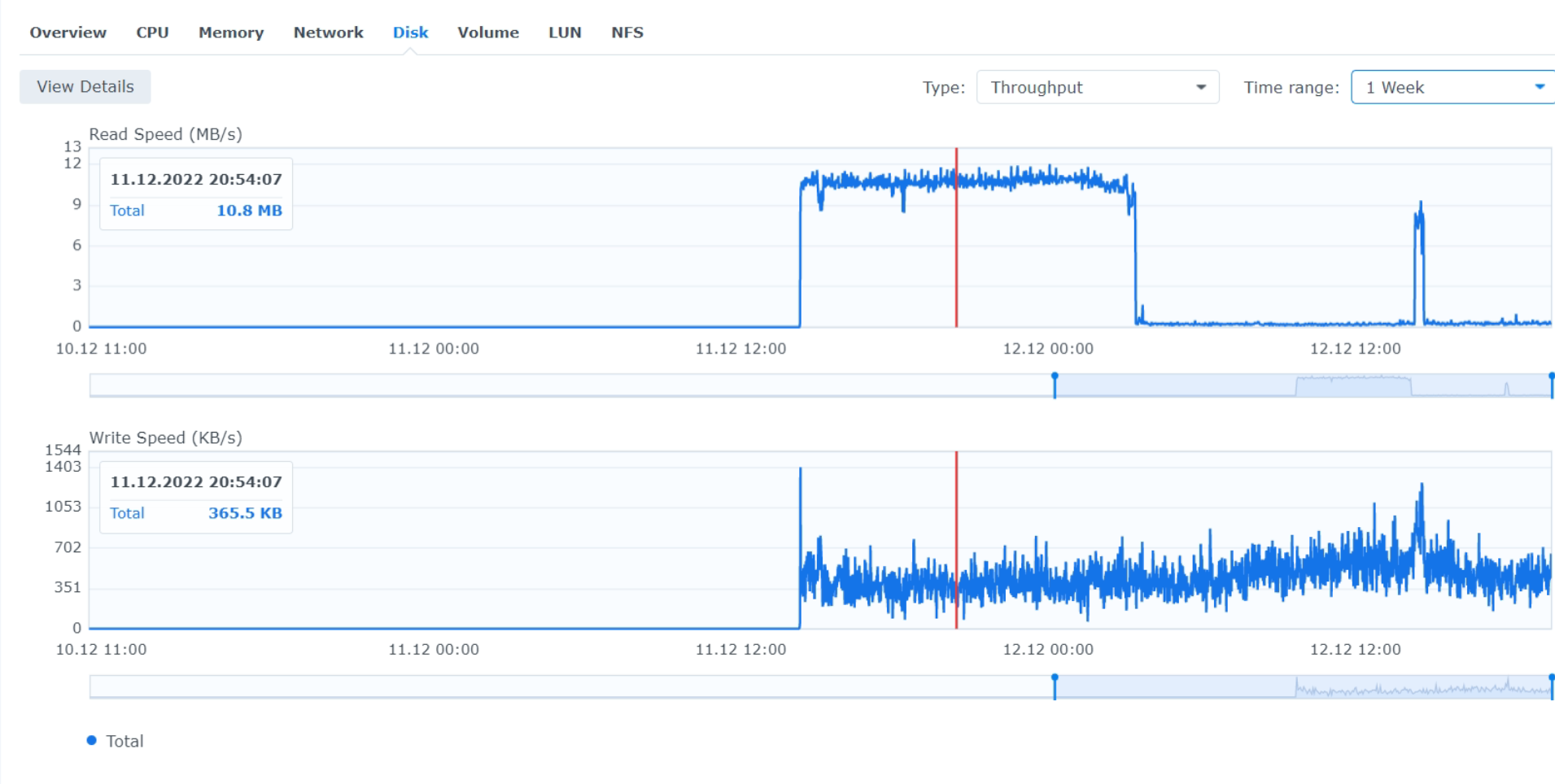
- Filewalker runs for 11.5 hours,
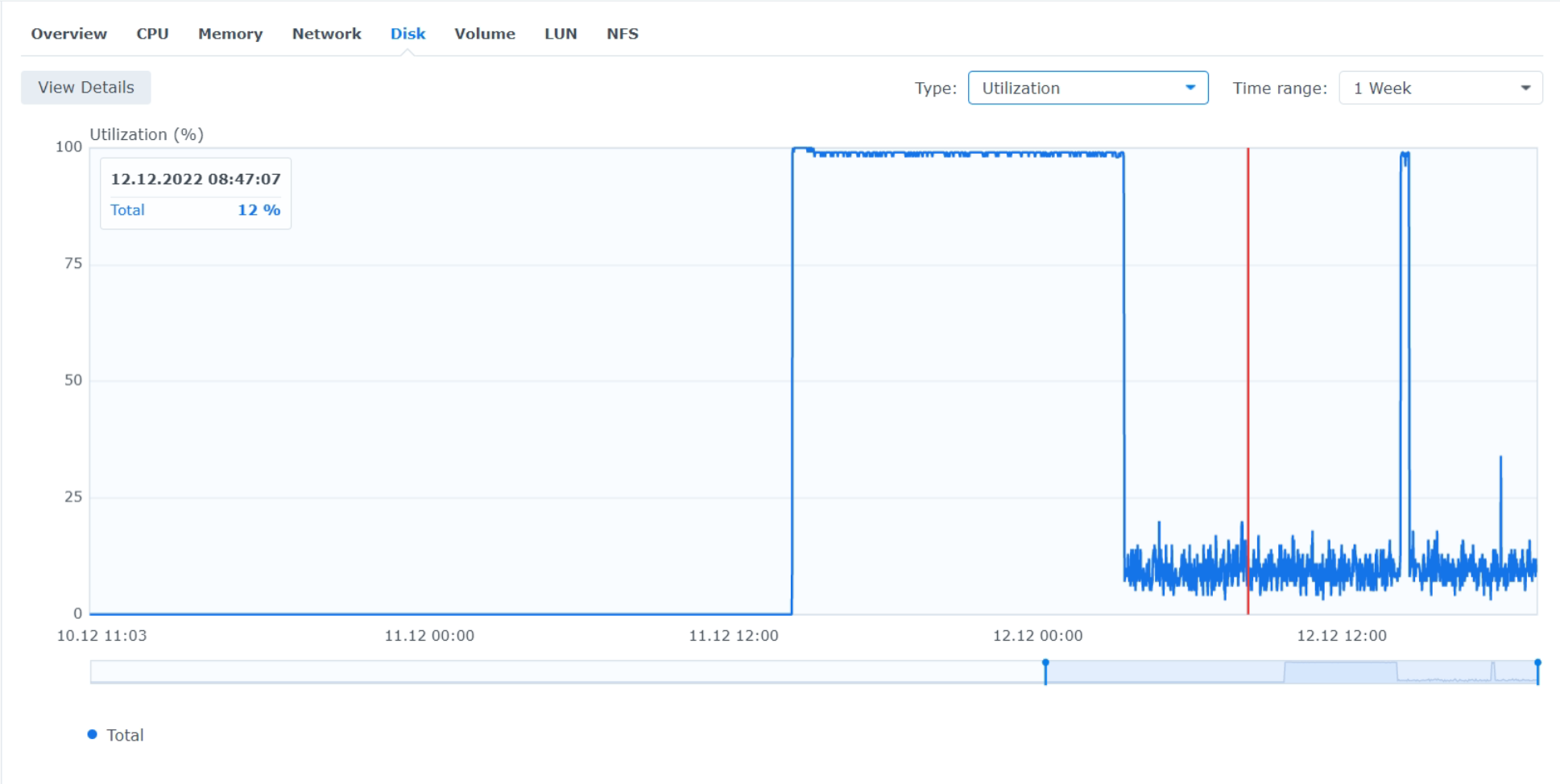
- HDD utilization 99%, IOPS ~1650-1970 read, ~7 write, throughput 10MB read, 365 KB write.
- RAM utilization 11%.
- CPU I/Owait 60%.
- SWAP 0 reads/writes.