This is frankly getting to ridiculous proportions. @elek , we had a great conversation around bloom filters early May and things seemed to really be on the right track. But now…
And it seems Saltlake hasn’t sent out bloom filters in literally over a month.
2024-06-06T18:50:52Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-01T17:59:59Z", "Filter Size": 5397472, "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2024-06-07T03:56:33Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 1028461, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 26253675, "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Duration": "9h5m41.135133831s", "Retain Status": "enabled"}
2024-06-12T21:30:48Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-09T17:59:59Z", "Filter Size": 460606, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-06-12T22:12:34Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 66212, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 848448, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Duration": "41m46.358769283s", "Retain Status": "enabled"}
2024-06-13T11:27:18Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-09T17:59:59Z", "Filter Size": 2411035, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-13T12:34:56Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 176833, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 4275794, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Duration": "1h7m38.160572627s", "Retain Status": "enabled"}
2024-06-13T13:15:09Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-09T17:59:59Z", "Filter Size": 460606, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-06-13T13:27:19Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 6783, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 794783, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Duration": "12m9.928919121s", "Retain Status": "enabled"}
2024-06-14T13:33:43Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-10T17:59:59Z", "Filter Size": 462200, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-06-14T13:52:06Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 2995, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 794078, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Duration": "18m22.156305318s", "Retain Status": "enabled"}
2024-06-19T16:39:32Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-13T17:59:59Z", "Filter Size": 16699654, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2024-06-19T22:21:43Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 2910495, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 32856337, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "5h42m11.749953998s", "Retain Status": "enabled"}
2024-06-20T01:26:55Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-15T17:59:59Z", "Filter Size": 2481750, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-20T02:20:25Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 145251, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 4342359, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Duration": "53m30.467482496s", "Retain Status": "enabled"}
2024-06-21T23:07:58Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-17T17:59:59Z", "Filter Size": 2475603, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-22T01:45:43Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 60245, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 4207524, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Duration": "2h37m45.09634223s", "Retain Status": "enabled"}
2024-06-22T06:46:49Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-18T17:59:59Z", "Filter Size": 2475603, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-22T08:41:47Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 19681, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 4147278, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Duration": "1h54m58.414141336s", "Retain Status": "enabled"}
2024-06-25T10:42:39Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-19T17:59:59Z", "Filter Size": 16862250, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2024-06-25T20:13:42Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-21T17:59:59Z", "Filter Size": 2452566, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-26T04:09:55Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 47304, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 4158698, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Duration": "7h56m13.208577815s", "Retain Status": "enabled"}
2024-06-28T22:46:11Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-25T17:59:59Z", "Filter Size": 462226, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-06-28T23:15:09Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 38467, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 816432, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6", "Duration": "28m58.86716795s", "Retain Status": "enabled"}
2024-06-29T11:58:24Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-25T17:59:59Z", "Filter Size": 2459116, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-29T13:20:39Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 28516, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 4124317, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Duration": "1h22m15.486125133s", "Retain Status": "enabled"}
2024-07-05T23:32:20Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-29T17:59:59Z", "Filter Size": 16222864, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"} 2024-07-06T03:51:38Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-07-02T17:59:59Z", "Filter Size": 1878640, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"} 2024-07-06T06:38:03Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 882895, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 4095795, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs", "Duration": "2h46m25.295524371s", "Retain Status": "enabled"}
2024-07-06T17:38:07Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 2082729, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 29393536, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S", "Duration": "18h5m47.2562348s", "Retain Status": "enabled"}
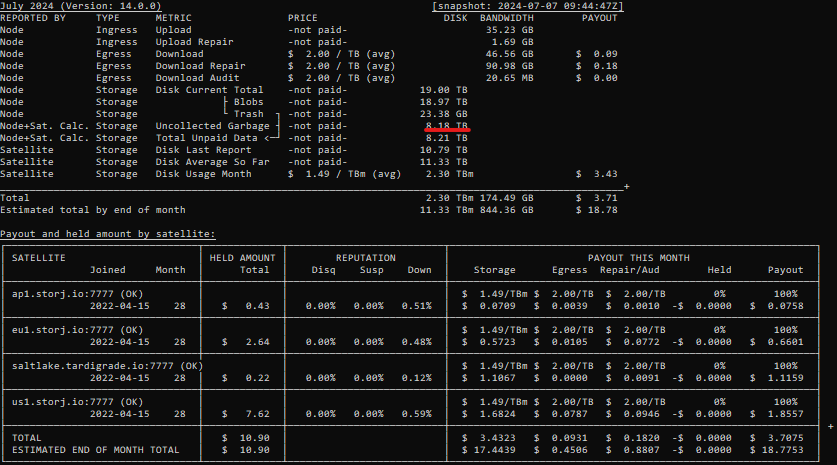
This despite knowing that due to a testing misconfiguration with random file names, many files were overwritten, causing deletes. In addition to that, I think it’s fairly well known that failed/canceled uploads often end up placing the file on the node anyway and rely on GC to clean that up. This is probably why we see such wildly different percentages of uncollected garbage across nodes. This simply isn’t acceptable to stop bloom filters during this testing. Storj claims it needs people to add more disk space, but it’s wasting the disk space already available. Please take action on this asap and start sending bloom filters for Saltlake again.
As many know, I don’t usually use a harsh tone in my posts, but in my opinion, this is uncharacteristically bad and needs to be resolved. There has also been 0 communication around bloom filters being paused. (I may have missed it to be fair, but I didn’t see any) And to ask people to expand when many might not know half or even more of their stored data is garbage, encourages people to make bad decisions and possibly end up buying expensive HDD’s only to figure out later that they didn’t need them at all after this issue has been resolved. It’s a really bad look. (And please don’t give me the “we don’t recommend buying hardware” response. We all know SNOs buy HDD’s, so it doesn’t matter what the recommendation is. You have a responsibility to not misinform them.)
@Knowledge @Bryanm , this next part is relevant for you, as you’ve both shown interest in gauging SNOs willingness to expand.
In conclusion, I will not expand further until this situation is resolved. I have no way to gauge how much storage I actually need now, despite the testing. I have one last migration running that will add some free space to existing nodes, but after that, I’m done until this is fixed. I’m not going to risk ending up with empty HDD’s after this is fixed.
Pinging @littleskunk as well as this possibly significantly impacts calculations for the testing and might go some way to explaining why it looks like nodes get much more data than would be expected on average. In addition currently free space shown by nodes, significantly underestimates their actual potential.