That said I am wondering what happens to the partial uploads now?
According to this the temp folder is no longer used:
Are we having thousands of partial uploaded fields now in the blobs folders inflating the used space?
That said I am wondering what happens to the partial uploads now?
According to this the temp folder is no longer used:
Are we having thousands of partial uploaded fields now in the blobs folders inflating the used space?
I think they are kept in memory and only written to the blobs folder when the download finished.
Which would mean you need a lot of memory…
Not necessarily. There are buffers and I believe that pieces are written to the file by buffer size if needed, but to leave it exist the file should be closed, otherwise it will not be saved. It can be closed only if the upload is finished completely (or OS has been reset in the meantime, then after the reboot the journal would be replayed recovering the partially saved file I believe).
However, in the case of an abruptly reset, the partially written file may remain there.
And it will be collected by a Garbage Collector too.
There is a test network that you can even participate in. I’m running a test node because outside of just testing for general issues, it’ll also tell me if an upcoming version might cause issues on my specific setup. I encourage everyone to join it, though keep in mind that it’s unpaid. Storage amounts are low though. So that shouldn’t be an issue.
v1.108.1 is being tested there atm.
I see one of my nodes running GC for Saltlake now. So it seems they started creating bloom filters again. Thanks for that Storj!
Thats good to hear, I have seen nothing as yet for SL, I can see the usual used and trash cleanup filewalkers, but yet to see any bloom filters for SL - been that way for a while now. I hope they get around to me soon.
Please let us know how much of your, 8TB was it? , that is free’s up
Thanks
CC
This was on a different, smaller node. It didn’t have that much uncollected to begin with. But it seems it’s moving a lot to trash. We’ll see where it ends up.
EDIT: GC just started on the node I posted about before. I’ll post an update when it’s done to show how much of the 8TB is moved to trash.
EDIT2: GC finished on this smaller node. Results are not ideal yet.
2024-07-09T07:39:12Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-30T14:28:54Z", "Filter Size": 1251195, "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2024-07-09T09:27:26Z INFO retain Moved pieces to trash during retain {"Process": "storagenode", "cachePath": "config/retain", "Deleted pieces": 921884, "Failed to delete": 0, "Pieces failed to read": 0, "Pieces count": 3082480, "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Duration": "1h48m13.745349438s", "Retain Status": "enabled"}
The bloom filter was created on June 30th. So pretty old.
Whats this? A SLC Bloom FIlter, whoohoo. Lets see what it does…
root@pool:~# grep "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE" /mnt/Pool/StorJ-Node/Config/node.log | grep "gc-filewalker" | grep -E "started|finished"
2024-07-09T11:21:00Z INFO lazyfilewalker.gc-filewalker subprocess started {"Process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
2024-07-09T11:21:00Z INFO lazyfilewalker.gc-filewalker.subprocess Database started {"Process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "Process": "storagenode"}
2024-07-09T11:21:00Z INFO lazyfilewalker.gc-filewalker.subprocess gc-filewalker started {"Process": "storagenode", "satelliteID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE", "createdBefore": "2024-06-30T14:28:54Z", "bloomFilterSize": 17000003, "Process": "storagenode"}
Thanks
CCThanks for all the feedback, (especially the constructive ones)
There are many misunderstandings (and statements which are false) in this thread. Let me share my view:
I appreciate your post, but I included my logs, which clearly show no GC for Saltlake for a month, while other satellites seem to have worked fine. Can you explain how that could have happened then?
I can check logs for my other nodes tomorrow, but I have a running tail of the logs open all day while I work and debug logging is on, so I see GC in progress. And until the recent one, I haven’t seen any GC for Saltlake on any of my nodes for a long time. While now, I noticed it immediately on many of my nodes.
I think you know I’m not in the business of making false statements and I verify before claiming something. But I’ll adjust my statement if it helps: “My node has not processed any bloom filters from Saltlake for a month.”. Perhaps the satellite sent them, but something still went wrong. Even though other satellites did GC just fine on my node.
I’ll see if I can get more data from other logs tomorrow.
Edit: Btw, I really appreciate the other progress on GC you mentioned in your post. And like I said in my earlier post, I don’t share the opinion of some that issues are ignored. It’s pretty clear to me that that is not the case. Keep up the good work.
I can confirm the same as @BrightSilence - I have gc start/finish log entries for all other satelites, but not SL in the last 4 weeks that I have been commenting on the amount of uncollected garbage - thats when I started taking a much closer look, and keeping logs.
On the positive side - the bloom filter received earlier today is still running, and has moved 1TB of the 2.4TB to trash so far, another 7 days for trash to clear up and I can start taking data again ![]()
edit: gc finished - removing 1.6TB but left 1TB. Appreciate bloom filters are only supposed to be 80%, so while progress, we just need them more regularly, and I know thats what elek mentioned they were improving.
Thanks
CC
FWIW my nodes have received SLC bloom filters a couple of hours ago. It’s slowly going out. I have another node that runs this with the badger cache enabled so I’ll see what the speed will be the next round of GC.
2024-07-09T07:54:23Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-30T14:28:54Z", "Filter Size": 6551299, "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
In case a partial upload fails, it is removed immediately. This was the case with files in the temp directory, and this behavior was not changed since then. What has changed is that if node fails to remove the file immediately (e.g. due to a hard crash), it will later be collected by a garbage collector as part of routine bloom filter processing.
Ah, sorry, I misunderstood this one. I thought it’s about no GC in the last month at all, from any satellite. If only the SLC is missing, it might be a more isolated problem…
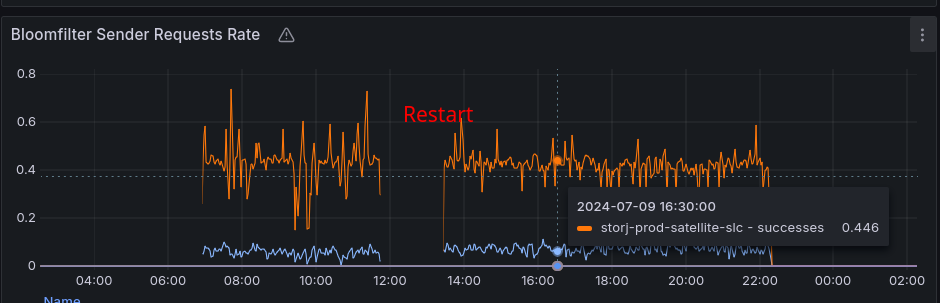
I see the SLC generations in our graphs and I see that SLC BFs are sent out multiple times.
But – for example — during yesterday, the sender process (satellite core) was killed during the sending process (due to the increased memory requirement). The memory limits are increased and the process is restarted. But I can imagine that the retry is not as good as we thought, and after restart it doesn’t continue / ignore some failed nodes.
It should be definitely checked.
Would you mind to check it again? As far as I see, the process has been sent out all the filters after restart…
(And BTW, thank you for all the reports, appreciate it, and they are very useful. Probably I picked wrong words when I wrote false statements. It’s definitely not about bug reports, they are all useful. It just comes out of a disappointment: There were too many subjective comments which were ignored the progress what we do together so far, in other threads )
Ah, didn’t know that you started to test it. Be aware: it’s not a stable feature: I am just starting to test it as well… That’s the reason why I didn’t share it more wildly…
But I am definitely interested about the results. For me the 8-13h walker time dropped to 1h from the second time.
Don’t worry about it. All good ![]()
And I understand the impact some of these responses can have. I’ve been trying to tell people to at least take that to other threads and I’ve frequently asked to keep threads clean which you guys are actively monitoring. I’d say just ignore the negative posts, you’re working on the right things from what I can tell, so it’s not like you’re not aware of those issues anyway.
I’m checking my logs now and the big one I posted about is hard at work with SLC GC for over a day now. It’ll likely take a while and it looks like the size might have hit the current max. Is 17000003 the max size? If so, it might not clean up as much as normal, but I’ll keep an eye on it.
2024-07-09T09:28:25Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-30T14:28:54Z", "Filter Size": 17000003, "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
I guess it’s no surprise with the massive testing that SLC runs into new issues with GC with out of memory on your end and hitting the max size first. But that’s what these tests are for, right? Perhaps it warrants another bump in BF size, but I’ll report back when this one is done.
My system is quite slow at the moment, running a node migration and many file walkers (GC,TTL etc), so it might take a while before I have other logs.
EDIT: I looked through most of the logs now. From what I can tell, most of my nodes received a bloom filter for SLC on 6-6 and then some on 6-14, but not all. After that there was nothing until yesterday.
It would be… interesting… to see more behind the scenes on what the bloom filter process is like. Since it’s not something seen by all the node operators, it’s just a storj inc process, it doesn’t have as many beta testers. But it sounds like it’s quite an involved process.
Furthermore, it might be nice to kind of see a “satellite status” page. Things like the last time bloom filters were generated and the time window they were sent. Maybe even fun stats like total bandwidth uploaded and downloaded from the satellite’s perspective.
I checked my smallest node (1.8/1.8TB, full to capacity for many months) and it also receives BF more regular and more recent:
|2024-06-29T05:15:02+03:00|INFO|retain|Prepared to run a Retain request.|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Created Before: 2024-06-25T17:59:59Z, Filter Size: 106830, Satellite ID: 121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6}|
|2024-06-29T08:40:13+03:00|INFO|retain|Prepared to run a Retain request.|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Created Before: 2024-06-25T17:59:59Z, Filter Size: 431261, Satellite ID: 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs}|
|2024-06-29T13:59:46+03:00|INFO|retain|Moved pieces to trash during retain|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Deleted pieces: 7685, Failed to delete: 0, Pieces failed to read: 0, Pieces count: 189534, Satellite ID: 121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6, Duration: 8h44m44.1341826s, Retain Status: enabled}|
|2024-06-29T14:42:17+03:00|INFO|retain|Moved pieces to trash during retain|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Deleted pieces: 53521, Failed to delete: 0, Pieces failed to read: 0, Pieces count: 801657, Satellite ID: 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs, Duration: 6h2m4.0452696s, Retain Status: enabled}|
|2024-07-06T00:22:39+03:00|INFO|retain|Prepared to run a Retain request.|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Created Before: 2024-06-29T17:59:59Z, Filter Size: 4584430, Satellite ID: 12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S}|
|2024-07-06T09:00:57+03:00|INFO|retain|Moved pieces to trash during retain|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Deleted pieces: 1058902, Failed to delete: 0, Pieces failed to read: 0, Pieces count: 8915553, Satellite ID: 12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S, Duration: 8h38m18.1013284s, Retain Status: enabled}|
|2024-07-06T12:08:12+03:00|INFO|retain|Prepared to run a Retain request.|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Created Before: 2024-07-02T17:59:59Z, Filter Size: 408667, Satellite ID: 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs}|
|2024-07-06T12:50:08+03:00|INFO|retain|Moved pieces to trash during retain|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Deleted pieces: 101558, Failed to delete: 0, Pieces failed to read: 0, Pieces count: 785032, Satellite ID: 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs, Duration: 41m56.0643357s, Retain Status: enabled}|
In fact, it matches your data 1to1: The last 2 BF was for same 2 satellites, with exactly the same Created Before timestamps.
Only the time for receiving filters by nodes differs by several hours. But this is quite expected - generating BF is a resource-intensive operation and takes considerable time. And they are probably sent out immediately when they are ready.
But if i check one of my larges nodes ( 14/14 TB, also full to capacity now, but about ~30% of this capacity is uncollected garbage)
It was only resends of old BF:
|2024-07-07T14:37:09+03:00|INFO|retain|Prepared to run a Retain request.|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Created Before: 2024-06-09T20:59:59+03:00, Filter Size: 6918625, Satellite ID: 1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE}|
|2024-07-07T14:37:09+03:00|INFO|retain|Prepared to run a Retain request.|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Created Before: 2024-06-18T20:59:59+03:00, Filter Size: 942802, Satellite ID: 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs}|
|2024-07-07T14:37:09+03:00|INFO|retain|Prepared to run a Retain request.|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Created Before: 2024-06-13T20:59:59+03:00, Filter Size: 8959048, Satellite ID: 12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S}|
|2024-07-07T16:50:36+03:00|INFO|retain|Moved pieces to trash during retain|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Deleted pieces: 3657, Failed to delete: 0, Pieces failed to read: 0, Pieces count: 889969, Satellite ID: 12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs, Duration: 2h13m27.0317304s, Retain Status: enabled}|
|2024-07-08T22:12:16+03:00|INFO|retain|Moved pieces to trash during retain|{cachePath: C:\\Program Files\\Storj\\Storage Node/retain, Deleted pieces: 0, Failed to delete: 0, Pieces failed to read: 0, Pieces count: 14100792, Satellite ID: 12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S, Duration: 31h35m6.8568286s, Retain Status: enabled}|
Update
Looks like one more recent BF finally arrived (yesterday, about 20 hours ago):
2024-07-10T07:12:20+03:00 INFO retain Prepared to run a Retain request. {"cachePath": "C:\\Program Files\\Storj\\Storage Node/retain", "Created Before": "2024-06-30T17:28:54+03:00", "Filter Size": 17000003, "Satellite ID": "1wFTAgs9DP5RSnCqKV1eLf6N9wtk4EAtmN5DpSxcs8EjT69tGE"}
It seems that the developers had serious problems with the generation of new LARGE Bloom Filters, which they had promised for a long time (pay attention to the size of the last one - its 17 MB vs 6.9 MB for the previous for the same SLS) and their generation was suspended
But now it has resumed. Its processing on my node is still not finished (only about 15% for almost a day of work), but it seems that this is what was needed. Judging by the contents of the sub-directories in the trash folder that have already been traversed, it deletes more than 8000 files per each prefix. I.e., it is expected to delete more than 8 M files for this satellite on full pass.
Finally, looks like a serious blow to huge piles of uncollected garbage accumulated on large nodes!
Perhaps these old BF were under a resume after the restart? Because no one of my nodes did receive these old BF in July, because they were sent in June:
2024-06-19T18:42:18Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-13T17:59:59Z", "Filter Size": 6427851, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2024-06-20T07:32:34Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-15T17:59:59Z", "Filter Size": 1193650, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-21T18:33:00Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-17T17:59:59Z", "Filter Size": 1191921, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-22T08:23:38Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-18T17:59:59Z", "Filter Size": 1191921, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-25T10:26:22Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-19T17:59:59Z", "Filter Size": 6372063, "Satellite ID": "12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S"}
2024-06-25T19:57:14Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-21T17:59:59Z", "Filter Size": 1204945, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}
2024-06-29T03:26:41Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-25T17:59:59Z", "Filter Size": 279371, "Satellite ID": "121RTSDpyNZVcEU84Ticf2L1ntiuUimbWgfATz21tuvgk3vzoA6"}
2024-06-29T12:18:52Z INFO retain Prepared to run a Retain request. {"Process": "storagenode", "cachePath": "config/retain", "Created Before": "2024-06-25T17:59:59Z", "Filter Size": 1216961, "Satellite ID": "12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs"}