Just tossing out ideas: but the best customer experience would come from always having many fast nodes available (and not full, rejecting ingress). Filling them with repair traffic, which no customer ever sees the performance of… would be a waste. So, since you still want to encourage slower nodes to stick around (since they always contribute raw capacity)… why not nudge repairs towards slower ones?
Like you said: every node gets the same $1.5/tb/mo. So why not configure things so there’s a greater chance fast ones always have space for those customers expecting fast uploads?
Not saying that’s a good reason, or bad reason… just a reason Makes you think!
Last time I checked, satellites were trying to get nodes at random for each segment. This will lead to a well-known effect (PDF warning, see section Expected maximum load) where by random chance some nodes will get more traffic than others. With 10k unique /24 blocks (I don’t know how many unique blocks are in the Storj network, you don’t publish this information, so this is just my guess) this would mean some blocks would get 4 times the load of other blocks.
A simple change to generate a random permutation of /24 blocks, then using nodes in this order, would spread the load more evenly.
That’s a surprisingly good guess! Just below StorjNet’s By-Subnet → Count-of-Subnets table it currently says “Nodes are running in at least 11,686 subnets /24.”
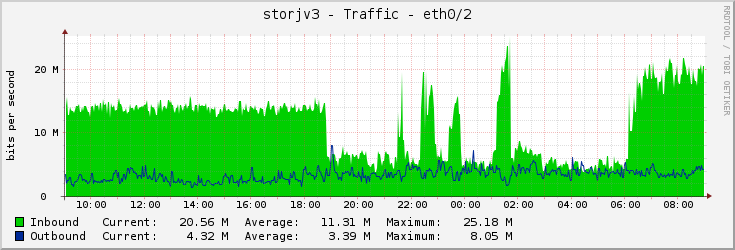
According to my stats overall ingress is yesterday is about 10x of average before thest.
But as we know it’s just wannabe ingress, so I don’t know what my nodes really handled.
That would have possible bad results. For one, unless they can get the customers to pay that much for egress, it would require complicated calculations how to make Storj profitable (getting customers to pay for storage and then using those who use Storj for backups to compensate for those who do not stora a lot of data, but access it a lot).
Another bad result would be the incentive to periodically kill and recreate the node for those operators who run out of space. After all, usually the most recently uploaded data is accessed more, so there is no point in storing someone’s backups that most likely would never be retrieved. Why keep a node that is full and gets almost no egress (and therefore, money)?
i mean they could make different satellies with different prices variants, for different use cases. Seems the only way to settle constant price debates.
Let people subscribe to satellites they like.
I would like both $1,5/TB store +$2/TB traffic,
but would like to try $0/TB store + $7/TB traffic,
or $2,5/TB store + $0/TB traffic as well.
Paying 0 for stored data? That’s the badest ideea so far. Clients can use their servers for caching frequently accessed data and use Storj only for cold storage. You get nothing.
Perhaps the node selection could be tuned for near-the-client nodes.
For example: when starting uplink, it contacts the satellite and says “this is my IP, give me a set of nodes”. The satellite gives the client the 1000 closest-but-not-same-country nodes. Uplink then pings each node, saving the results in a cache (perhaps the cache expires per month?). It then selects the 100 or so it wants based on that data.
I also agree with not-so-frequently-accessed-data being “demoted” to slower nodes. Afterall, if the client is using storj for a daily backup, the chances of needing a 127 day old backup are too small. Sort of invalidating data in a cache, less frequently get shoved somewhere else. This traffic (IMHO) can be free of payout since it will all be node > node.
Or a dynamic algorithm: get a list of nodes, contact X amount of them. If you are happy, keep that. If you are not, contact the next Y of them and so on.
I think there are different situations and I would use the repair service to accommodate for them.
A customer might be happy if his data are at the fastest nodes around him, because this is where the data gets downloaded.
But another customer might upload in place A and requires download in place B. (Think of maybe a production company that upload shots in LA but requires download in the contracted studio in New Zealand)
And another customer maybe wants general best worldwide availability as evenly spread as possible.
So maybe by creating such different usage profiles, the repair service could act on and distribute pieces to where it is most useful for the customer.
Doesn’t matter how small the chances are. If a customer needs to do disaster recovery from backup, they need that data as fast as possible.
I’m not entirely sure why we’re trying to somehow advantage slow nodes in certain scenarios. I’m sure node selection will still select them, just less. It’s to nobody’s advantage expect for the owner of those slow nodes to somehow try and give them more data through another route anyway. And the truth is that that node is simply less valuable. Getting less data seems fair then.
We’re just talking about interesting things: not pushing for change. But I don’t see it as trying to advantage slower nodes: more bias operations so that fast ones are always available. Like… the recent performance tests are aiming to tune writes: having bandwidth/iops to service ingress quickly when a client is pushing to 80 nodes is what they’re trying to speed up. None of the tests were trying to improve the speed clients can read from at least 29.
So how would you change things to make it slightly less likely fast SNOs are completely full (and denying ingress)… while keeping overall capacity the same? Ideally any change wouldn’t be noticed during interactive use: so maybe tweak internal housekeeping (like repair logic)?
Certainly if slightly more data ended up on slower nodes during repair… that could impact client download speeds. But then we’re back to their upload speeds being a priority over their download speeds. I’m not sure why that is: maybe because more data is upload/store/delete than upload/store/download (or upload/store-forever)? Storj would know for sure.
The current race system has been working well. But maybe there are ways Storj could put their thumb-on-the-scale for regular or repair node selection to improve the service? Some neat ideas!
BTW… not now but in a near future we must talk about uploads. I’m a SNO that love this project and I will never (maybe) cap my upload speed but I’m not sure that everybody do the same. Where to find motivation for not capping upload speed?
If you cap download speed (upload from clients to node), and you reach the cap, you will be loosing out on data you could have stored.
If you cap upload speed (upload from node to clients), and you reach the cap, you will be loosing out on egress, which is also paid.
Of course, if the speeds dont reach the cap there would be no difference.
Therefore capping your own speeds basically just gives an advantage to the remaning nodes which will get more ingress and egress, and in turn get paid more.
yes some caped, (or was caped by VPN)
but its money, if You won’t pick it up, someone else will take it.
So don’t worry about that, (and don’t start another offtopic )
beside i liked last test, saw some nodes got ~372GB ingress yesterday>
if its times 11000 unique ip’s, its like 4PB+ of data in less than 24h been uploaded from Storj to nodes. So if they simulate a customer, it’s 4-5 days and we’re back to what it was before the big purge that everyone mourned so much
imagine Storj, was using Storj’s service for that test, that traffic would cost $28 000 ;D
Would Storj Choose Storjs for Storjs test? ;D
(How much wood would a woodchuck chuck if a woodchuck could chuck wood)
Also capping your download at your location, when the traffic already made it to your router, is useless in most cases and does more harm than it helps.
For UDP it for sure is, the TCP might back off, the shaper for Storj however would have to be extremely aggressive for it to do something.
So don’t do this and if you have issues with download speeds simply upgrade the circuit.
Priority, maybe. But this is not the only cliënt and others may have different priorities. I do see the argument for using all space available, but at the same time I think many SNOs would just expand their faster nodes. So I don’t think that’s really an issue.
It’s been working well when all nodes easily deal with the load. But if half the nodes are struggling while the other half have plenty of room to receive more, the slow nodes are going to slow down the total transfer speed. Spreading the load based on success rate would resolve that. Plus it gives SNOs an incentive to upgrade their connection or system. Good incentives all around.
Perhaps such tests need to be laid on a permanent basis for new nodes. When vetting takes place, loading them more heavily will allow the operator to eliminate and recognize problems, as well as quickly put new units into operation.
if someone decides to add a new disk, according to the conditions 1 node = 1 disk, you need to create a new node. This means it is possible to increase the load on existing equipment (existing Internet channel) that needs to be tested.
the network will receive a new verified storage volume