I don’t think there is anything wrong with the USB controller, although I haven’t tried any other devices since there is only a single port on the USB3.0 host. So far as I can tell there aren’t any problems with the extrenal disk or the mount since I can read/write and the node can read/write. I know the node can read/write since it is writing pieces to the drive and it is reading from the bandwidth db.
The described behavior can happen only when the database is lost every time.
Please, make sure that your user for docker have a write rights to all databases.
Just do the chown them to that user for sure.
If you running your docker with sudo, then make the root an owner of those databases.
Hello. The node was abnormally stopped, the used space on the node is now reset. How can I restore the used space?
H Mishastvo, welcome to the forums.
Could you provide a few details about your setup? OS + version, storagenode version, where is the data stored, and how is the drive connected? If you are running the command line version, could you please post your run command?
Hi, (Orange pi zero+ H5, 512mb ram) Debian Stretch with Armbian Linux 4.19.63-sunxi64, 0.27.1, usb drive 2 TB, docker start storagenode.
docker run -d --restart unless-stopped -p 28967:28967 -p 14002:14002
-e WALLET=“wallet”
-e EMAIL=“email”
-e ADDRESS=“ip:28967”
-e BANDWIDTH=“8TB”
-e STORAGE=“1.7TB”
–mount type=bind,source="/home/mishanstvo/.local/share/storj/identity/storagenode",destination=/app/identity
–mount type=bind,source="/mnt/storjhdd/storj",destination=/app/config
–name storagenode storjlabs/storagenode:beta
1 Like
Okay, the run command looks good to me. Have you verified that the drive is being properly remounted on reboot? Do you see any errors in the logs when you start the node?
Im seeing a trend now something to do with the Debian this could be a bigger issue.
docker logs --follow --tail 100 storagenode ?
Agreed. Although the circumstances for the current cases (I count 3 similar) are all slightly different. Debian does seem to tie them together.
To see the beginning of the logs you will have to run docker logs storagenode and scroll back to the top. Your command will show the last 100 lines of the logs and follow the output.
I think if everyone has updated there linux distro we could pretty much confirm this.
I am running a different version all together:
Operating System: Debian GNU/Linux 9 (stretch)
Kernel: Linux 4.4.202-1237-rockchip-ayufan-gfd4492386213
Architecture: arm64
The problem in the scrap sqlite database is that it falls apart with every sneeze or hangs and locks on updates.
Dear developers! Allow at least to move databases to SSD to minimalize brakes and locks. This is one line in the config that will make life easier for many operators!
6 Likes
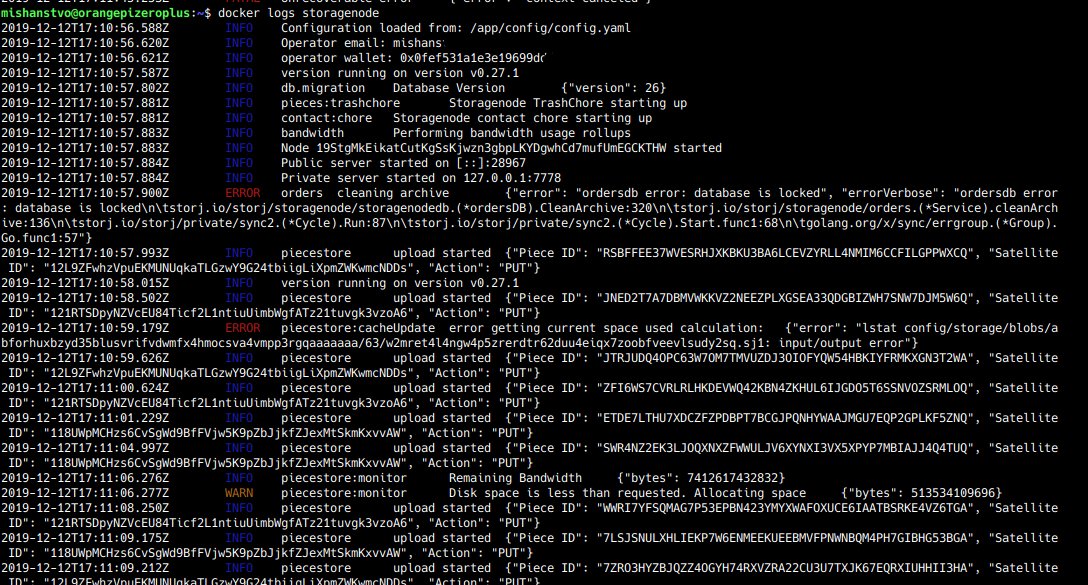
First thing I see was your allocating more space then you have you should change the setting so you dont get that error anymore. Normally the node wont even start if you allocate more space then you have though. I dont see any other problems other then the locked database which is not a big deal it goes away. The cacheupdate error im not sure what causes this though.

My next question is have you updated your linux recently?
no, i dont updates. I update the system only during installation.
Ok and when exactly did you start running this?
before installation storj
Please show the result of the command:
ls -l /mnt/storjhdd/storj/storage