That’s a very thoughtful, easy to grasp description Toyoo.
I hereby award chew 5 1/2 cents, and a like ![]()
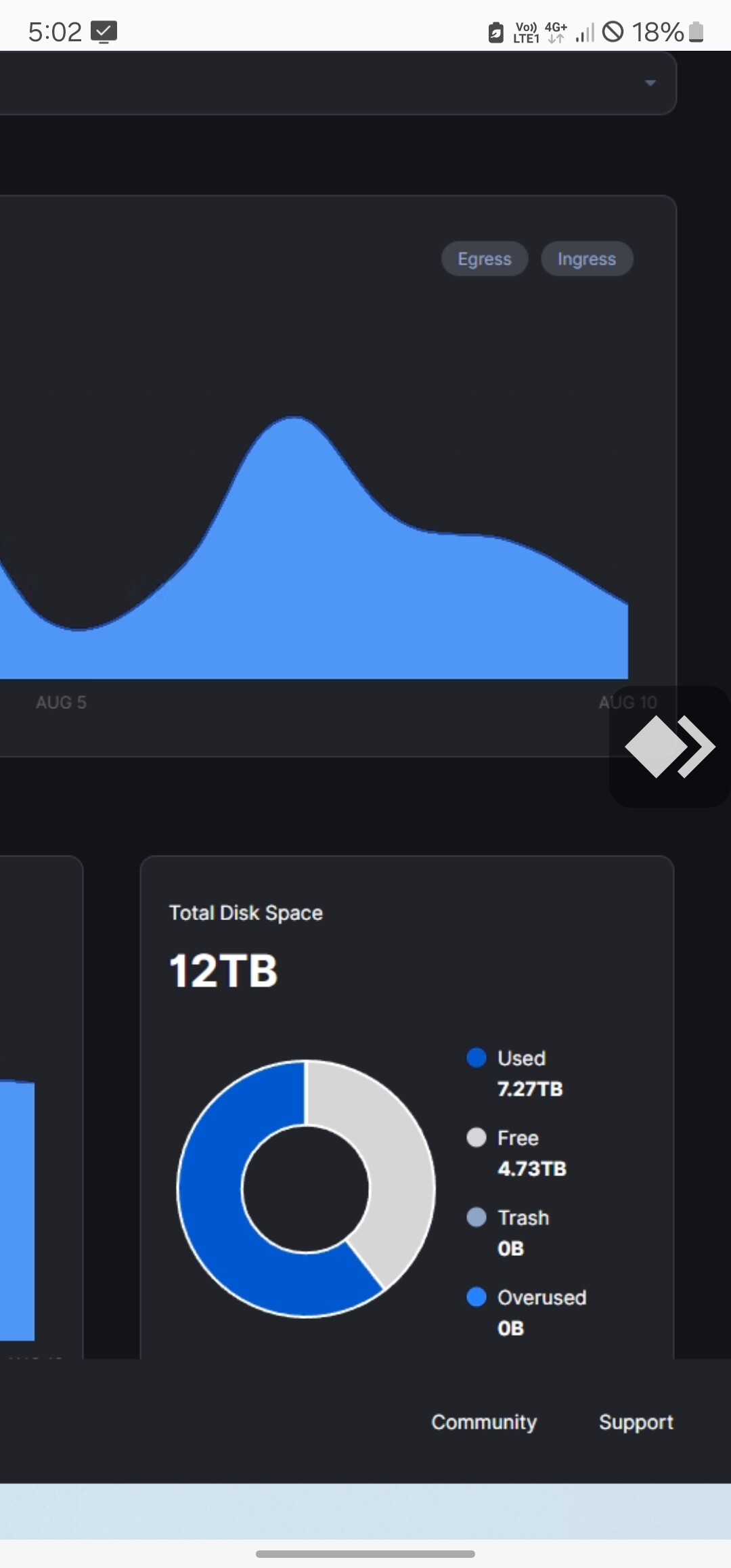
Saw this already in other post, just wanted to brag about it since everyone got lots of trash ![]()
We have a possible fix open for review: https://review.dev.storj.io/c/storj/storj/+/13789
I am going to install that on one of my nodes to get some early test results. Tomorrow would be the new release cut. It is a risk (breaking my test node) and for the current 64 MB uploads on SLC it makes no sense. However the moment customers sign up and start uploading with the file mix we simulated earlier I would have to increase the priority by a lot. I don’t have controle over customer signups but I can reduce the time it needs to get this PR merged and rolled out.
And my node is begging for these kind of tests anyway. It wants to be treated like a real QA node. It was already looking into drugs. I better keep it busy to make sure it has no time to even think about it ![]()
Can I install a beta on Linux docker node too? I got a node, that I think got hit hard (I think 10+ TB wrong) and want to test, if something will fix it soon.
That sounds like a smart improvement: and exactly the type of housekeeping you can offload to the filesystem. Save databases for the tasks that need to be clever.
This fix isn’t going to help you. It can’t recover the lost TTL entries. What this fix can do is make sure 30 days after rolling it out the cleanup will work better.
Can I kindly request file not found errors be suppressed on TTL cleanup. It’s pretty clear this append only method would make it impossible to remove entries. Which is fine, but the long error lines are super wasteful when files aren’t found. And if this is the way it’s intended to work when data is removed before the TTL, it certainly isn’t an error.
With “fixes the issue” I mean collect uncollected garbage. But I can wait longer.
Again for the next 30 days there will be no change in behavior. This fix isn’t going to clean up any garbage. It will make sure there is less garbage to deal with after 30 days.
I have multiple nodes with similar issues, and I believe that the test data with TTL expired and was not deleted, and at the same time, the Bloom filter cannot clear them


@littleskunk does this mean the fix won’t be in release v1.111, but possibly in v1.112?
We can still cherry pick it onto the release branch.
Yes, I’ll be sure to take that out (or move it to DEBUG priority or something). Good catch.
I like it. One nitpick to a comment:
// SetExpiration sets an expiration time for the given piece ID on the given satellite. If pieceSize
// is non-zero, it may be used later to decrement the used space counters without needing to call
// os.Stat on the piece.
The inode will have to be read by the OS anyway to remove the file: how do you remove a file without figuring out how many data blocks to set free?
I would also be worried about the default size of the LRU cache, 1000 is close to a popular default of 1024 of max open files per process on many systems. Though with golang liking I/O they might have solved it in a different way ![]()
It’s been a few weeks since we filled out that form about BFs not clearing enough data, and I’m still noticing my nodes are full and holding onto what seems about 50% of uncollected data. While the BFs are coming through and getting processed successfully, the total amount of lingering data doesn’t seem to be shrinking as much as I’d hoped.
Does anyone have any insights on the findings from @elek’s report? If the BFs are indeed working as expected and should be more efficient now (since they should be smaller, given I shouldn’t be storing that much according to the satellites), when might we see this extra data finally start to clear out?
It’s really important we get this sorted so we can free up space and get back to accumulating more paid data. Thanks so much for any updates!
Me too. 50% in basic ext4 nodes. 40% in cached zfs+l2arc.