This is ZFS on Linux with default settings with the storage node.
So, the default setting on ZFS is good but not optimized for the storage node. All my previous results it was ZFS on FreeBSD that I optimized for storage node. Also, I have ZFS on Linux that also was optimized, and this system also not using SLOG. To reproduce your situation, I bring a new system with Debian 10 + ZFS with evrything by default and it used SLOG during writes.
thats odd, so only debian utilizes the slog… seems like a bug then maybe… the ZoL stuff has been used for making some new features to the FreeBSD version of ZFS, maybe something got broken…
from my understanding the OpenZFS 2.0 will merge both FreeBSD and ZoL into one branch or something like that if i understood it correctly.
even if the slog feature was broken who would really notice right away it basically a backup feature for a filesystem that in theory shouldn’t need it… and in most cases the data lost without it is like in the a few mb or kb range… ofc in a 10gbit network system on fulltilt that could be upwards of 6GB in the 5 sec it takes for it to flush pr default… of people running at those levels would have reduced the flush time so maybe 1gb… and then there is the whole would very modern hardware have PLP if so they might actually save the data without the slog…
so i’m my uneducated opinion the slog could be broken in the BSD versions, even tho it does sound kinda unlikely… or it simply has a way to keep track of if the data reached the drives fast enough to not bother with the slog… since its basically only there to protect against cache / ram data loss and such.
i could see that as a minute optimization the linux democrazy might have glossed over in favor of having a stable system instead.
so yeah that might be where i would put my money… this time xD the BSD version of ZFS is simply more advanced and can tell your drives have gotten the data fast enough to not bother with the slog… ofc then it sort of make the slog a bit more redundant than it already was
i’m also on debian. also pretty much default here… aside from sync=always and 32k recordsize atm… xD and ashift 12
So what were your optimizations that made your normal system not use SLOG for storagenode?
I’m also using zfs on linux with ubuntu 19.04 with default on everything except recordsize.
Seems strange that there is a configuration that prevents the usage of a SLOG for sync database writes…
You are right about your graphs, I didn’t look at the other ones, sorry.
yeah yeah… my point is, it is used consistently and changes the write pattern of the hdd visibly, even if the slog gets only 10-50 operations/s. The DBs dont need more apparently.
yeah i atime i’ve turned off… exec is just for execution… but i suppose on the storagenode blobs folder or such it might make sense…
xattr i haven’t checked… but yeah it is a hog for resources i’ve read… extra attributes
what do acl and relatime do?, i’m already on zle copied my entire storagenode to get that stamped through on it…
@Krey
have you set autotrim=on if you use ssds that should give you a 30% performance increase
well the ssds keep my slog and my l2arc… so no real loss there if they wear out it’s quite safe…
i also allocated 25% additional unused space on them as to limit their wear
and they are old so meh… thus far it’s been running for a month with no ill effects.
O.O
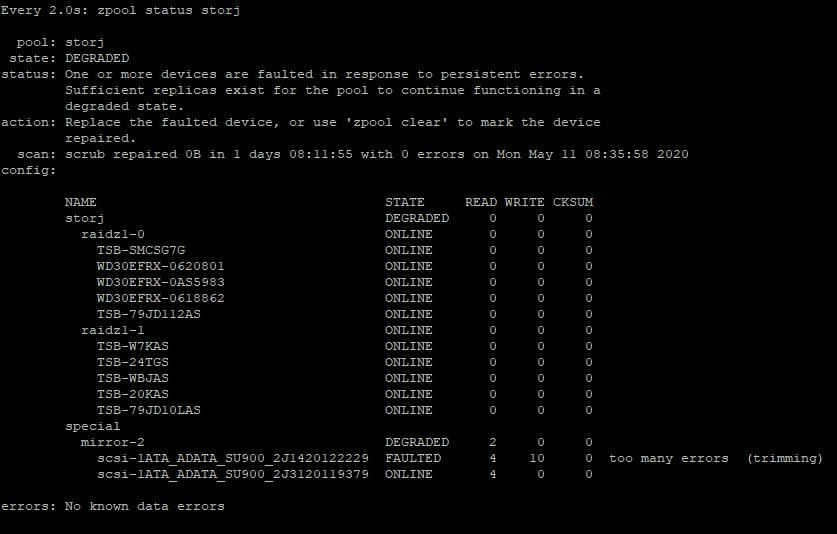
are you insane you do know that special devices for meta data kills the pool if they get corrupted right… and you cannot remove them…
so if that is your current pool you should seriously think about getting those special devices under control.
this errors apears only when trimming. smart clear and contains 0 errors. looks like this is timeout issues.
Whats why i turn off autotrim.
I think to add a tripple sdd to this mirror with other brand.
i can see why you would want to run with autotrim off… lol
you sure the devices support trim… i seen a couple of people recommend strongly that devices needed to support trim…
i think mine trims stuff like … well my iostat -l says the trim wait is 42 ms… so i guess they wait that long xD
trim is the special device command BLKDISCARD. Without support this you never see “trimming” in zpool status.
This ssds not bad. It have dram and slc cache. i have it more than 10pcs and never get troubles with it until this case.
yeah you shouldn’t see it trimming, but i think the developer said it could happen, even tho he tried to avoid it… and it does seem like something fairly recently added…
but i duno… think he mentions in this… i found it quite interesting, but kinda new to the whole opensource thing, so maybe it’s not as new as i think.
one thing about zfs i really don’t understand… if why one can remove like mirrors as top level vdev’s but one cannot remove a drive added as a top level vdev… nor raidz
what makes mirrors different in such a way… that only they can be removed.
seems like something that i might actually dig into zfs just to try to solve or figure out atleast some of the reasons why it is like that… it doesn’t make any sense in my brain lol
i assume this is in relation to the storagenode dataset…
or is there good reasons to turn it all off on all datasets… the acl sounds pretty useful? and i duno if xattr is used for anything in debian…
oh and are you running
special_small_blocks for your special devices… duno how well this works with meta data tho… but i assume meta data might run best with small blocks… hench giving a reason for the feature or anything thoughts on that?
matadata always writing to special device when it is added to a pool. it regardless special_small_blocks.
special_small_blocks options set a size of blocks that (less or equal) goes to special device regadless main pool devices.
yeah i was just wondering if you ran 512 block on the special devices and then … maybe 4k on the pool…
depending on what the special device supports ofc… i guess it might not matter much for modern ssds… not much anyways… but still there would be extra IO to be gotten there, which since you use special devices must be pretty important, for searching for whatever indexing stuff with heavy utilization of metadata you got.
acltype and relatime is off in proxmox but default it seems.