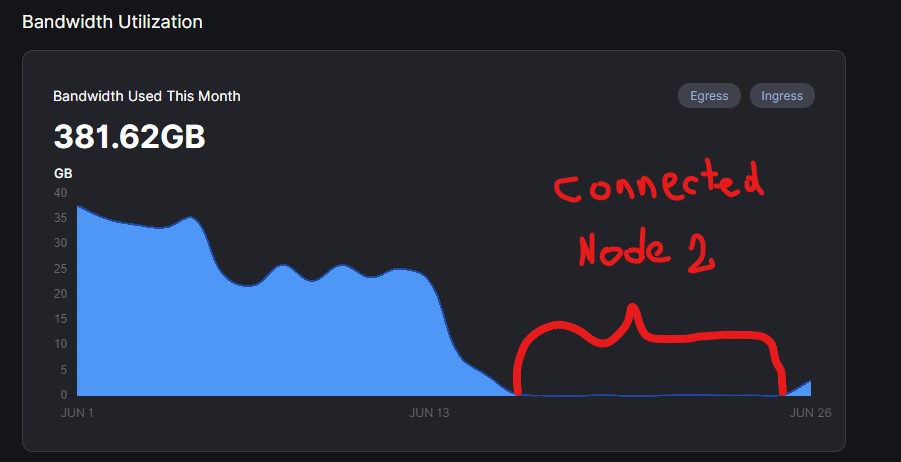
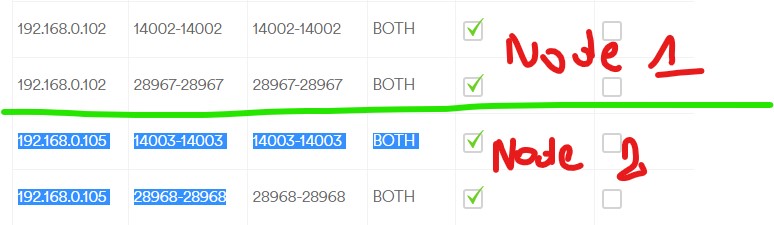
Log:
-----------------------------------------------------------Logs Node2---------------------------
@storj_node_2:~$ screen
JEW3X2BRHTAC6W35L6CYS5YAQLFKJRUMOWZJCNV46MSM6B4WA"}
2021-06-27T16:33:37.601Z INFO piecedeleter delete piece sent to trash {“Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Piece ID”: “RTNGVVGK5MT36LGACLQ5PV2A2YMVRNQHKS6LYMIMUHRS3QZH2MGA”}
2021-06-27T16:34:13.009Z INFO piecestore upload started {“Piece ID”: “4PSY4S3PD4KDJCPS6ASITI6TZZJP5MGFEFY2ZDBTLY36SOZ2ZIBA”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Available Space”: 6964070917632}
2021-06-27T16:34:13.385Z INFO piecestore uploaded {“Piece ID”: “4PSY4S3PD4KDJCPS6ASITI6TZZJP5MGFEFY2ZDBTLY36SOZ2ZIBA”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Size”: 181504}
2021-06-27T16:34:18.547Z INFO piecestore upload started {“Piece ID”: “YJSYESJ6QBYEB4EABUXL2YDU4I3RV3HZTDVKFVNFPMULLJQBANPA”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Available Space”: 6964070735616}
2021-06-27T16:34:18.892Z INFO piecestore uploaded {“Piece ID”: “YJSYESJ6QBYEB4EABUXL2YDU4I3RV3HZTDVKFVNFPMULLJQBANPA”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Size”: 181504}
2021-06-27T16:34:18.894Z INFO piecestore upload started {“Piece ID”: “B3Z7TSAXC7YG74VFL54WNQWSHN6MYTKIXHUXGXC24B73ZNRQ2APQ”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “PUT”, “Available Space”: 6964070553600}
2021-06-27T16:34:23.616Z INFO piecestore uploaded {“Piece ID”: “B3Z7TSAXC7YG74VFL54WNQWSHN6MYTKIXHUXGXC24B73ZNRQ2APQ”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “PUT”, “Size”: 362752}
2021-06-27T16:34:57.650Z INFO piecedeleter delete piece sent to trash {“Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Piece ID”: “CWFHRHPACKUCCOKJSSVTRV4ERTZRK566XTEM6Z6ZJL4Y6EDQWCKA”}
2021-06-27T16:37:05.722Z INFO piecedeleter delete piece sent to trash {“Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Piece ID”: “MNWTF5JU5RQ46F7S3MUYG7ABJBYPTWGI67KQRGEWFBPQNGJ72CVA”}
2021-06-27T16:38:06.326Z INFO piecestore upload started {“Piece ID”: “KZYL454PLC3W7CEKR6ET7BZLRGIJDMQHVMVP7AZQWSBUD2F2R25Q”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “PUT_REPAIR”, “Available Space”: 6964070190336}
2021-06-27T16:38:16.408Z INFO piecestore uploaded {“Piece ID”: “KZYL454PLC3W7CEKR6ET7BZLRGIJDMQHVMVP7AZQWSBUD2F2R25Q”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “PUT_REPAIR”, “Size”: 1620224}
2021-06-27T16:38:55.576Z INFO piecedeleter delete piece sent to trash {“Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Piece ID”: “EPDMSB77W3Q7EZLQWBWCZ7L6CTUBI2MUA7IEMFPYKYR324DBWNWA”}
2021-06-27T16:38:55.577Z INFO piecedeleter delete piece sent to trash {“Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Piece ID”: “Y7TDVQX3A3XW5D7C2OCK3GJ6BOLWHONINANCIMJEYWXQRF2FSDQQ”}
2021-06-27T16:38:55.578Z INFO piecedeleter delete piece sent to trash {“Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Piece ID”: “IU3ORNF2CY2WSVF5K5A3WEK3PJT4UKR5BC3WGI4XLDENAA7M6GGA”}
2021-06-27T16:39:14.157Z INFO piecestore upload started {“Piece ID”: “DQ4RATSDNX7SMSOLYCSFXANVKMYLF7OECW7OU5TNIUCDGRDREITA”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “PUT”, “Available Space”: 6964068569600}
2021-06-27T16:39:14.588Z INFO piecestore uploaded {“Piece ID”: “DQ4RATSDNX7SMSOLYCSFXANVKMYLF7OECW7OU5TNIUCDGRDREITA”, “Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Action”: “PUT”, “Size”: 60416}
2021-06-27T16:39:23.302Z INFO piecedeleter delete piece sent to trash {“Satellite ID”: “12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs”, “Piece ID”: “DQ4RATSDNX7SMSOLYCSFXANVKMYLF7OECW7OU5TNIUCDGRDREITA”}
2021-06-27T16:40:23.410Z INFO piecedeleter delete piece sent to trash {“Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Piece ID”: “L6X7P2R6MVZMTVXXPAL5GTHDZ7RHE6TUQZPKMZTKBFPN34FK6L4A”}
2021-06-27T16:40:23.411Z INFO piecedeleter delete piece sent to trash {“Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Piece ID”: “NRJ77KUYPFWZCWD7GRITL5TM3DGCNWMVFYI7DWHYZPR7BDHEMEGA”}
2021-06-27T16:40:47.973Z INFO piecestore upload started {“Piece ID”: “WF2OXZFVFPDW7HEN2ODY3SG4SQKWD5N5NTBJMFHWUFKRXTNPZ3VA”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Available Space”: 6964068508672}
2021-06-27T16:40:48.360Z INFO piecestore uploaded {“Piece ID”: “WF2OXZFVFPDW7HEN2ODY3SG4SQKWD5N5NTBJMFHWUFKRXTNPZ3VA”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Size”: 181504}
2021-06-27T16:40:54.116Z INFO piecestore upload started {“Piece ID”: “EZOVLHPGUHVTKEYBN2ESXEKFJJRYCH4DF5CFCKNBSNXR3ANAKCGA”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Available Space”: 6964068326656}
2021-06-27T16:40:54.612Z INFO piecestore uploaded {“Piece ID”: “EZOVLHPGUHVTKEYBN2ESXEKFJJRYCH4DF5CFCKNBSNXR3ANAKCGA”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Size”: 181504}
2021-06-27T16:42:10.842Z INFO piecestore upload started {“Piece ID”: “WCUS3CY3U5YRFFCUKB64M2WTXHFU63HG7C4EDEHUAYZYDDX4FOAQ”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Available Space”: 6964068144640}
2021-06-27T16:42:11.228Z INFO piecestore uploaded {“Piece ID”: “WCUS3CY3U5YRFFCUKB64M2WTXHFU63HG7C4EDEHUAYZYDDX4FOAQ”, “Satellite ID”: “12EayRS2V1kEsWESU9QMRseFhdxYxKicsiFmxrsLZHeLUtdps3S”, “Action”: “PUT”, “Size”: 181504}
@storj_node_2:~#