You’re saying that 20TBs leaving at once and 20TB leaving at different times in 4TB increments is the same effect on the network? I would assume 20TB all at once would have a bigger strain on the network.
It’s the same amount of repair. And repair workers have so far never run behind. 20TB is ultimately not much compared to what needs to be repaired in total. Besides, repair workers can be scaled up easily when needed. So it’s about roughly the same impact.
Ah. So the only effects would be really to the SNO. In payout lost and node performance.
Well performance ultimately impacts customers too. It’s better to have more well performing nodes. But other than that, yeah.
2 Likes
You’ve not paid close attention…
Again not paying attention. No one is arguing that it is better for the resilience of the network and my payment to have 5 4TB nodes running on 5 4TB disks. That’s settled (minus electricity costs and price/TB of disks, BTW).
The dispute is "What difference does it make to the network and for my payment having one 20TB node or having 5 4TB nodes in one single 20TB disk. Just focus on this.
PS-> The largest disk I own is 8TB. I don’t really have a dog in the fight I’m fighting. I just want to see some evolution of the rules based on reasoning, instead of based on the “number of nodes religion”. Forget about number of nodes, it’s all about TBs.
Repeat after me, TBs, TBs, TBs…
TB TB TB
TB TB TB
My point is there are two conversations going on here. In the one pertaining to your initial question, no one has said that the number of nodes on the disk will have any effect. In the separate convo, theyre saying its better to have 5 nodes on 5 disks than 5 nodes on 1 disk. Am i wrong @BrightSilence?
1 Like
Yes. and the question was mine…
PS-> TBs TBs TBs…
BTW, I didn’t write the name of this thread, just the right question. Arguably, the name of the thread might be confusing…
They agree with you.
[quote=“LrrrAc, post:48, topic:20367”]
Do they?
Then why don’t they write rules that agree with themselves?
Oh, their documentation is definitely old and out of date in many ways. Honestly the only way to know the “recommended” way to run a node is by living in these forums. Its rather stupid for sure. I would just trust Alexey saying
more than anything in the docs.
Maybe with multiple nodes on the same hd you can have performance issues I suppose…
2 Likes
Well, he did say that, but then, why would he insist on the rule one node per disk?
Sure, there could exist some overhead traffic and/or processing related to the number of nodes. In that case, a rule stating the minimum size of a node should be in place (I think there is. Maybe the minimum size should be raised?). Also, it’s obviously bad for the network to loose too much data when one disk crashes. In that case, a rule stating the maximum disk size should be in place.
What does not make any sense is to say that 5 4TB nodes in a 20TB disk is worse for the network than a 1 20TB node in a 20TB disk.
There are three sources of information about Storj:
- The recommendations/rules written in the docs
- The recommendations given by Storj on these forums
- How the system actually behaves when you do something
The three are not always in agreement.
2 Likes
Well, I’ve been through some Storj related IOPS problems, and not because I’m running several nodes in one disk (*).
So far I’ve found that (i) BTRFS is not good to hold Storj nodes. Once a day, for about 45 minutes, some BTRFS process kicks in and sends my IOPS through the roof. Also (ii) some Storj process (file walker?) runs everytime the node is restarted (including node updates), takes 1-2 days to run and also sends my IOPS through the roof.
I have no idea if running several nodes in one disk makes a difference in IOPS. Anyway, if it does, it was not said. And if it does, it should be presented more as an advice to SNOs than as a rule.
(*) Full disclosure, I’m running 2 nodes on a 3 disk raid5. I’m not sure where I stand concerning the rule “1 node per disk”. I could either say (1) I’m running 0.67 nodes per disk (clearly within the rules), or (2) I’m running 3 disks and each one of those disks holds two nodes (3 times outlaw). ![]()
1 Like
What process?
This sounds like lack of adequate caching. You can also disable atime update for the “share” (aka subvolume) you keep your storj data.
There is nothing in BTRFS that makes it inherently worse. It does add IOps for checksums, but a) this can (should) be turned off for storj pool, and b) caching helps offload and serialize random io from/to the array.
Theyll be sharing IOPS so if they run the filewalker at the same time, which unless you have a special startup (I do for this reason) will run every time you reboot your server or down/up your docker stack. Ive noticed it personally increases more than double with 2, etc. But I also ran 1 node on a disk and 5 nodes on a disk, and with startup staggering they work the same as far as i can tell. Same ingess within reason, and same egress within reason. I imagine theres a minimum amount of IOPS that one node needs, and once you run out of that per node, it degrades. And for my HDDs that number is more than 1/5th of their IOPS (not including the filewalker).
I also agree with arrogantrabbit here. My nodes take less than an hour to run the filewalker with nodes of 2-3TBs. Id look into that. I dont have any caching other than the 256mb on each disk so i dont know if thats the cause, but that doesnt seem normal unless your nodes are large or your drives are slow.
I can’t remember the name of the process, but I will tell you tonight at ~12pm. You sound like someone who could help me. Since last node update, that’s the time it kicks in everyday. I know it’s btrfs related because the name of the process has btrfs in it. I should also tell you I’m on a synology NAS. So, there’s that… maybe I should have written “some synology-btrfs process kicks in”.
I don’t know what you mean by “atime update”.
Yep, I realized that later. The Storj storage directory is my volume 1, where all my stuff is installed. When I started a node I was trying to install it in a separate Linux VM. I run into some problems, contacted storj support and the guy told me to just start a docker container and forget about the VM. Naturally born stupidity led me to do just that on the same volume I have all docker containers and all my stuff, and now the node is too big for me to handle it. The volume (or storage pool?) has checksum enabled and now I can’t go back on that.
Regarding cache, I killed my first nvme cache in 1 year when I just gave it away to volume 1. After the funeral I did some math and arrived at the conclusion that a Storj volume can not be cached in a synology (at least, not if it is the same volume where all my stuff is installed). I bought 2 new nvme ssd’s for R/W cache, moved the Storj DB’s to a different volume and gave some cache to it. The results aren’t great. The node stats page loads fast, but the total R/W operations are not that much deviated to the nvme SSDs.
I created a 2nd node just to buy some time and decide on what to do with the, now, 6.7TB Storj directory in my volume 1. So, checksum can’t be turned off and caching doesn’t really help much (I’m not buying super expensive nvme ssds for the task. I gave the DBs volume 5% of the total cache and even then, I’m doing half the maximum write operations I can do to hold the 5 year nvme warranty).
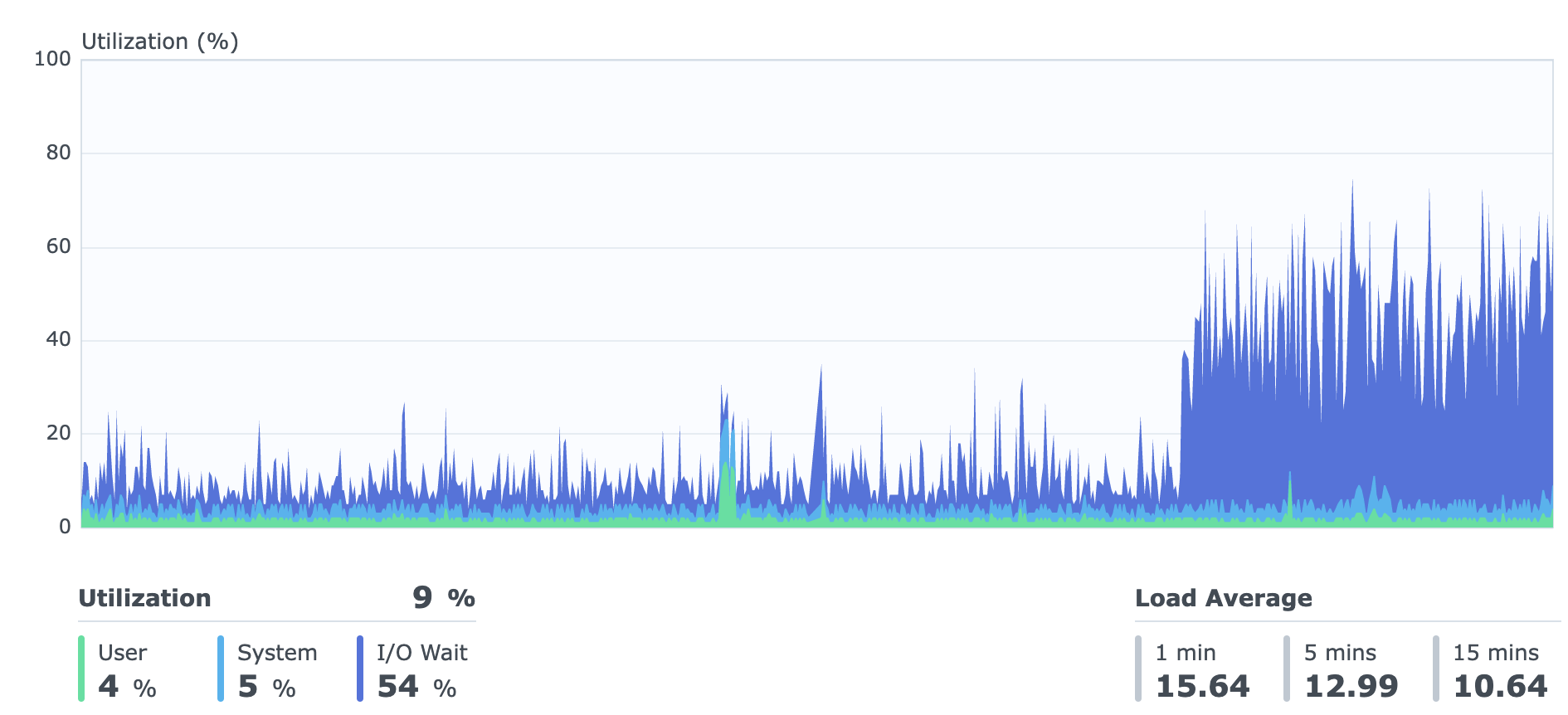
All in all, I did manage to lower the iostats disks report “%util” to ~40% when it used to be >90%… so, not all in vain…
as i found it checks files integrity or something like that, if you use raid it will repair file from second hdd
This is a filesystem worker process, it’s not a culprit; it’s responding to requests that are made my somebody else. Since this is periodically happens every day – check what scheduled tasks may be running (data scrubs? Time Machine backup (it’s IO intensive)? SMART checks (they may make other IO slower). I haven’t used Synology for a while, but if you run synogear install a bunch of tools will be made available, including lsof and other filesystem monitoring. you can try using to find the culprit. For example, if you find SMBD is making a bunch of requests – then it’s likely SMB clients are trying to do somethign)
I mean this: btrfs(5) — BTRFS documentation
noatime
under read intensive work-loads, specifying noatime significantly improves performance because no new access time information needs to be written. Without this option, the default is relatime, which only reduces the number of inode atime updates in comparison to the traditional strictatime. The worst case for atime updates under ‘relatime’ occurs when many files are read whose atime is older than 24 h and which are freshly snapshotted. In that case the atime is updated and COW happens - for each file - in bulk. See also Atime and btrfs: a bad combination? [LWN.net] - Atime and btrfs: a bad combination? (LWN, 2012-05-31).
This disables “last accessed timestamp” updates on files. IIRC on Synology there was a way to configure it, perhaps during sub volume creation (even though it’s a mounting time feature). (Synology calls sub volumes “shares”)
Yes and no. The important bit here is that btrfs allows checksums to be enabled on a very fine granularity, even per-file, but Synology wraps and surfaces this at subvolume level. In other words, it’s not a pool-level setting, and hence, all you need to do is create a new subvolume (.i.e. “Share” as they call it, and that irrationally has annoyed me since day one) without those features enabled; go slowly through the configuration pages, to make sure you don’t miss the atime related settings if there are any there. Then you can copy storj data from your old, checksummed share, to a new, non-checksummed one. Subvolumes are sharing the space so you will not lose anything in that regard.
I would not do that. Unless you are using very fast cache SSDs (i.e. literally the only option is optane) you are exposing yourself to data loss due to write hole, here is a bunch of information on the topic: https://www.reddit.com/r/synology/comments/j10i3q/ssd_cache_1_on_synologynas1_has_degraded/g6we5cr/
And besides, SSD caches maintenance takes away precious ram, which could be used as cache itself instead. I would add ram, at least to 32GB before considering SSD cache, and even then I would be very reluctant to use SSD caching on Synology in any shape or form, until they change the “reboot everything on nvme timeout” behavior.
So, checksums can be turned off by creating new share and copying data there. Create a snapshot before staring a copy, or employ the “multiple rsyncs” strategy as described in FAQ. And turn off atime updates.
Ultimately, I woudl just stick a new drive if you have a spare slot and use that for storj.
1 Like