New SNO here, only been online since April so not sure if this is expected or not, but I’ve noticed that when my node updates (I have it automatic), the disk usage on the dashboard completely drops and doesn’t line up with the disk usage. Seems like at least a dashboard bug in best case, but I’m worried since worst case is there a bug in calculating disk space of data from previous versions, possibly affecting payouts. I’ve heard that being behind can cause ingress to stop and such, but that isn’t happening here, bandwidth use is relatively stable across this day and data isn’t being deleted. Also no failed audits ever, all 100%.
Here’s my dashboard, you can see that since yesterday disk usage dropped, which is when my node updated. Having at least 70GB on disk for the entire day yesterday and today (almost up to 80GB now), the dashboard only shows about 300 GBh rather than the 1.5TBh+ it should be.

Hello @zargonog ,
Welcome to the forum!
The Disk usage is updated by the satellites. I would suggest that you check your logs for failed pings from the satellites.
There also a delay in disk used calculation - after each restart your node starts a filewalker to check used space and update local databases with the actual values.
The information from satellites should be updated not rare than once in 12 hours. So, I would recommend to wait another 6 hours and check your dashboard again after that.
You can read more there:
Ok thank you Alexey, guess I could have just waited a bit longer like you mentioned! Took 2 days for the dashboard to spike up like it says in that FAQ, but it finally got there. So went from 1.5 TBh to 332 GBh to 250 GBh, then today jumped up to 4.38 TBh, which looks about right for making up the previous two days:
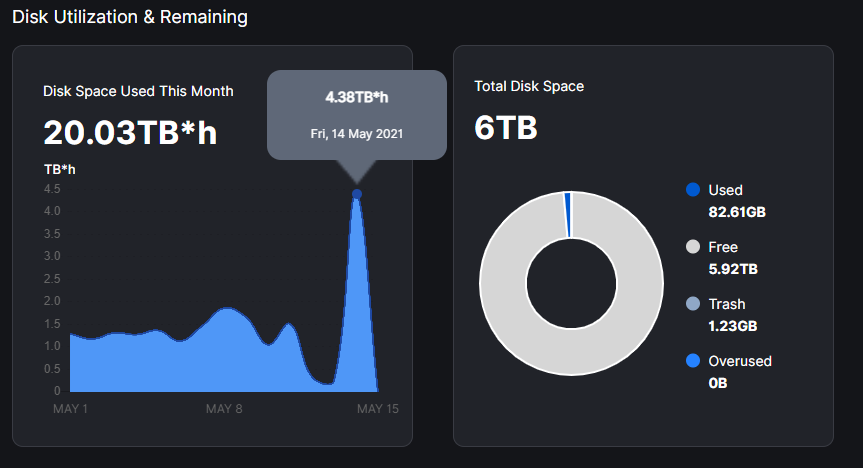
I’m not entirely clear on how restarting the node causes the satellite to miss a tally for 2 days, given that the update and restart only takes a minute at most, and I still have 100% online and don’t see any problems with this in the log files, but I’m not the expert here so I guess I’m good as long as it always catches up!
It’s not related to the restart. My node have this spike too. The Saltlake satellite did not finish rollup in time and you see a result. You can select the satellite in the menu above to see that.