good day, mates.
Over the last week I have seen a drop in audit on most of my nodes.
search logs with docker logs storagenode 2>&1 | grep GET_AUDIT | grep fail gives nothing.
I ask the development team to pay attention to this circumstance. Last week I got a disqualification on three of my nodes and if it goes on like this I will be left without nodes, 2 years of work will be wasted.
what can I do to diagnose this issue?
node version is v1.22.2
I run nodes in docker (debian 10) with ext4 filesystem and dedicated for nodes only hard drives, also i don’t use raid
please help me
2 Likes
You should have redirected your logs by now.
The reason why nothing shows up in your log is because the logs are deleted on every restart.
Since your logs are gone the only way is to file a support ticket and mention your node ID. Support can find out the exact reason why your node failed the audit.
In the meantime check your system for disk errors.
1 Like
@syncamide Also keep keeping a close eye on your logs because even though they might get deleted after each update, if there is a persistent issue with your disks/system you should see failures in your logs eventually. Report back if anything concerning pops up!
Also, double check if your disks can keep up (are they SMR?): an audit could fail even though data is there if the node doesn’t manage to respond within 5 minutes to the satellite.
topcould be used to see if there is a lot of IOwait.iostat -x 2could come in handy too, to see which disk is stalling, if any.
guys,
- first of all, I have turn on logging right now, and I will save it for now
- my drives are not SMR
- filesystem is not corrupted
I will return when I catch audit dropping again “with logs saved but without any failed audits in it”
thank you all
here is it: audit dropped from 87 to 80 on saltlake.tardigrade.io
logs with DEBUG level: DropMeFiles – free one-click file sharing service
any ideas what it might be?!
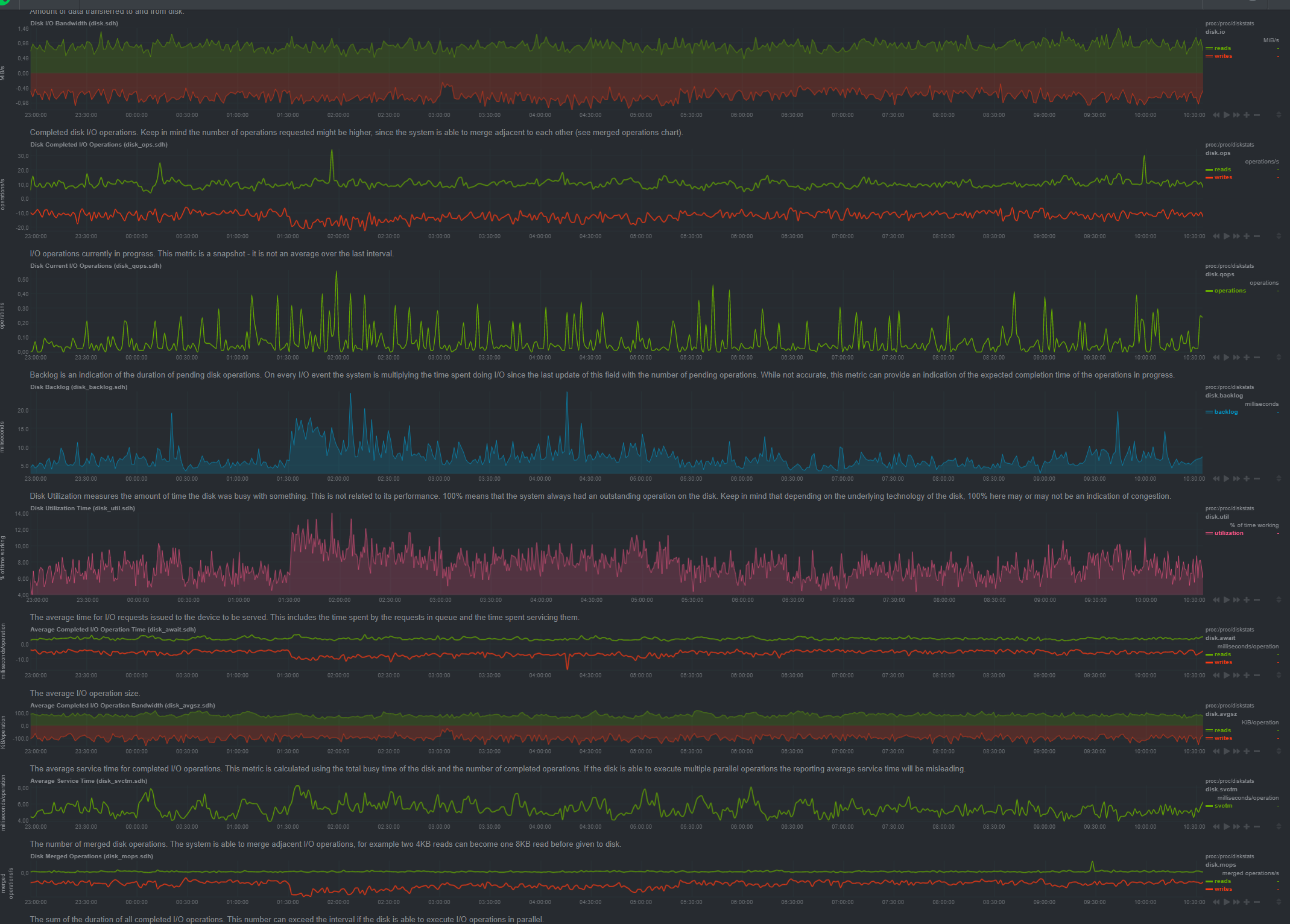
disk stats for that period:

2021-02-28_10-48-16|690x494
{kind=link}
I see basically 3 kinds of errors in your logs:
- “use of closed network connection” :
{"log":"2021-02-27T19:42:28.906Z\u0009ERROR\u0009piecestore\u0009download failed\u0009{\"Piece ID\": \"XUFH3MQ2TCYKBEIQ3FNQRLRQMYTPISHAR2TZQCQXIZJEYBERYACQ\", \"Satellite ID\": \"12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs\", \"Action\": \"GET\", \"error\": \"write tcp 172.17.0.2:28967-\u003e10.0.10.254:58196: use of closed network connection\", \"errorVerbose\": \"write tcp 172.17.0.2:28967-\u003e10.0.10.254:58196: use of closed network connection\\n\\tstorj.io/drpc/drpcstream.(*Stream).pollWrite:228\\n\\tstorj.io/drpc/drpcwire.SplitN:29\\n\\tstorj.io/drpc/drpcstream.(*Stream).RawWrite:276\\n\\tstorj.io/drpc/drpcstream.(*Stream).MsgSend:322\\n\\tstorj.io/common/pb.(*drpcPiecestoreDownloadStream).Send:1089\\n\\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download.func5.1:580\\n\\tstorj.io/common/rpc/rpctimeout.Run.func1:22\"}\n","stream":"stderr","time":"2021-02-27T19:42:28.908476001Z"} - “context deadline exceeded”:
{"log":"2021-02-27T19:47:02.101Z\u0009ERROR\u0009piecestore\u0009download failed\u0009{\"Piece ID\": \"H6LNV4N7J2TBCRHT7SLR7VLJKCH63IGNRU7VEXOXMHMYJPMMZLLA\", \"Satellite ID\": \"12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs\", \"Action\": \"GET\", \"error\": \"context deadline exceeded\", \"errorVerbose\": \"context deadline exceeded\\n\\tstorj.io/common/rpc/rpcstatus.Wrap:74\\n\\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download.func6:628\\n\\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Download:646\\n\\tstorj.io/common/pb.DRPCPiecestoreDescription.Method.func2:1004\\n\\tstorj.io/drpc/drpcmux.(*Mux).HandleRPC:29\\n\\tstorj.io/common/rpc/rpctracing.(*Handler).HandleRPC:58\\n\\tstorj.io/drpc/drpcserver.(*Server).handleRPC:111\\n\\tstorj.io/drpc/drpcserver.(*Server).ServeOne:62\\n\\tstorj.io/drpc/drpcserver.(*Server).Serve.func2:99\\n\\tstorj.io/drpc/drpcctx.(*Tracker).track:51\"}\n","stream":"stderr","time":"2021-02-27T19:47:02.102336732Z"} - “unexpected EOF”:
{"log":"2021-02-27T20:38:28.128Z\u0009ERROR\u0009piecestore\u0009upload failed\u0009{\"Piece ID\": \"74L2RNOSBHSZU66KR3O7SUN4LPOOUKUPI54XY6QARXUKTXBOQXGQ\", \"Satellite ID\": \"12L9ZFwhzVpuEKMUNUqkaTLGzwY9G24tbiigLiXpmZWKwmcNDDs\", \"Action\": \"PUT\", \"error\": \"unexpected EOF\", \"errorVerbose\": \"unexpected EOF\\n\\tstorj.io/common/rpc/rpcstatus.Error:82\\n\\tstorj.io/storj/storagenode/piecestore.(*Endpoint).Upload:325\\n\\tstorj.io/common/pb.DRPCPiecestoreDescription.Method.func1:996\\n\\tstorj.io/drpc/drpcmux.(*Mux).HandleRPC:29\\n\\tstorj.io/common/rpc/rpctracing.(*Handler).HandleRPC:58\\n\\tstorj.io/drpc/drpcserver.(*Server).handleRPC:111\\n\\tstorj.io/drpc/drpcserver.(*Server).ServeOne:62\\n\\tstorj.io/drpc/drpcserver.(*Server).Serve.func2:99\\n\\tstorj.io/drpc/drpcctx.(*Tracker).track:51\", \"Size\": 65536}\n","stream":"stderr","time":"2021-02-27T20:38:28.130036226Z"}
But I’m not sure why any one of those would make audit scores drop… ![]()
From your logs I can say that it has audits every 8 minutes in average, but you have several lacks of audits with length more than 25 minutes.
It looks like your node answers on audit requests but cannot provide a pieces in time, even cannot log the fact.
@Pac PUT and GET are not related to audits. Only GET_AUDIT is matter.
1 Like
That’s why I said I wasn’t sure why these would make audit scores drop ![]()
Thanks for the clarification though ![]()
I’m wondering something though, I see the exact same number of download started.*GET_AUDIT as the number of downloaded.*GET_AUDIT.
If something was wrong with audits, shouldn’t we see more “download started” than “downloaded” as some would never be fulfilled?
Yes, if node is able to log that. Seems it somehow hangs for a while and even cannot write logs.
If it doesn’t answers on audit requests then the online score would drop, not audit score.
To drop an audit score the node should be online, answers on audit requests but unable to provide a requested piece for audit or completely fail it with “file not found”. In case of any other errors will fall an suspension score.
ok guys, let’s try to assume that the node hangs for some time:
if so, such hangs should certainly affect the number of successful downloads/uploads
I just ran the successrate.sh script right now
of course, I can’t say for sure, but it seems to me this hypothesis looks unlikely.
here’s the result:
========== AUDIT ==============
Critically failed: 0
Critical Fail Rate: 0.000%
Recoverable failed: 0
Recoverable Fail Rate: 0.000%
Successful: 541
Success Rate: 100.000%
========== DOWNLOAD ===========
Failed: 132
Fail Rate: 0.937%
Canceled: 4
Cancel Rate: 0.028%
Successful: 13946
Success Rate: 99.034%
========== UPLOAD =============
Rejected: 0
Acceptance Rate: 100.000%
---------- accepted -----------
Failed: 15
Fail Rate: 0.106%
Canceled: 131
Cancel Rate: 0.929%
Successful: 13959
Success Rate: 98.965%
========== REPAIR DOWNLOAD ====
Failed: 0
Fail Rate: 0.000%
Canceled: 0
Cancel Rate: 0.000%
Successful: 1033
Success Rate: 100.000%
========== REPAIR UPLOAD ======
Failed: 0
Fail Rate: 0.000%
Canceled: 3
Cancel Rate: 0.103%
Successful: 2921
Success Rate: 99.897%
========== DELETE =============
Failed: 0
Fail Rate: 0.000%
Successful: 63879
Success Rate: 100.000%
Unfortunately it is not related. When node hangs - it simply do not log the event and then timeout and nothing to write.
Do you have spikes in memory usage?
No, I have no spikes in the activity of either hard drives, processor, or memory
Netdata stats confirm this
one more node drop to 67
I think this one cannot be saved, although I turned it off just in case…
I don’t know what I hope for…
logs for the curious: https://dropmefiles.com/ycAyc
mah, i am not sure if I am experience the same lately. after runing node 3 or more days Audit go down, If I restart pc it is fine again.
Looks like stalling node and it starts to fail audits because of timeouts (3 times with 5 minutes timeout for each piece).
one more node disqualified
I still do not have any information in the logs from which I could understand what is wrong.
audit falls-grows, eventually drops below 60 and the node is disqualified.
@Alexey, please tell me if there will be some kind of entry in the logs (DEBUG level), if the checksum of the piece successfully submitted for audit does not converge when checking on the satellite side?
No, as far as I know
very interesting… 20 chars…
i had issues with audit as well mostly after 48h of runnng the node. This cost me another disq from 1 satalite.
But now I guees it runs normaly, w/o audit droping. Node uptime is 60h already.
All I did on this hdd was to delete, made more free space on hdd.
There’s always a reason for audit failure. The log files should show piece, file or folder can’t be read.