US1 started acting strange for me a couple days ago. It claims a couple nodes are offline (while AP1/EU1/Saltlake say those nodes are fine). Those nodes show they’re online in a coupletools (including that QUIC is working) AND those nodes are still uploading/downloading data managed by the US1 satellite!
Like… how can I still be serving data for US1-related customers, and making the other three satellites happy…but the US1 satellite thinks the nodes are offline? I think they’re making other upgrades now (bloom filter code?) so I’ll wait a few days to see if it clears up…
To be honest it is not like it was correct before.
For me it has been for more than a month now and it is getting worse every day.
If nothing changes until end of this month all of my nodes will go offline.
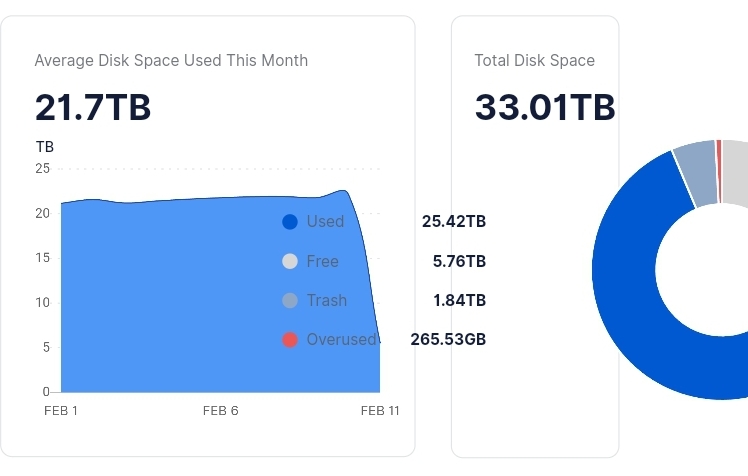
As an example my smallest node that hat constantly over 3.2 TB used space. But the average is reported and paid as 2.5 TB.
So if you can not calculate correctly or do not want to pay us according to your usage it will be a fast descision. At in the end it is still a business for all of us. But one party is trying mess around with the other…
Hi and thanks for the welcome.
I have looked up the logs and all filewalker processes returned finished successfully with 0 pieces skipped.
So looking fine there.
@Alexey
Why has the topic on strange behaviors of the US1 satellite been merged in this one? This way everything just should be merged in a big STORJ-topic.
In my opinion a non-reporting satellite (up-front known cause), is quite different from having more disk usage than reported from a given satellite (up-front unknown cause).
Besides, the line of the topic feels a bit strange now, like people are discussing different things along each other. Just randomly ignoring intercurrent posts on a different subject.
Nevertheless, any updates on why the US satellite acted weird?
I do not see any weird behavior of that satellite on my nodes, what should I looking for (except a disk usage discrepancy, which is affecting all satellites)?
I think you’re not taking us serious on this one. Because literally seven of my nodes had the same problem. I was actually looking to report it, when I saw the problem was already been acknowledged by others.
It wasn’t a disk usage discrepancy, but a late reporting issue. The same charts of the same node I posted above look now this way.
All satellites (of course with the strange ‘today overreporting’-glitch never solved):
As I already suggested in my first post on the issue: it corrected itself within 24 hours, but never happened to me before and apparently also not to many other members.
Usually a discrepancy is because of old remnants on the nodes from decommissioned satellites or unfinished filewalkers, a situation needing some research. In this case, up front it was very clear it was a glitch of the us1 satellite. And I’m curious to know whether there’s a reason why only this satellite apparently gave some people reason to worry.
Again: it was not a usual disk usage discrepancy, it was a (me at least) never before occurring reporting issue only attributable to the us1 satellite not reporting the used space.
I see. This is usual thing when the tally didn’t finish in time (took longer than usual), it’s not a glitch, but likely more segments to scan. We do some autoscaling if that happen to speedup the tally.
Glitch is when it didn’t report for several days, but I didn’t see such a thing on my graphs.