might be some old data that gets downloaded now
it depends on what the customer uses Storj for (probably mostly testing right now but that’ll change soon hopefully).
might be some old data that gets downloaded now
it depends on what the customer uses Storj for (probably mostly testing right now but that’ll change soon hopefully).
my node is 4 months and 1 week now i think… so not that old really…
@kevink kinda makes one wonder if the satellites just have a timeline for how much test data to download… i mean at these rates … how much data did it have until recently?
Did you experience the “network wipe” ?
i think I seen this term and I assume it happened when Tartigrade started the “production phase” (at the beginning of the year maybe) or something like that?
If yes, then probably your data are less old than node itself…
Am I right? or did I made stuff up? ![]()
it was running on a 2tb or 1tb hdd until recently and then got migrated to a new pool because of hardware issues…
I never really saw this. My first node’s been running since Aug 2019. In the chart below, I have “Available space” plotted over time. There are two points to mention. My node was first started with 3.6TB available on a 4TB HDD. At point #1, I migrated the stored data to a new, larger 10TB HDD with 8TB available. At point #2, I increased the limit available on the HDD to 9TB. But as you can see there are periods where there’s some data clean up, where available space jumps up a bit, but nothing super significant, such as a “network wipe” at production launch, which was around Jan 2020.
The network wipe was a lot earlier than the production launch. It was somewhere mid 2019 I think. But yeah, my node was there ![]()
But both test satellites saltlake and europe-north joined the network within the last 6 month so it doesn’t really matter if a node is older than that.
I do see some GB egress from other satellites too, which is customer data. That data could indeed be way older and it was like 10GB on some days. So it’s difficult to compare the daily egress if we don’t split it per satellite as customer data is unpredictable.
speaking of available space keep in mind that the log counts the space wrong over time… duno why … maybe it forgets to add deleted back to the available space.
however if one has limited free space let… this can essentially run out without having run out required a reboot of the node for it to recheck / calculate the space left correctly…
doesn’t happen to often, and will most likely get fixed in the near future… but it can stop ingress on occasion…
The last network wipe happened in September, with the first beta launch.
hunted down this one fer ya!
a spike in egress on my 60 seconds chart – 2000kB ~=16Mbits
those kind can get you capped with your upstream. But they are sporadic.
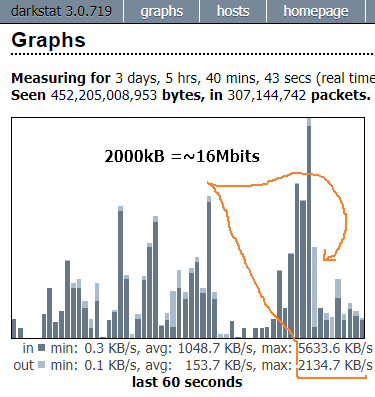
So my internet connection clearly bottlenecks my node but it doesn’t seem to fail that many downloads though and nodes are selected randomly not even in function of their upload speed.
I’m wondering if the speed of the internet connection really has an impact on egress or not.
I got only 12Mbit/s upload and still got lots of egress so it’s not that bad. But at some point it might be a visible bottleneck
i did the math for kevink upload limit not long ago… i think i settled on anything less than a 10tb node and you will on avg not be able to really measure it… however at 20tb it will most certainly be a thing to strongly consider…
alas we cannot really say for sure, because it’s just approximations, only real way to be sure is to keep monitoring and comparing… tho i really should start to look into making that and the math of it an automatic process…
extracting it out of each node is pretty straight forward with a some work and learning on my part… but not sure where it would be best to locate the data… i suppose one could make like a gmail and just dump it on a speadsheet… or something similar… like was suggested by somebody at the beginning of the thread
don’t forget that there is a voting feature on the forum, where you can help select what policies / features should be in the future versions of Storj.
have you mesured power consuption and what servers do you use?
Sorry, but It will be offtopic for this thread, let’s keep it clean.
Can you tell your specs?
How old are your nodes?
How did you manage to fill 60TB space?
what’s your ingress values?
What’s your egress values?
Can you post a picture of your traffic?
Or is it just a hoax?
I have 4 desctop PCs 5-6 HDD per PC. OS on SSD or NVMe and all databases on SSD or NVMe it gives fast responce time. Some PCs are Pendium(last year edition) some I5 about 4-5 years old. 1 dual core pc. And looks like Pentium is more eficient than I5, it have faster buses.
and 1 pc i3 last year edition. All runing windos GUI nodes. about 2/3 nodes are full.
Part of nodes about part of nodes are 9 months old. most HDDs are 4TB.
I have 2 fiber lines with separete providers. All nodes have UPS.
Last month was bad.

chart from this year beause of router is new one.
I have 300/300 mbit connections.
You can look some on rigs thread
Like one of my location
360Watt
This TP-Link work OK, on some points we used them for Video security but, thay work bad when you have lot of small packets. Storj mooving lot of small packets, I use Full Gbit router with 700Mhz quadcore and it go hot.
Can you specify what is your average ingress per day (it can be sum of all PC’s) - looks like currently it is 50-60Mb daily (green) which translates to ~6MB ->1.5MB per node.
I get like 1.5MB on my whole network and I have 1Gb/300Mb fiber
How did you configure your subnet to manage to get 1.5MB per node if IT guys from STORj say that max you can get is one stream of data shared among all nodes in the same network?
