Some people have a dot, some don’t and for some reason yours was below the graph this time.

yeah that was actually difficult to get it to do…
haven’t seen the dot since i updated… but because i wanted to grab the trash, not have my node id and didn’t want to bother to change my resolution to do so… and ofc scroll makes large skips…
apperently the dot is still there… we just don’t get to see it…
okay i got this… you point on the graph and scroll and the dot will split out below the graph…
its still there just on the wrong side of the graph…
lol

Here is my total ingress for 4th:
Normal: 49,57 GB
Repair: 10,18 GB
Total: 57,75 GB
Hi SGC,
May I ask you one question?
It seems that you have around 3Mbits/s average outbound traffic.
I have similar connection (1G down /300M up) but my outbound traffic is like ~60kbits - nowhere near 3Mbits. I also have much less stored data (only 0.24GB not 10GB ![]() )
)
Anyway I was hoping for just more egress cuz for now I would have to multiply storage like 500x to reach your levels of your egress, which seems rather discouraging.
Can you run a script on your log that counts upload success rate? Because I have like 70% “cancelled” uploads, I am wondering how much cancelling your node gets comparing to my node.
Would be much appreciated.
Looks like your node is not fully vetted yet. You can check the vetting process with an
Thanx Alexey!
I will check that later, when I get a chance to sit at my node.
I wonder if my node is not fully vetted because my ingress increased yesterday from “barely moving” (200kbits) to “huge” ~1.2Mbit (6x increase) is it still not fully vetted? is there bigger ingress possible? ![]()
Because now it means that my node will fill up in ~5days, vs 40 days (at the beginning)…
Gosh… I think I will need bigger drive ![]()
While your node is in the vetting, it can receive only 5% of potential traffic from the customers of said satellite. To be vetted on one satellite your node should pass 100 audits from it. For the one node it should take at least a month.
For multiple nodes behind the same /24 subnet of public IPs it can take in the same amount of times longer, as a number of nodes (we filtering out all nodes from the same /24 subnet of public IP to be decentralized as much as possible: all such nodes treated as a one node for uploads and as a different ones for audit and uptime checks).
I would not count on that. Since the node is used by real people, you can’t use the usage stat for any period to predict the next one. It could be almost zero right after a hour.
takes a long time before egress goes up… i’m on my 5th month and it’s been steadily rising, the first few months are very dead in egress… but if one is lucky one joins up when there is lots of ingress.
my upload successrate is not great atm… had it up to 80% a while back, but it’s a pointless number 99% or more of all uploads in logs are actually stored on nodes with even 15% upload successrates… and most likely all the way down… it’s an artifact of something in the code…
========== AUDIT ==============
Critically failed: 0
Critical Fail Rate: 0.000%
Recoverable failed: 0
Recoverable Fail Rate: 0.000%
Successful: 5146
Success Rate: 100.000%
========== DOWNLOAD ===========
Failed: 4
Fail Rate: 0.015%
Canceled: 211
Cancel Rate: 0.769%
Successful: 27236
Success Rate: 99.217%
========== UPLOAD =============
Rejected: 0
Acceptance Rate: 100.000%
---------- accepted -----------
Failed: 8
Fail Rate: 0.008%
Canceled: 44664
Cancel Rate: 44.756%
Successful: 55122
Success Rate: 55.236%
========== REPAIR DOWNLOAD ====
Failed: 0
Fail Rate: 0.000%
Canceled: 0
Cancel Rate: 0.000%
Successful: 21872
Success Rate: 100.000%
========== REPAIR UPLOAD ======
Failed: 0
Fail Rate: 0.000%
Canceled: 8742
Cancel Rate: 43.230%
Successful: 11480
Success Rate: 56.770%
========== DELETE =============
Failed: 0
Fail Rate: 0.000%
Successful: 10448
Success Rate: 100.000%Thank you for your response!
Will have to brace for loong way up ![]()
Thank you for your response!
Will have to brace for loong way up ![]()
P.S. I did some more calculations - your node has ~44x more data than my node and it seems that your egress is around ~55x bigger than mine.
SGC storage-wise : 11TB vs 0.25TB (me) → 11/0.25 = 44x
SGC egress-wise: 3Mbit vs ~0.055 Mbit → 3/0.055 = ~55x
So maybe the difference (11x) can be attributed to age of the node.
Which brings me to this idea:
It might be hard to fill up our outgoing streams - given above values…
You are going to need 133x more data to fill up 400Mbits upload - assumption based on calculation that each TB of data gives ~0.27Mbit of egress)
cool little project ![]() - create this 1330 TB of storage
- create this 1330 TB of storage ![]() -
-
I’m in! ~100 x 16TB HDDs
Recently watched this Linus guy on YT who was building 1PB storage ![]()
Imagine your friends… when they ask you … how much disk space does your computer have? … oooohhhh … just ~2PB … who would count ![]()
i think we usually estimate about 5% of stored data as monthly egress… ofc at this point it’s still mostly test data… so maybe higher or lower when the customer data becomes the bread and butter… but about 5% also seems very reasonable to me… when i think about how much data i keep and what i trash…
i also have redundancy … so really i loose 33% of my capacity to that… and then i have 2 x 6 tb drives i ended up not being able to use for storj… so all in all i got over 60tb in drives… but only about 24tb that i have been able to actually allocate for storj…
the bandwidth usage numbers can be very erratic…like 3 months or so after i started this node… i had like 30mbit avg and high points of 50mbit and peaks of like 100mbit.
that got a almost a month worth of that which really helped getting some data onto the node…
but it is highly erratic… right now it’s been very quite for a good while… but we expect / hope it will pickup again sometime in the near future…
i was a bit of a lemon when i saw all the drive linus got a while back… the video where he builds a pyramid out of them… have you tried calculating the cost on those… if we go with like 15$ which is apperently what fairly large drives can be found at today… then 1pb is 15k$ and then you would want to do redundancy obviously… atleast imo… so in my case that would require 1.5pb so 22500$ of harddrives… then you need the mounts, case, backplanes, controllers, cables, PSU, UPS a couple of servers… and ofc you need to get enterprise stuff, because else you will most likely just blow something up somewhere… costing you even more…
1pb storage is easily a 50k$ setup… if not into the 100k$ range with support, setup …
linus also has an excuse to build those big storage servers, because he uses them in production… and seeing it from that perspective… if you can fill up that big a server, then the money it costs is most likely peanuts compared to what kind of profit you have in year.
we also had a discussion on another thread about how with the current deletes being also about 5% of capacity… then with 2tb of avg monthly ingress, it means that currently it might be impossible to actually get past the 40tb node size, because of diminishing returns, simply the more data you store the more is deleted and eventually you have so much that what is deleted is what you have in ingress each month…
so a 1pb node wouldn’t help any of us here… because of those kind of real world limitations.
didn’t stop me from building so i can expand into hundred and hundred of drives ![]()
hi,
here 1Gb/500mb fiber link :
@zagg
thanks for participating, we need a full day tho…
else the number is not useful… so if you could change it to either 3rd july, 4th july or 5th july
so it correlates with the other data we got…
then it would be perfect…and maybe add a approximate location if you don’t mind.
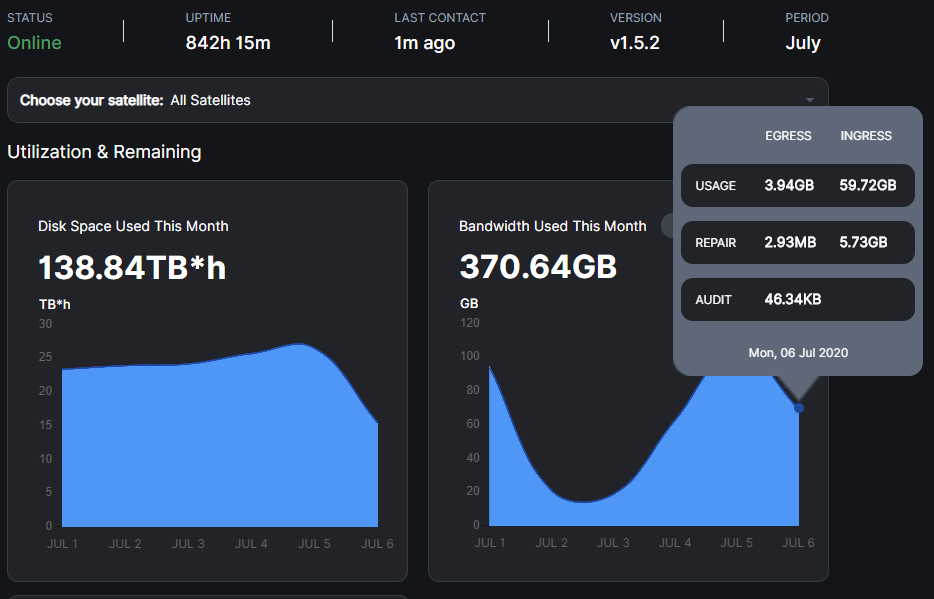
Here is my total ingress for 5th:
Normal: 95,86 GB
Repair: 9,95 GB
Total: 105,81 GB
Location: Frankfurt - Germany
Total # of nodes: 3
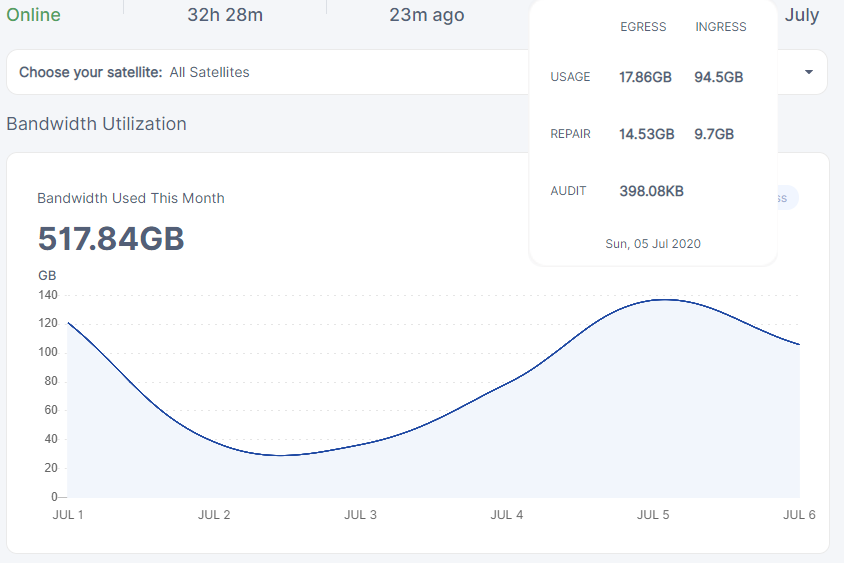
seems pretty damn close… atleast to what i’m seeing… only slightly behind this time… also think i finally got my system stable… ofc will take a bit until that is fully reflected … i think i was still crashing on the 5th… but tomorrow it will be accurate ![]() atleast lol
atleast lol
but looks like we get the same numbers really… but lets keep going and see if it is consistent.
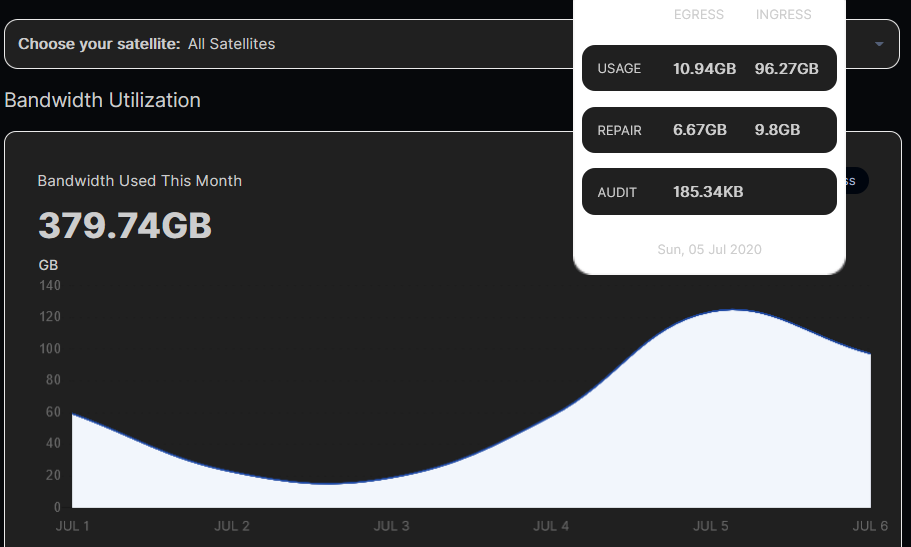
Germany.
Very close to yours
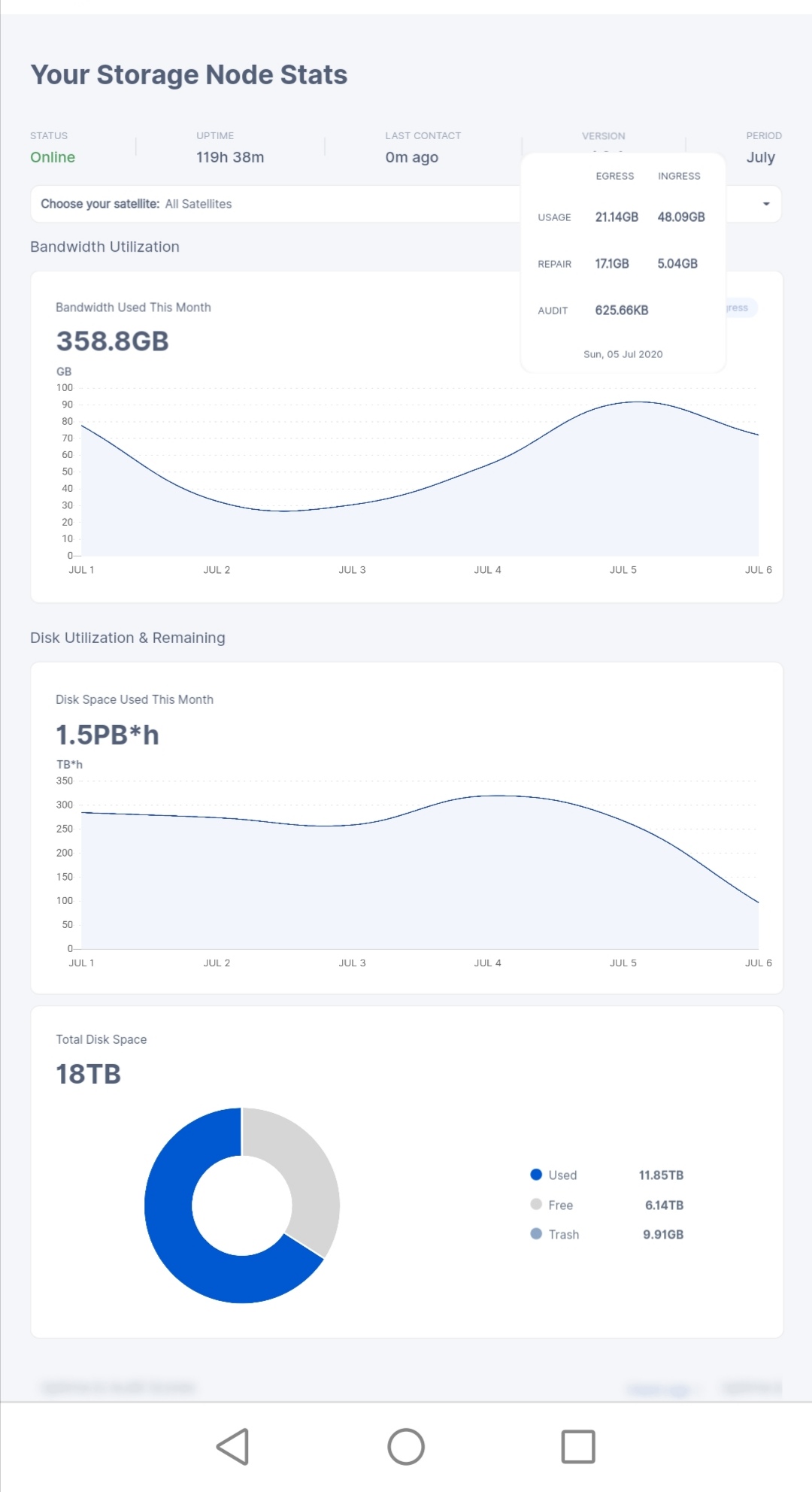

so your total was 96 gb ingress for the 5th of july 48gb on each of the two nodes…
duno if it was my browser or whatever… but because it was phone captures it’s not easy to read on a semi old pc monitor xD
Oooh sorry, mobile screenshot
2x48 gb + repair ingress