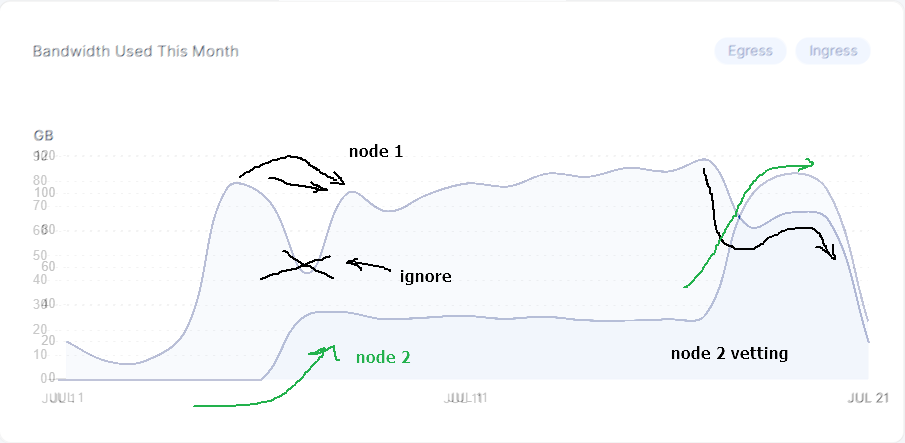
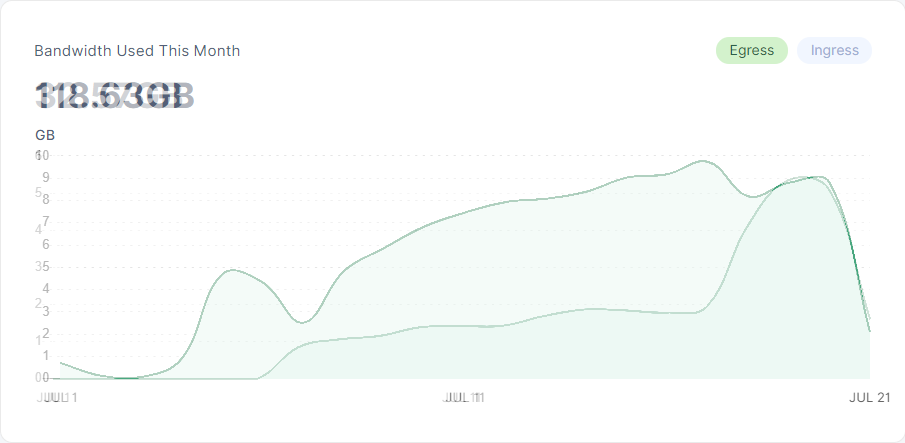
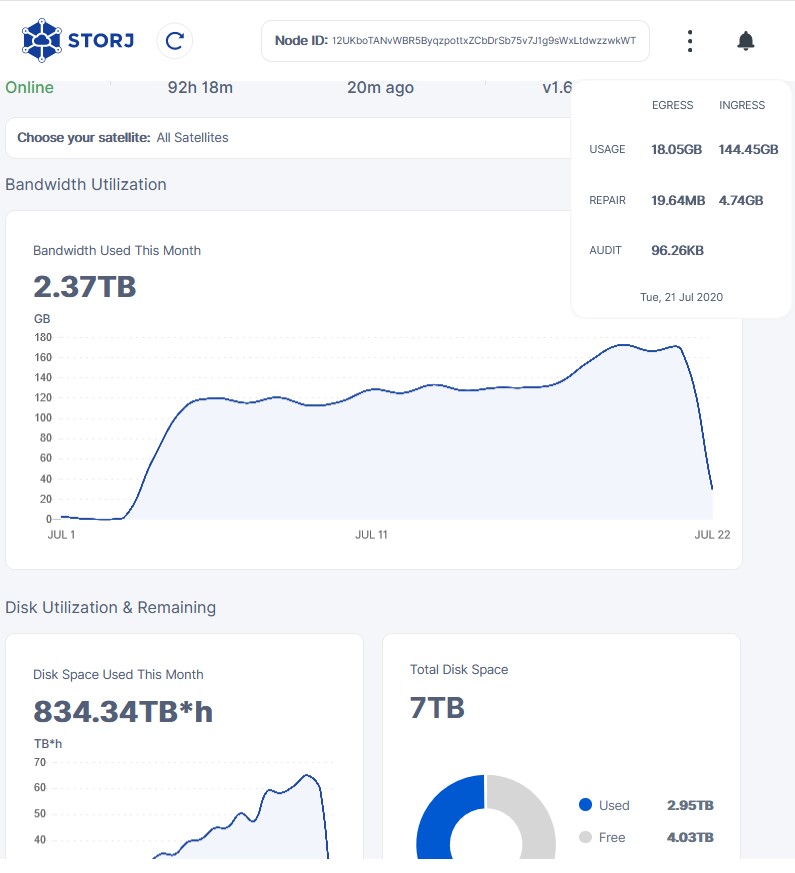
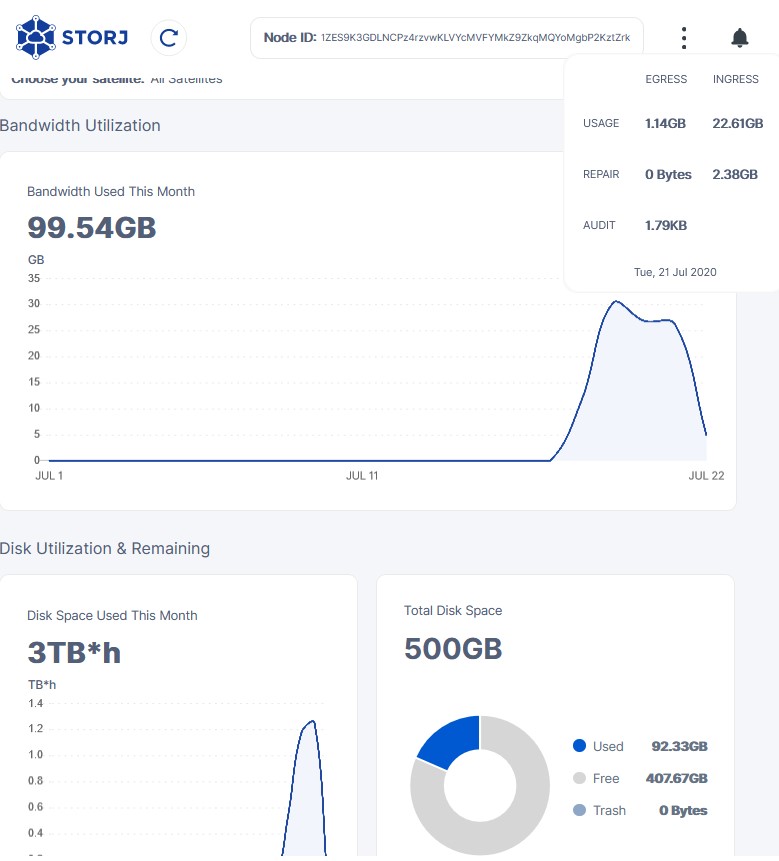
That’s because of new node skewing the averages. It’s like old node fallen from 84kB/s and now is giving ~81kB/s (19GB/2.8TB) and new node given the small amount of held data is giving like 170kB/s. (1GB egress vs 70GB stored).
That behavior stumps me, because why new node gives so much egress when not storing any significant amount of data. It’s like new nodes are prefered over older nodes? (or this is an effect of something)
If you compare those values to “before new node” you will see that older node’s egress went down. (at least for my node it was true)
Not sure if this is the case, probably when amount of files in directories increase, it causes performance issues?
Maybe sheer amount of seeking the file causes those slowdowns? Maybe putting the databases on SSD disk can increase the egress.
hmmm thats kinda interesting because that means the more data a node has the longer it takes and that is long enough that we can see that in the graph …
seems like that process must be highly inefficient, not that it might be easy to optimize it… but there might be a long of performance to gain from that, so far as i can tell…
it’s a bit like when is running brightsilence’s successrate.sh script… on a sizable log file…
not really optimized for that… doesn’t run its work in parallel, which would basically reduce the workload by a factor of 6.
I am noticing similar pattern, yesterday was day up, today little lower.
Date
IngressT
EgressT [GB]
StoredT [TB]
egress ‰
egressT
EgressT [kb/s /TB]
Ingress1 [GB]
Egress1 [GB]
Stored1 [GB]
Egress1 ‰
Egress1 [kB/s]
Egress1 [kB/s /TB]
Ingress2 [GB]
Egress2 [GB]
Stored2 [GB]
Egress2 ‰
Egress2 [kB/s]
Egress2 [kB/s /TB]
18.07.2020
141.28
12.30
1.84
6.69
142.38
77.38
73.88
8.19
1 500
5.46
94.81
63.21
67.4
4.11
340
12.09
47.57
139.91
19.07.2020
158.45
14.14
2.00
7.06
163.70
81.77
80.63
8.79
1580
5.57
101.78
64.42
77.82
5.35
422
12.68
61.92
146.73
20.07.2020
147.85
13.90
2.14
6.50
160.87
75.22
76.37
8.81
1650
5.34
101.96
61.79
71.48
5.09
489
10.41
58.91
120.53
Today my secondary node filled up to almost 100%
We’ll see how egress will behave on “no new data” node.
Question being - what is the amount of storage needed to keep high egress…
(also, if egress is only high when node keeps filling up - egress is combined with “verification/confirmation” data like TCP -ACK packets.)
well it’s data storage… uploading and downloading test data is only viable for so long.
linking egress to ingress makes no sense at all… tho it may seem like it’s linked, when in fact it might be as simple as the more recent the data to more likely it is to be downloaded again… which is something i find a trend even in myself… i more often access recent data than older data…
no big surprise there… ofc the older data i do access i often access in large sequences when getting back to some work i was dealing with at the time of the data upload / stored point in time
so really comparing old data vs new … while interesting, doesn’t really hold much potential benefit, because there is nothing we can change… the advantage of having more data vs having new data … well i got 12tb in a 5 months… how old is new / recent data,…
if we are talking a month then lets say thats 2tb at most… thats 3$ profit a month on the storage alone… and i will make 15$ more with my “older data”
so even without getting any downloaded my system would make 15$ which is 3/4 the value of a tb downloaded, so the 2tb node would need to get a download of 3/4 tb to equal out with a 4 month older node…
so 750gb thats close to a multiple of 3 times to get 2tb… so 33% or 1/3 of all data uploaded to a 2tb node, needs to be downloaded to even be able to compete with the baseline of the a 5 month old node…
my arguement doesn’t account for storage capacity, putting additional limits in place confuses the topic further, just like i consider the internet bandwidth in this can to be unlimited and all hardware to perform perfectly.
new data being better than old data is kind of an urban myth, sure there maybe some statistical truth to it… but again the two doesn’t really compare in reality because of the compound effect of additional stored data.
i don’t think it can apply to reality, sure maybe in rare cases… but 99% or something like that… then more and older data is simply better… no matter how frequently it’s accessed… almost
IM"H"O
another thing with new data is sometimes it will be verified… just like you might open and check your data is working in a new location… that would also give added egress… and is a perfectly natural procedure… you check that stuff is working before you leave it to mind itself for extended periods.
depending on the trust level you have with the “device” or whatever
It could depend on test pattern since most traffic will be from tests. For example if only testdata will be downloaded from the last month then your ratio of egress/stored will be a lot higher the younger your node is. If your node is only 2 month old, half of the data stored would be downloaded. A 6 month old node would only have 1/6 of the data stored downloaded. Therefore younger nodes might seem to be preferred.
However, this is just an oversimplified example and I don’t know if it holds true with all our observations and if the 2 different test satellites are doing different kinds of tests, it will change the observations a lot (e.g. one only downloading data from the last month, the other downloading 4 month old data).
Additionally you will see an effect of user data especially on old nodes like mine who is 16 month. I get a good amount of egress from those, making my ratio egress/stored higher than most nodes. (e.g. 10GB egress yesterday, which was almost 25% of my whole egress. new nodes might not have much consumer egress)
The point is, it might not have to do anything with node performance or location or amount of nodes or size of nodes.
I agree with all of the above what you both wrote.
My theory is that is better to have data spread from many months than just from few days. ( my secondary node has - just ~15 days of storage)
meaning of this (as my opinion) is that, when node gets like now - 100-150 GB/day - it needs a lot of space to withstand … say… period of 6 months of ingress… (the node will take like 180days x 100GB/day ~18TB?) that’s a lot of storage needed, just to take it in.
But it still is just 6 months worth of data… what about second part of the year ;}
So the ingress cap (around 100GB/d) is a blessing (or a curse) for big nodes and also a curse for smaller ones (that get filled in just few days and won’t be accessed for (maybe) next few months ;D - a risk).
well you run into a problem eventually… because people delete data at a certain rate… like say 5% maybe its more maybe its less… but 5% isn’t to unreasonable…
if 5% is deleted monthly and about 2TB is uploaded monthly… then when you have 40tb then the 5% deleted would equa the uploaded data…
thus either at 40-60-80TB you will run into a max size that at most times won’t grow to much…
ofc this is a theoretical limit… nobody has gotten to that point yet… but its like the speed of sound… its a barrier that cannot be broken…
unless if one can manipulate the ingress ofc…
I agree with that, the main problem is that we don’t know if test data behaves the same way as customer data would. We don’t even really know what it is that they do with test data (download a portion if it straight after upload?,Check the integrity of the data periodically ? etc…).
My guess it that the correlation between ingress, disk space used and egress will get harder and harder to predict as more customer enter the network. The might all use storj differently which will lead to different patterns.
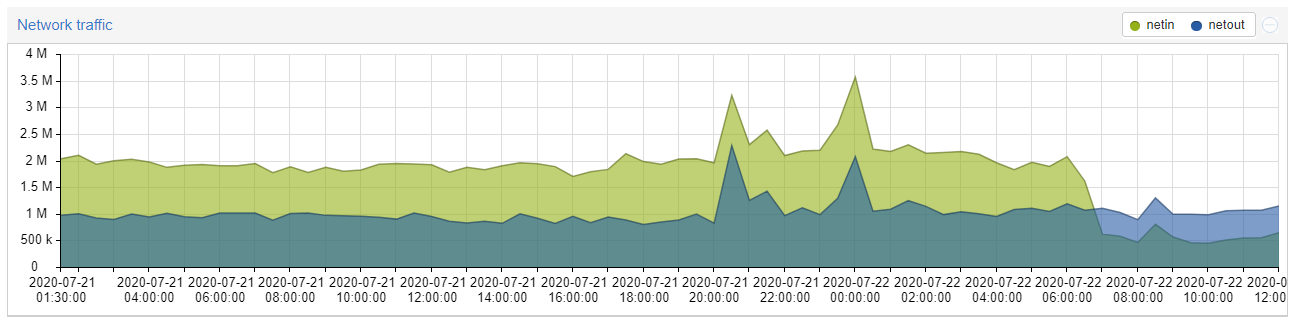
This is simply the result of a pattern we’ve seen a lot before. Some of the uploaded data is downloaded right away. And since that upload is now split across two nodes, so is the immediate download after upload. It’s a bit of an odd test pattern, though I guess you could compare it to a backup followed by a backup verification. So it’s not unreasonable to see such patterns with normal customer data as well.
I’d say it’s the other way around. If you have lots of customers, a certain expected traffic pattern will likely arise. With small amounts of customers every individual customer has a lot of impact on the overal traffic on the network. But we kind of have no clue what that will look like right now.
Wanted to check out with you.
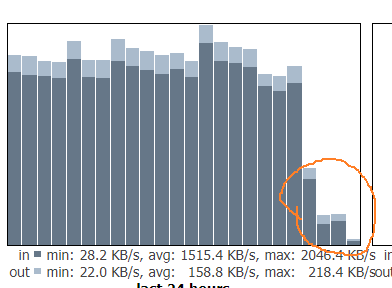
Today i am noticing barely any traffic (last 4 hours)
Until yesterday it was pumping like ~14Mbits on average now it is 1.5 Mbits
Checked for DQ but no.
@shoofar yeah it been a trend lately… afaik only been here for 4½ months so difficult to really tell, been like this for the last 3 months or atleast close to 3… seems to run the test data for 2 weeks and stop for 2 weeks every month … but haven’t really tracked it that well…
which i don’t see a bit problem with… it’s also nice to get an idea about what the network is doing without test data…
Thanks. I had to reinstall my server so my nodes were offline for over 12 hours and I was surprised about the low traffic
But as always, as long as the node is online and gets requests, it’s unlikely to be some configuration error that leads to low traffic.