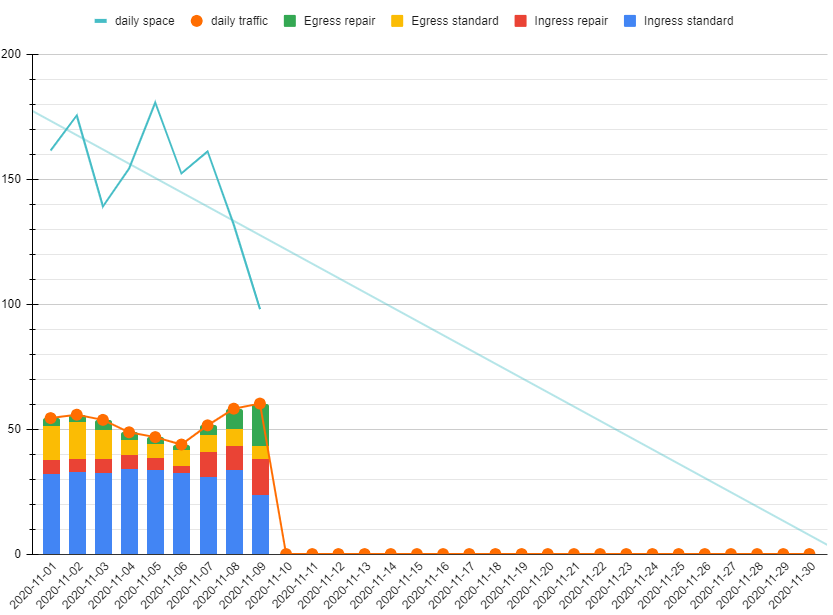
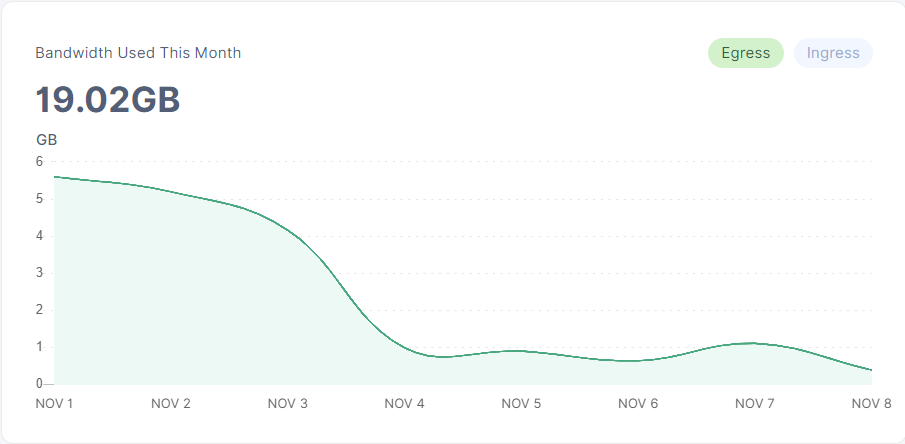
Did anyone see a big drop in egress since the end of last month ?
My egress wend from 20+ GB per day to about 5 GB now.
got 26GB/day for 7TB
Here about 26GB/Day for 8TB, too. Can confirm.
I looked into it and it’s looks like it’s europe-north that stopped pulling data from my node, it’s down to less than 100MB per day compared to 10+ GB per day last month.
Also my node is almost 6Tb for comparison.
main node, got two tiny new ones that are basically irrelevant.
and sharing the subnet with a foreign node, so my numbers may not be greatly useful.
but on avg seems to be 30 maybe a bit more
so a bit on the low side but that i would expect until i get move to a different subnet.
or it’s just random chance… have seen a good deal of egress over the last few months.

I’ve am noticing a drop in egress but it started for my node in the half of the previous month and it dropped from 18 to 12 then 10 then to 5

So not sure how to relate to your sudden drop.
Checked europe north and it did drop but from 4th of November from ~6GB to ~16MB
a factor to be aware of is that test data egress will favor older nodes… if it is possible to compare egress, which it might not be…
then one would need to figure out which factors come into effect and since the satellites doesn’t move the data around, then there will or should almost always be a bit of a lottery … a bit lottery xD
however if we assume test data is fairly distributed / utilized, which i would bet on… then it might be possible to compare egress on nodes that are / have been in similar conditions…
like say if
equal in age…
haven’t been suspended…
haven’t run out of space…
have an equal number of nodes on their respective subnet’s
maybe is geographically and or avg internet connectivity to that particular geographical region…
maybe not limited by their internet bandwidth… but with the fairly limited avg speeds i doubt this is a large factor
i’m not aware of anyone attempting to test this… but again… it would only be relevant for test data… which might become less and less relevant as tardigrade starts to gain in popularity…
so yeah… comparing egress is very difficult, if not impossible…
tho i do think if one was to account for all the mentioned variable (if there aren’t more important ones that i am forgetting) then one might be able to compare egress on test data… maybe even real world usage… oh yeah i forgot multiple nodes on the network… but we kinda know how that works, atleast with ingress, so as a base line i would assume it’s very similar, even if real world will be much more of a bit lottery, i suspect…
but who knows… test data might be much the same… but i doubt it, people would be whining to much if it wasn’t fairly evenly distributed.
That seems to actually be true even without repair egress:

node: GB egress per TB storage used.
1: 24,8 GB/TB, age ~20 month
2: 9,25 GB/TB age ~16 month but was only 1TB for a long time.
3: 16,98 GB/TB 6 month
I agree.
1 Like
would be interesting to try and do an experiment on that tho…
1 and 3 is kinda close ![]()
checked my node from when it was 7 months and had 14tb
gives me 164 GB egress pr TB for august … so the age factor doesn’t work if it isn’t the same at the same time… .but not that i expected otherwise… just remembered my node had a 14 tb when it was 7 months… so figured i would check if it was even remotely close.
but egress was very nice at that point in my case…
or i assume that you did a monthly avg GB egress pr TB
if it was weekly tho it would be very close to mine…
now that i think about it… the time scale your GB pr TB is based on isn’t exactly clear.
yeah since egress varies a lot over time, you can’t compare different time periods. Also you have to account for the size and even though my node is really old, it was only 3.7TB for a very long time.
So there is really no point in comparing egress.
(My time scale for the data above is since Nov 1st to Nov 8th, should have made that per day or week but just wanted to make a quick point about node age, not give an exact number per day because it’s not comparable anyway)
Additionally node age is a difficult factor because even though my oldes node is 20 month old, saltlake and eu-north only joined the network 8-10 months ago and the majority of egress comes through these satellites. The remaining customer data on the other satellites is just a few GB/day.
1 Like
from 1-8th is close to a week tho…
still off by almost 70%… but was actually kinda close…
a bit closer than what i would have expected for two random avg’s in time on something that we almost regard as unpredictable…
i mean depending on how the 8th is included in the data, that gives it a possible 1/8th deviation right there… then there is the possibility that i already had my foreign friend on the subnet, which might add another 50% deviation… but ofc if his node was new it would most likely only have been vetting around this time, and can’t be sure it adds any deviation like that either…
and then there is the question of bandwidth, if you still are affected by peak limitations on stuff like egress… if memory serves that wasn’t to great… which might also add a bit more of a deviation…
it’s actually a lot closer than i would think… not enough to make any kind of guess…
but close enough that i certainly doesn’t rule it out… if it was 168 vs 24.8 then it would be very unlikely… but its more like 3.1 a day vs 5.4 a day
and basically all of their effects no matter if barely existing or either of them or all of them being included they would all make it even closer…
or the subnet one doesn’t seem to … because if i had less egress % shouldn’t put me closer to your number… but still the other two would still be relevant
the node age comparison tho doubtful, i cannot rule out of comparing your node at 7 months to my node at 7months.
i know you think it’s crazy… and i don’t think it will work either…
one is crazy until one is right lol
well the joining of satellites and such may affect stuff like that, but for this to work i’m making 1 simple assumption… that storj labs has some sort of control system that makes sure egress is evenly distributed by some sort of pattern across all nodes which is affected by node age…
and tho adding and removing satellites sure doesn’t make such things more reliable in theory… it might not have any effect at all depending on how the system is setup to function…
i suppose the logical first step tho… might be to stop speculating and actually figure out if there is some sort of documentation or an engineer that can tell us how the test part of egress is controlled.
this is after all open source, so maybe it’s as simple as looking it up basically…
he has no impact on your egress!
if it’s test data that is selected by subnet like ingress is, then he could have…
why do you think this to be so?
1 Like
because the egress depends on what you have stored. So he doesn’t “steal” your egress, only your ingress.
You can of course speculate some indirect effect of taking a part of your ingress but that is hard to prove and put into numbers. Just like the effect of a slower CPU, more load, internet usage, …
There is nothing in the code that would impact your egress if you have some neighbours.
1 Like
i honestly have no idea, like i also mentioned when i first wrote it, i don’t think it’s the case… but without actually knowing the mechanics of how the test egress is controlled, i really cannot say…
personally i haven’t look or tried to understand egress a lot… the most i’ve learned about how it works is people say it’s kinda random and it’s affected by age… and yes obviously the more data one has the more egress one will get…
which is again why i kinda exclude the chance of my neighbor having an effect because he would have been vetting at this time, so unless if he moved a big node onto a shutting down ISP which seems very unlikely, and i can see when he arrived on my monthly / yearly graphs.
so yeah the odds that this guy affected my egress is basically near 0
but that doesn’t mean i know how test egress works, and if subnets are taken into account for the egress test system… which they may or may not be … i got no idea, it’s stuff like that i would want to test to understand it better…
i wasn’t aware that we actually had access to the test data selection code… it was my understanding that we don’t have access to the currently used version of the ingress test data / subnet selection variables aside from an old version of the code.
because people use the information to cheat… or that’s how i understood it during the segment about it during the last townhall
but i could be wrong, so where can i find this code? or the blue print
i mean you got a name for it, that i can search for or something.
if i check my yearly graphs egress does seem to have dropped just as much as ingress when i suspect he went online / finished auditing.
but the graphs aren’t perfect sadly, will have some other data mixed with it…so it’s not easy to say from that… not really clear… but certainly doesn’t exclude it… egress and ingress seems to follow each other ofc this is only from the last 3 months in which the TB hasn’t changed any meaningful amount.
We don’t have access to the test data selection code, only the code on the server for selecting nodes to be downloaded from.
So we could speculate about how storj creates test data egress but I doubt it is as sophisticated as checking which pieces are on which node and how old the node is and then trying to evenly distribute it. Because that would mean that the test client has direct access to the satellite database. Not likely a test scenario storjlabs is running because tests in general are to mimic normal client behaviour. So it is more likely they upload files and then just download them again.
it’s possible…
doesn’t seem like most recent data ingress is the only thing being downloaded… because my l2arc even with and uptime of 21 days and nearly 800gb in the l2arc and it still misses… so basically anything that’s been uploaded during the last 21 days is in l2arc… and still it it misses and uses the hdd’s a lot.
so if there is mainly test data still then it’s on a test cycle longer than 21 days mainly and it’s a lot of it thats older than 21 days… people might use data recently uploaded most often than not, which i would expect to be so… but from what i can see maybe a large fraction would be old data being accessed of not most of the data being accessed… but then again with a node age of 9 months… then the last 20 days is only what 1/15th or whatever of the total time the storagenode has gotten data… so if it was evenly distributed it would be very low… but from what i can see it’s certainly higher than that… but i would also expect that…
i know nothing about how egress should behave or what will affect it… but i might try to find out just for kicks.
i think my main node is decreasing in size again… because i got the foreign node + i added another storagenode and my 3rd one is almost done vetting…
so thats atleast a 3 way split right now… might just be at the 14.5TB limit… which would mean at presently the max node size would be inbetween 30 to 45TB… which is close to what we expected…
1 Like