From what I read saltlake and europe-north are considered “testing satellites” because they are used by storj to create traffic/do some testing and the others should only be used by companies.
I have no scientific numbers, but i am also seeing more traffic across my nodes.
from what we have seen in traffic we can pretty my conclude that there will be test data from all satellites, even if some satellites carry the main portion…
i mean we have seen how all satellites drop in traffic when storj gets busy… so ![]() must be test data from all off them… ofc one would want that… because you cannot verify customer data in the same way as you can test data…
must be test data from all off them… ofc one would want that… because you cannot verify customer data in the same way as you can test data…
so maybe it’s a way to monitor the network long term and data stability.
That’s my conclusion as well.
Test data does not necessarily have to come from STORJ. I think big customers will also do their own tests of the network and that‘s why we see similar patterns also with the customer satellites.
That’s true but I don’t see why they would stop uploading data at the same time as storj does and resume at the same time.
well when storj says… oh we had to migrate our satellites and thus you got 50% of the normal ingress last month…
it dropped across the board, if you look at payout history for october and november
you will get almost the same payout with double payout, which boosts the 50% earning during Nov
to 100% approx payout
sure 1 satellite on my payout is a little off… but the others are spot on within like 10%
which seems to indicate that storj test data is the majority of data we are seeing.
but i don’t disagree with you, companies will make test patterns and test / monitor the network.
we just don’t seem to see their testing or we don’t have enough information about their tests to even look for it…
Well people, when we assume we… you know the saying
The googleusercontent.com domain kind of says what it is. It’s not for google stuff, but stuff from google users. Specifically users of their cloud platform. You know… the platform on which the satellites are hosted.
Bad Google! How dare they provide cloud hosting services for satellites! So evil…
Yeah…
So yes, probably just some satellite service running on the Google Cloud.

doesn’t make google any less evil.
half a GB per day of egress-only traffic providing google users cloud service. Doesn’t really click for me.
Makes it completely irrelevant to this discussion
Also if one big customer were to join the Tardigrade network, it could probably pour a lot of data at first by migrating their data from their old system to Tardigrade. That could also explain a sudden high ingress rate.
Hopefully that’s what happens time to time ![]()
At least I do hope so.
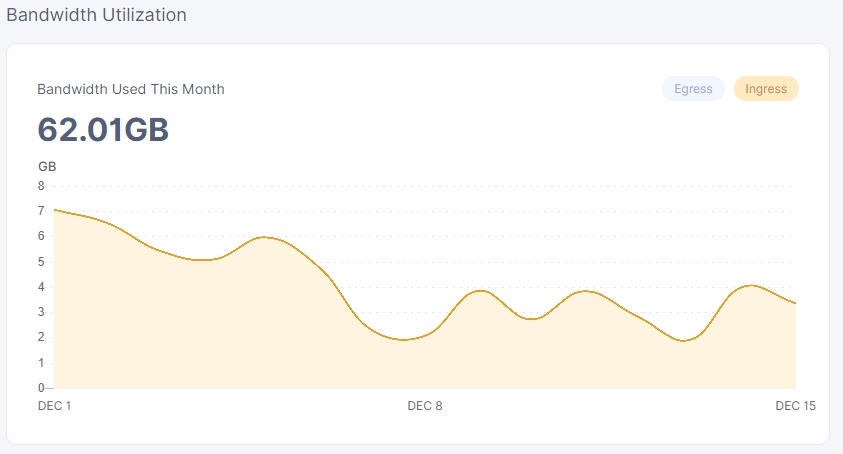
your numbers for the 1st seem kinda low…
tho mine granted are kinda low, but got 3 nodes all equal in ingress for the 15th which is something like 2 or 3 hour until the storage nodes start counting the new day.
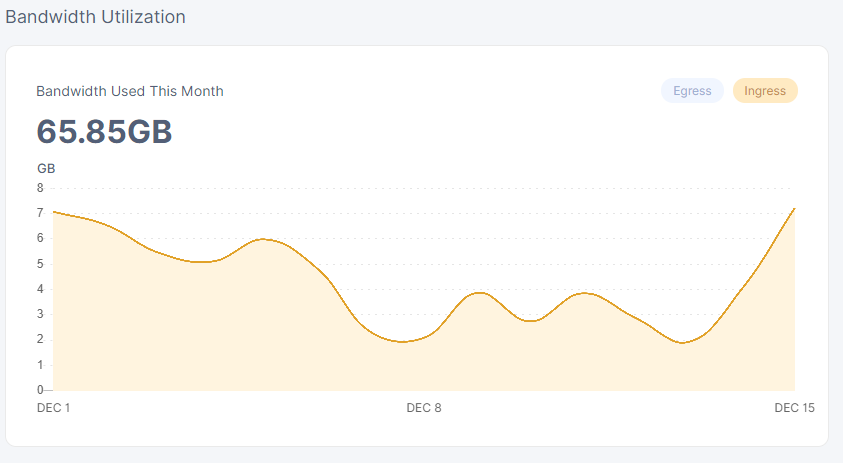
is that a new node? my 3 month old node seems to have the same graph or similar to the first
while the 2 month old today looks a lot more akin to yours…
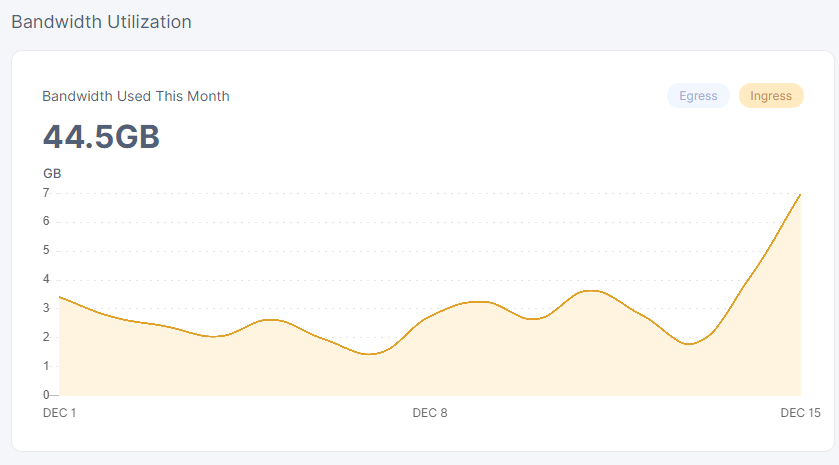
also kinda interesting that it took exactly 2 months to vet the node this time… last time it was done in 1 month… this time it was 2 months… exactly
but yeah without a doubt ingress seems to be going up, doesn’t seem that unusual tho.
and in the past we have seen weeks sometimes with 200gb + ingress
ofc then everybody upgrades… and it slows down ![]()
True, but I remember that was mostly test traffic from the Saltlake satellite. Now I see a lot of traffic from the us-central and europe-west satellites. So maybe it is real data which would be very nice. Also it does not seem to be repair traffic but usage ingress.
will certainly be interesting to see how the network will look after a year or two…
but yeah it will take quite a while before we will reach test data levels, if ever ![]()
tho if it gets popular then it surely should.
Test data max throughput caused many issues especially to SNOs with SMR drives, which is a good thing coz it uncovered this kinda problematic issue. And most probably the idea was to find out how the network handles such an uncommon stress.
Improvements were made but SMRs are still an issue that’s not automatically balanced/handled by the node software, probably because these kind of high usage are not foreseen.
I’m not sure we’ll ever see such bandwidths in real usages anyway because otherwise it would fill up the entire network in a few weeks, right? ![]()
are you aware how big the internet’s is ![]()
if storj gets enough hype then surely we will drown, way beyond any level of tests…
there was implemented solutions that should help make sure SMR drives aren’t drowned by an endless amount of ever increasing data, or that’s how i understood it…
and even if storj doesn’t get popular wouldn’t storjlabs do tests at times… ofc i really doubt any test can compare to what real usage looks like… i mean i test my stuff…
but thats like 1% to maybe 3% anything about 5% i would consider obsessive and not very practical because the test itself causes wear.
often my tests are a bit less, but lets say that 2-5% is test data for the first 3 years… ofc it will take time to reach the level of customer data and because testing might become more difficult later one will try to get it done early.
but again thats not unlike when we do personal networks… we do a few transfers to check if it seems to work and then maybe use some tools, but practical tests is the method everyone knowns and uses.
but like i say thats a very low % of the total… sure it might not be used the same day you setup the network… but all of a sudden somebody got to move their data to a new server / workstation and just copy it over the network, because they didn’t want to unplug a hdd.
i think we will see traffic exceeding the test data by a factor of 10x within the first 3 years…
but i don’t think it will be sustained… it will be for weeks or a months and then go down to a more normal level, when NASA or ESA or whoever finish their backup / cloud migration.
i think daily and weekly usage will be erratic… some days will be quite active, while others might be very slow… but like all things it will come in ebbs and flows.
and i don’t think the network will fill up… unless if it happens very rapidly… i know i won’t let myself go to 0 capacity free…
but i should get back to my project of trying to figure out why PfSense won’t want to corporate, 20 hours in and i just cannot get it to route internet… i suspect its a virtualization or driver issues…
which is really annoying when one setup the local network as vlan to combat not having enough cables…
most people will just do multiple nodes on the same subnet to mitigate the SMR issue… it’s a very simple and good solution.