my unvetted nodes got 2.7GB ingress yesterday (both combined since same subnet). My vetted node got 12GB. So currently that’s 22.5% of the ingress of a vetted node. So it’s still a long way from a vetted node actually only receiving 5% of a vetted node. So this system is actually faster for unvetted nodes.
However, it also depends on generall infress:
I have 2 unvetted nodes on the same subnet so vetting will take them longer. They are both 1 month old now and vetting is done 11% (europe-north) up to 54% (on saltlake).
i should try and check how far mine are with vetting.
doesn’t seem to get anywhere really… maybe the other guy on my subnet is vetting nodes also.
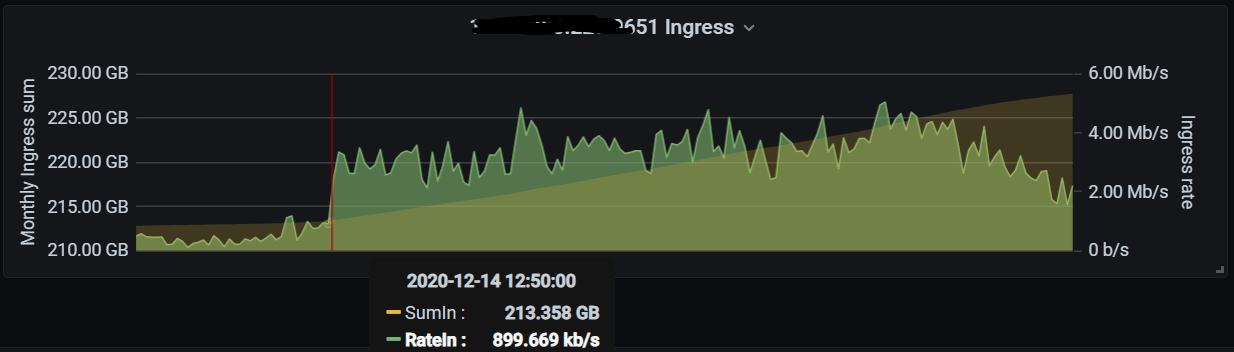
the one in the screenshot is my newest 2month old node. passing 2 full months in 2 days.
it got 2.7gb ingress for the 12th, which would mean either my 3 month old node isn’t finished vetting yet… but that doesn’t get the same low ingress as this latest one does, it’s usually equal to my main node so i just assumed it was fully vetted.
so if you are right about the a subnet having it’s own share of the vetting 5% global, then me having the same number as you would mean either my subnet neighbor is vetting 1 new node.
or in fact all vetting nodes gets an equal share of the global independent of subnet.
cannot say which… but that would be fairly easy to figure out by comparing ingress across more vetting nodes from other people.
coldsc’s
graph also seems to be around 2.7gb for 12th
so that would indicate that the global 5% is split between equally between all nodes, or he also have somebody vetting on his subnet which seems less likely.
so no your two nodes should vet just as fast as every other vetting node. only the network ingress and total number of vetting nodes will change the time it takes to fully vet a node, atleast to how i understand it and what the numbers seems to say.
ofc it does seem i have an alarming tendency to be wrong when dealing with this stuff…lol
but hey we are all learning.
there is another interesting fact about that tho… if we know the semi accurate number of unvetted nodes we can also calculate the total ingress onto the network, because it would be number of unvetted x current ingress = 5%
ofc the neighbor tracking thing works best on larger older nodes, so thats not going to pick it up.
doesn’t really have the information i want, but that andromeda thing looks kinda interesting.
While ingress is low the current nodes seem to be suffering quite a bit with the delete pressure- for sure. While staying below 10GB of loss, it still was enough to negate any ingress gains for several hours (12hr window show, zoomed to 10GB window height). …
yeah does look like my node have been shrinking for the last few days… but difficult for me to tell since i had 24 hours of dt recently and still got 137gb in trash…
i was reading that thread from the Q3 townhall question
linked a post or two above, it talked about how there was like 1300 or whatever nodes reporting free space and 8400 in total, the numbers are irrelevant for my point… just saying
so if we imagine deletes hitting the network on a large scale… this would have a MASSIVE impact on ingress, due to us being able to go from like say 1300 nodes that share ingress to 8400 nodes that share ingress…
so it would sort of start an avalanche when doing large deletes on the network, avalanche might be a bad example… more like digging into an ant hill and workers will swarm to take care of stuff…
much in the same way the network would from big deletions see massive drops in ingress months after as all the nodes getting extra capacity is filled back up.
just like the ant hill would see massive activity of workers in a removed area of the ant hill until the structure has been repaired and is back in equilibrium.
since the majority of storagenodes are like the bottom of an iceberg… 90% is below the surface / full
wouldn’t surprise me if the storagenodes of the network follow the same ratio… 90% of nodes will usually be filled… ofc just a gut shot guess, but math and nature has certain ways it likes to behave.
Actually, if there’s merit to what you’re saying (large number of “sleeping” active but full nodes), then this would coincidentally coincide with some of the depressions in ingress that seem to somewhat follow around when massive delete storms start happening.
yeah that was what i was thinking, it sure would explain some of what we are seeing and then if there is a large uptick of incoming / vetting nodes
it would also explain why they went from like 800 or 1300 nodes in the last townhall and then this time said there was 3700 over whatever which seemed like an immense uptick in the number of nodes…
but really it was or might have been related to the big deletions… which also may have been done by storj labs to equalize customer data over more nodes… in case large numbers of them contained mostly test data…
so yeah atleast from a hypothetical point of view, it would make a whole lot of sense.
They consider the pieces unhealthy after a node has been offline for 4 hours. There is a separate system to track when a node is offline for reputation scores, which counts the node as offline as soon as an audit is sent to an offline node. I’m sure you knew this, but just making sure people don’t think they can be offline without penalty for 4 hours.
No, repair only recreates and reuploads the pieces that are unhealthy at that time. So other nodes that are online can keep their pieces.
There has been some confusion around this. There is a system that audits unvetted nodes with at least one piece with priority. This should help all unvetted nodes equally. But this accounts only for a small part of total audits. All other methods still rely on how much data you have and since unvetted nodes share ingress, it is still expected to take a while longer for multiple unvetted nodes to be vetted.
None of this really matters as long as you make sure you always have a vetted node with free space available as well.
yes, sorry I was only referring to traffic, not the uptime system.
but a piece consists of multiple erasure code shards which have to be downloaded from multiple nodes to recreate the piece and then upload all shards to the nodes, so nodes that have the old shards will have to delete it. So the nodes that store shards of a different piece of a file will be unaffected by repairs.
(Maybe I got the terminology of shards and pieces wrong but I think you understand what I meant)
A little bit. What you call a piece is actually a segment. A segment is erasure encoded into pieces which are spread out across the nodes. The satellite knows which pieces are healthy and which aren’t. If a segments number of healthy pieces drops too low, repair is triggered. That repair downloads 29 healthy pieces, recreates the encrypted segment and from there recreates the unhealthy pieces and uploads them to new nodes. So this leaves everything on healthy nodes in tact. The only thing they may see as a result of this repair action is repair egress if they were used to download one of the 29 healthy pieces. They get to keep the pieces they already had. Otherwise you would be penalizing and removing data from reliable nodes. Luckily that doesn’t happen.
well that’s good, makes for a much better system over all, it also seemed like a very wasteful approach.
there are four nodes on my subnet, i said that before kevink brought up the 5% of global for unvetted nodes on a particular subnet.
does seem like this node is taking it’s sweet time, started one a month earlier and it finished in the usual month, but this one i made 2 months ago tomorrow has just been churning away, haven’t gotten around to checking how far its gotten because my network is messed up atm and haven’t bothered to fix it because my new ISP are being …'s
apparently vetting nodes are going slow atm, even if there is a minimum vetting speed, you think that is an indication of there being many new nodes being vetted?
or is it just down to the very low traffic we seem to have been seeing for a long time…?
ah my bad. I thought after recreating all pieces those pieces are different than originally but instead it just recreates the unhealthy piece. thanks for clarifying
Hey guys, any idea whats up with this outbound connection? It’s been sending from 2KB to 50KB per second always and it’s not egress that’s tallied in the dashboard.
most likely nothing to worry about… i guess was the short of the long rant i was on…
rant’s and reasons
deadcold guess… just some good old regular google monitoring of your internet connection… cheers
was trying to login to a good account where i have the password, and was logging in from a known location and was able to get the security key from en email verification and still wasn’t allowed to login because they couldn’t identify who i was as a person… without credit card / phone information
O.o
really… Google is evil… no doubt about it
but yeah no clue really… i don’t really do a lot of tracking of this stuff.
tho like i said, most likely some kind of web related stuff, most web related stuff google got their dirty hands in… cannot load a website today without google popping up 25 times… for tracking data
so most likely nothing to worry about… i guess was the short of the long rant i was on…
Well I have seen “customer satellites” go up and down in traffic with the testing satellites so I’m not really sure that they are used exclusively for customers.
Might be a coincidence but it already happened a few times…
wouldn’t customer satellites be untrusted satellites and unpaid work/storage (but i don’t think they will communicate with most of the network) which would make them not part of our network, unless if they have gotten them added to the trusted list or however it works.
you might be able to add them or remove the trust list depending on how you setup your storagenode, but personally i’m not that interested in untrusted satellites, tho it would be cool to run a verified / trusted one, when that becomes an option.



{kind=link}