Seeing low amounts also (UK, vetted on 4 of 5)
@pdwelly normally you would see nearly the exact same as me, however recently a new satellite started pushing data, and that is most likely the one you aren’t vetted on yet.
i know some of mine aren’t even tho it’s been months.
The numbers are pretty clear, been just a little less than 36 hours since i removed the vetting node from the ip of one of the equal vetted nodes.
initial start less than 0.5% deviation.
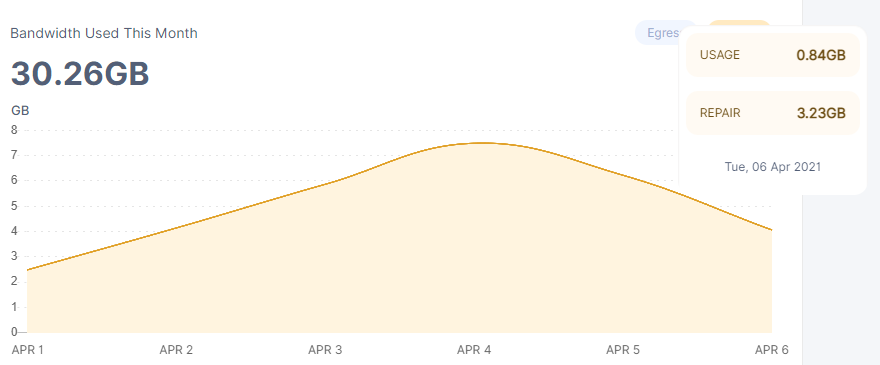
node 1
node 2
i let them run for a few days this month before starting so that one can clearly see the normal deviation in the numbers.
nearly 4% deviation at 36 hours from start, and ill keep it running for a while still, but the numbers are pretty clear.
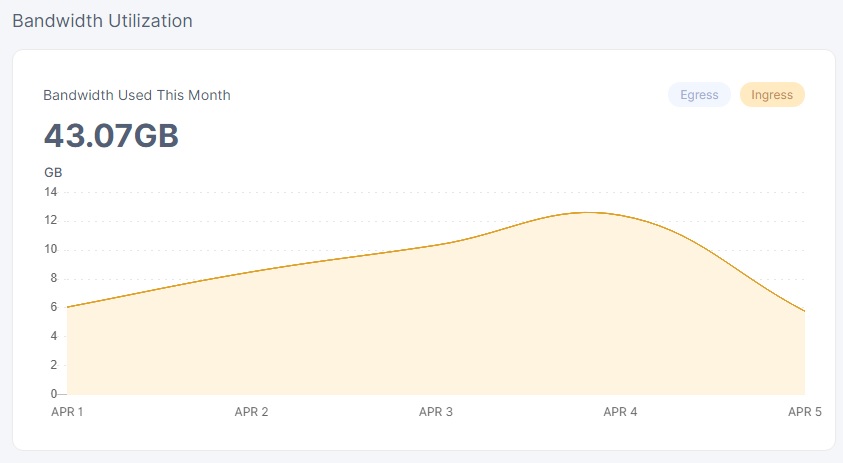
node 1
node 2
the deviation was about 2% last night.
well that sucks… figured i would verify that it wasn’t vetted just to be safe…
the node i removed from node 1’s ip
and it seem’s it already got vetted on us2, so that would seem to be throwing off my numbers…
ofc if nodes vet in on some satellites then even tho my argument was flawed it still results in pretty much the same thing, it’s not worth while to even attempt to vet nodes on the same ip.

now for the weird stuff i found…
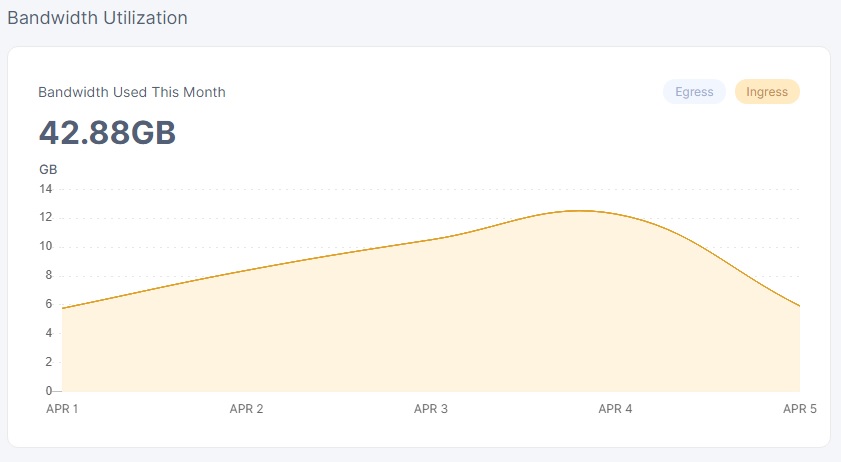
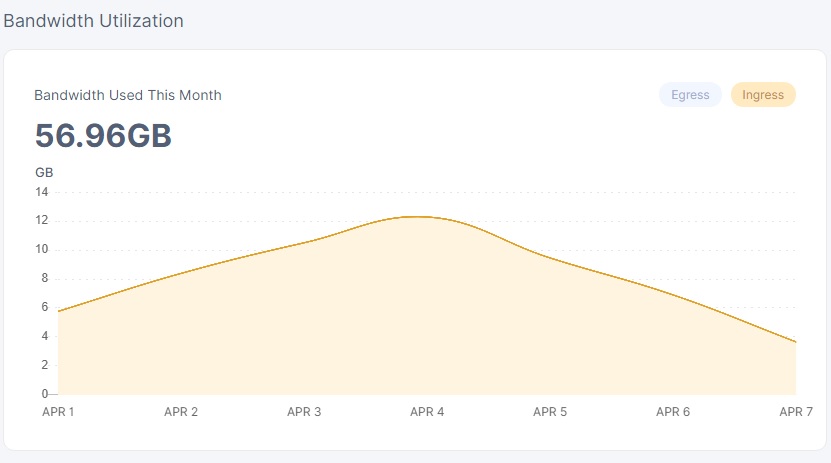
this is the us2 graph as you can see there isn’t any data coming or going from us2…
however…
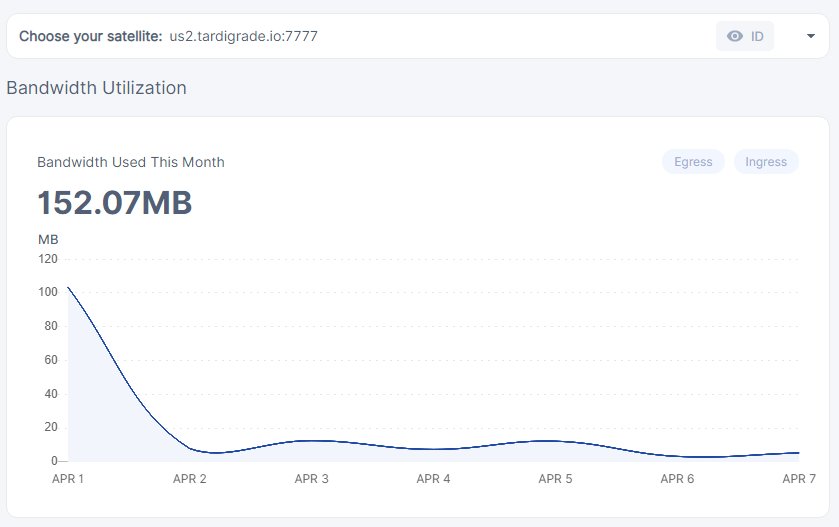
but it’s getting ingess, which drops off when it’s moved and can be clearly seen.
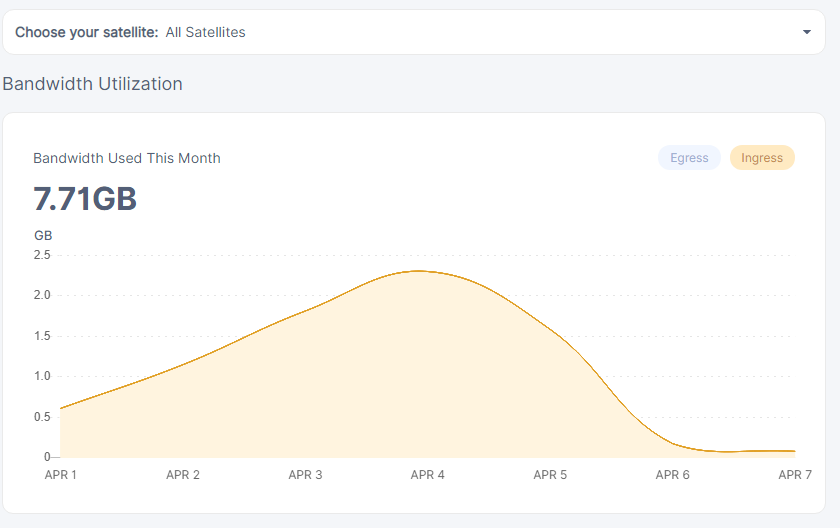
but that just begs the question, if us2 hasn’t gotten any significant ingress… i mean the highest was 90mb at the 1st of april else it’s like 10mb for each day…
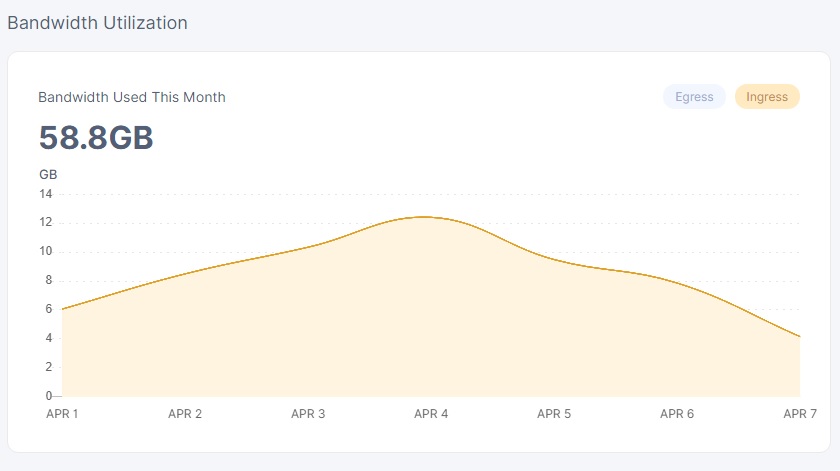
and the deviation between the two vetted nodes is up to 1.8gb from 250mb in only 36 hours…
then why is the other unvetted satellites ingress subtracting from vetted satellites ingess.?
which was kinda my initial claim.
i know you most likely won’t find this conclusive, but it’s apparently the best i can do right now…
duno when these nodes got vetted, they are not even 3 weeks old and keep in mind i was seeing this issue for weeks… so even tho they are vetted now, they cause the same issue somewhere close to 2 weeks ago… which would barely give then a week to vet… but i suppose it’s possible.
the reason i waited was because i didn’t think they would vet this fast on any satellite and i wanted the start of the month graphs to make it more clearly visible what was happening.
you have to admit it is kinda weird that there isn’t any data coming from us2 and it does seem pretty clear that the deviation is increasing fast between the nodes.
ofc it could be that when a node is vetted on 1 sat it moved to taking a share of the data with other vetted nodes across all satellites, seems like the only thing that would make sense.
if we assume it was vetted for almost a couple of weeks already.
pretty sure i checked it, but had a downtime warning on it, but i changed the earnings.py to not trigger the warning at less than 10%, so maybe thats why i hadn’t noticed it before.
but i think ill create a new node, and simply try again, just placing it on the one i called node 2 instead, just to push the deviation the other way.
was so sure this was going to be clear cut, but as usual i got more questions than answers lol.
For Europe-north-1, I only have 53 audits in 3.5 months… 3.5 months to go!!!
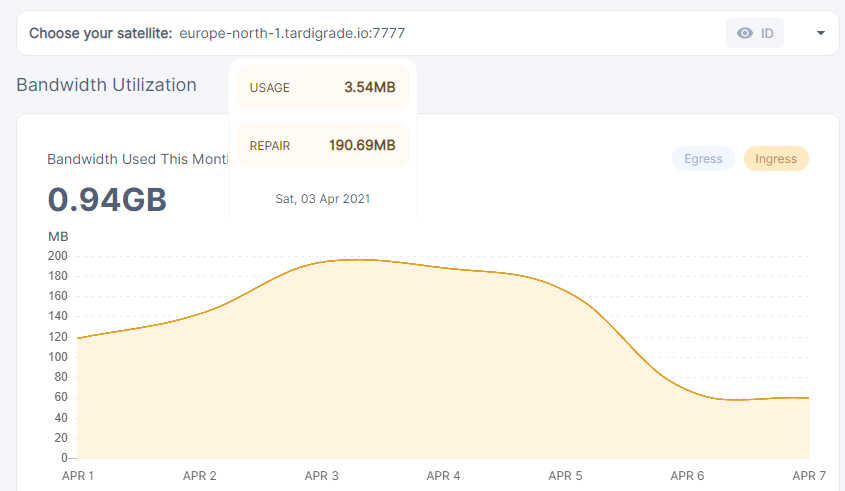
Assuming @SGC is vetted on EU North 1, then they will have 20x the ingress of me. My 1GB unvetted node = 20GB on a vetted node, which would explain the total ingress difference
![]() vetting depends on the amount of data coming from the satellites, thus because there haven’t been much data going out from Europe-north-1 then your vetting for that particular satellite has been stalled.
vetting depends on the amount of data coming from the satellites, thus because there haven’t been much data going out from Europe-north-1 then your vetting for that particular satellite has been stalled.
when data picks up, which i think it has… ill check
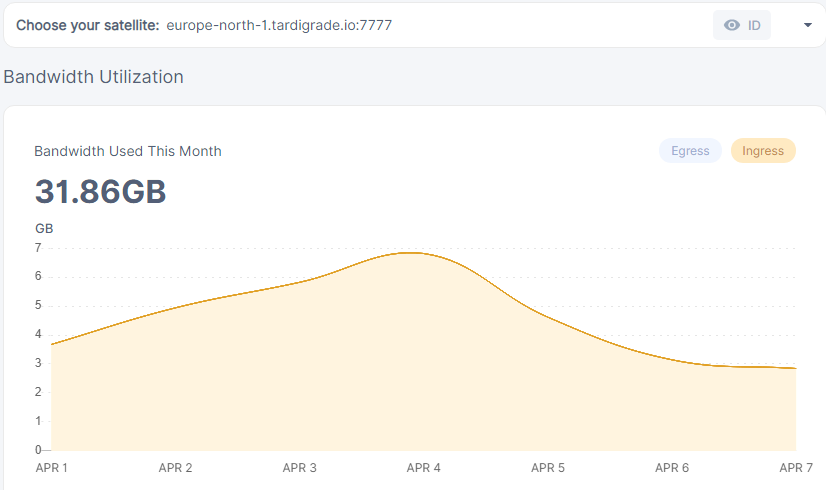
yeah looks like about half of the ingress we are seeing is coming from Europe-north-1
so i would expect your node to finish vetting in a couple of weeks.
The last months worth of Europe North 1 audits are (i.e. +18 in 31 days)
7th March +1 = 35
11/3 +1 = 36
12 +1 = 37
13 +1 = 38
17 +1 = 39
18 +1 = 40
19 +1 = 41
20 +1 = 42
24 +1 = 43
25 +2 = 45
29 +1 = 46
1/4 +2 = 48
2/4 +2 = 50
4/4 +1 = 51
6th April +2 = 53
I am averaging 1 a day from 1st April, but that’s still 6 weeks 
seems kinda low, all unvetted nodes across the network shares ingress from what i understand.
so there might be many unvetted nodes on that particular satellite.
now that it’s atleast sending out data it should punch through … i doubt it will take 6 more weeks if its current ingress keeps up.
IIRC ingress is the lowest it has been since almost the start of the network? Not counting repair traffic.
my numbers aren’t to good for looking at that, because i was running multiple nodes on the same ip for a while, so i cannot really tell accurately from the data i got.
however ingress distribution is balanced between nodes, but only if you add repair ingress and regular ingress together, besides it’s basically the same data… the only difference is that it is generated from dead nodes…
we have had unusually high deletes… but then again we have no idea about how high deletes we should expect, since the network is only be live in a year… so we really have no good idea yet… maybe in another year we can start to make some guesses about expected deletion %
was also just world backup day…  so maybe thats why we have seen that many deletes
so maybe thats why we have seen that many deletes
i don’t get why you wouldn’t count repair…
the only reason repair exists is because egress is paid differently.
and the reason repair egress is paid differently is because this is not customer egress, it is the network generating lost data and sending it to nodes in the network.
there is no point that i’m aware, that would require to treat any ingress differently…
I am running a single node on a static IP. I have 10.5GB of Europe north 1 data. No errors in the log. Not going to get my hopes up about it being quicker than 6 weeks 
I’m not counting repair because it is not ingress nor egress from the network. It is internal traffic.
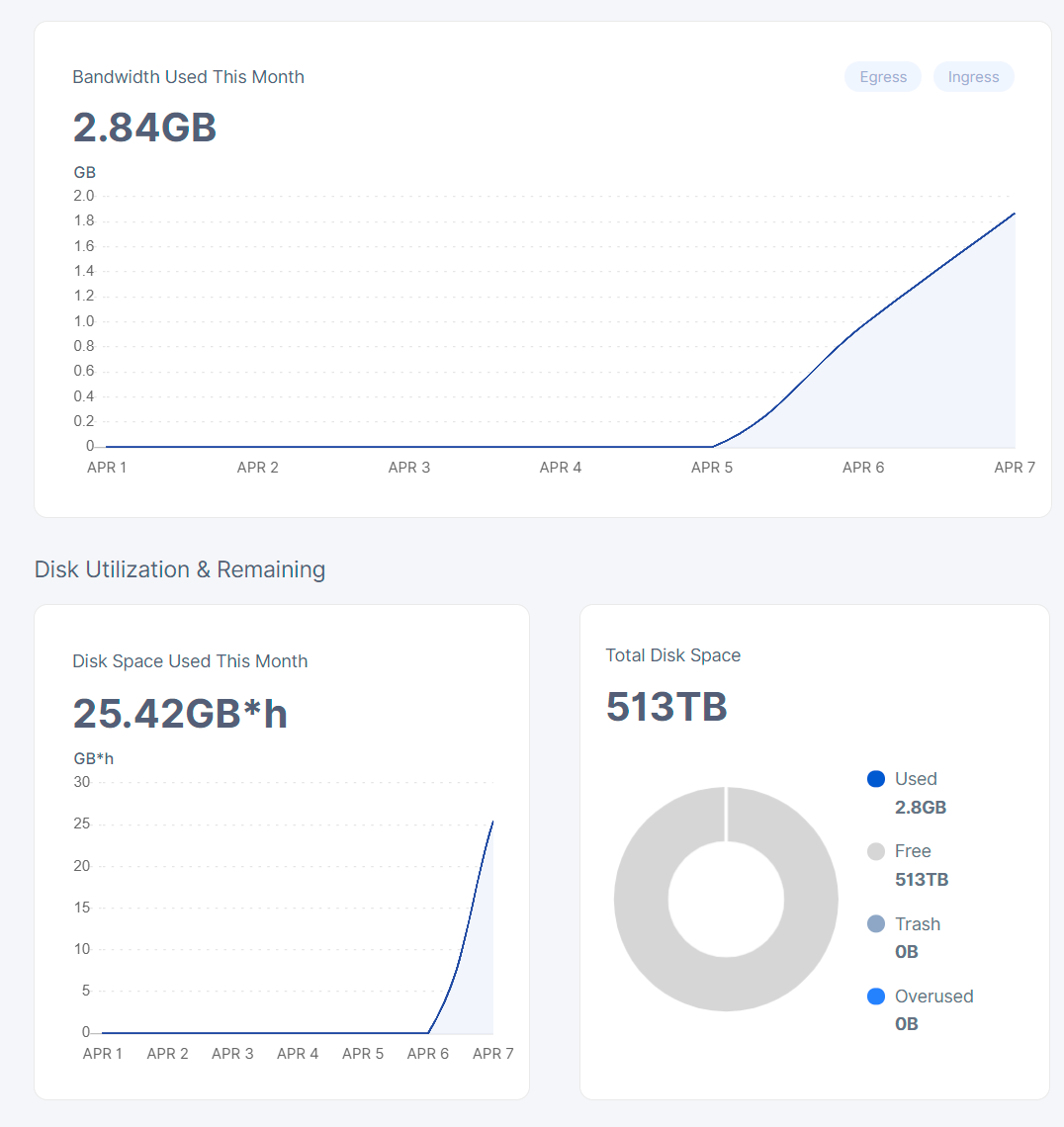
I like your optimism with the 513 TB 
it’s ingress alright, goes like this… customer uploads data and its split across 31 nodes or some number… i forget, but not important for the point i’m making.
then when people download their data you are paid for the downloaded data which is taken out of the pieces…
then time passes and some pieces initially generated and sent to the 31 nodes, this triggers the repair function, the repair function in the satellites then downloads the remaining pieces or the number required(repair egress).
these pieces are then used with the reedsolomon encoding or whatever it’s called, to general new pieces which contains the customers data.
these new generated pieces are then uploaded to nodes with capacity, this is repair ingress…
so really there isn’t any practical difference between regular ingress or repair ingress.
its still customer or test data that can be downloaded which is added to your node…
one could even argue that repair ingress since it most likely is older data then it could be more valuable because that the older test data is often downloaded more, so repair ingress could mean potentially higher egress.
also the odd’s of customers using tardigrade as backup needed their data will also go up with age, which again is about the same result… so i actually think i would prefer repair ingress.
but i doubt it really matters much.
I understand, but it is not network ingress/egress, like I’ve said - it is internal, or node ingress/egress if you’d like. No customer is uploading nor downloading data when repair traffic occurs.
It is like economics I guess, looking at the world economics and looking at your bank account are different.
As it stands now, network is experiencing almost no traffic compared to previous months, test or real. I assume more people are leaving than usual, or more new pieces are reaching the repair threshold, hence the increased repair traffic. Holidays, vacations/no-work, no-work planning I guess for the real traffic cause.
it’s spring, and people are itching to get out…
don’t really think it’s a real problem, there is always ebbs and flows in stuff like this…
also storjlabs seems to be doing some upkeep / updates / migrations and such… most likely because they expected this time to be a bit below normal.
also we have a ton of nodes on the network these days… so takes a lot of traffic to make an impact…
i mean we passed like 10k during like xmas… so those nodes are well integrated now.
so 1GB upload would be 3.3TB uploaded to the network when accounting for data expansion in the reed-solomon
not the same as youtube… but the network is still only 1 year old… will take some time before people trust it and test it… and the internet is growing at a phenomenal pace.
i forget when the square km array goes offline… but they expect that telescope to generate more data than the entire internet is today, every year or so… lol
the ingress will pick up and soon i would also suspect tardigrade will see a ton more customers, as people start to learn about the advantages, and as storjlabs gets everything streamlined.
just look at all the hype trains going on stuff like filecoin… it’s hilarious and they got shit… lol
storj actually has a fully operational network in its working form… but filecoin has friends at JPL or one of the co creators worked there or something like that… so it’s gotten all that old school silicon valley startup hype… lol
been trying to figure out if it’s actually a viable project… but its just so convoluted and over complicated …
and expensive to join and their storage miners actually went on strike lol because of poor payment…
now you can see people from other projects are starting to flood in looking for success with running storj nodes…
most likely an indication that it might just get crazy soon…
@f14stelt I don’t want to break your hopes, but realistically 500+TB will never fill up ![]()
Have a look at the following estimator by copying it in your own Google account and filling in your numbers to have an idea on how long it takes to accumulate data:
Just so you know ![]()
Oh i know @Pac but thats not a problem, thats some spare storage i can use so its just to make something with it
I don’t know how v2 stored 150 PB of data at a time when it was nothing close to the product that v3 is now and when it was much less known. Was that a gross amount? Even if it is, that’s still 25 PB in 2 years, v3 feels like it’s gaining adoption much more slowly judging by those numbers alone.
Just some “spare storage” huh? That amount seems just ludicrous to me…
Anyways, good luck with that.