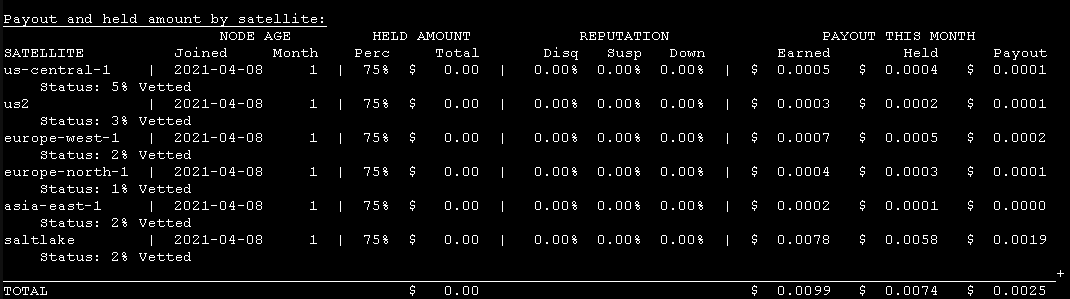
Node vetting on vetted node ip vs solo node on ip.
Getting the same results…
now 5 days in the 3 GB ingress difference has been basically negated so both nodes are back to being even… ill leave it running the month out and do a couple more updates on the numbers…
but this is pretty clear imho.
node 1 vetting + vetted node sharing ip
node 2 solo vetted node
and double checking the node hasn’t vetted all of a sudden…
alas the difference remains… nearly 3 GB or 2.5 GB out of 30 GB ingress so maybe slightly less than i was seeing on the other slightly vetted node… but pretty close to the same… this is also an only 5 days only node.
so maybe 5% loss of ingress and it seems to be accelerating, since first 3 days was less than a GB difference and now it’s up to 2.5 GB, i suspect in a few days i will be seeing around the 10% i have kinda been seeing across the board when i vet nodes on the same ip’s
and 10% less ingress on older nodes is simply worth also… i duno that it’s 10% tho… its just been the approximation i started with… because that was the difference i was seeing on my node against others when they posted their ingress…
but clearly it’s already in 5 days up to like 5% so would be atleast above that… the first days are notoriously slow on a new node, so most likely offsets the results a bit… but leaving it running and taking stock at the end of the month, so or in a week and then end of month, don’t what to leave it on my node longer than that…
ifs my 2nd oldest node and so ingress loss on that hurts a bit…
oh and yeah lets see the numbers for the vetting node… see if that has the ingress… 2.5GB
yeah looks like it… not sure what the spike at first was… also didn’t seem to offset the test…
but after it stabilized it seems the ingress lost from the vetted is basically what is coming in on the vetting node.
it may still be that vetting nodes get 5% of the total network ingress but whatever ingress they seem to get usually… i disregard the initial spike as a deviation from whatever…
alas the data is subtracted from the ingress on other nodes…
which is only fair ofc… else one would get more data by vetting nodes on the same ip as vetted nodes  just saying… so basically i’m saying
just saying… so basically i’m saying
vetting and unvetted nodes get the same total ingress as a single node when working in stable conditions… like not the first day
can’t prove that because i switched them around and i refuse to redo the experiment to verify that subnets share data evenly, it’s been the result always…
seems to indicate that it’s the same again…
which is good… no way to game the system.