they have been migrating the satellites, and apparently came up with a new naming scheme which i kinda like, makes so much more sense than having so unique names for each on, so one would have to actually know or find the name…
now you can just say… us1 or eu1 and you know what sat you are getting… so real prior knowledge needed.
so i would expect the last sats to also get a name change when they next are down… or migrated or whatever is required for storjlabs to change their names.
a little update / more data on the solo vs shared ip for vetted and unvetted nodes…
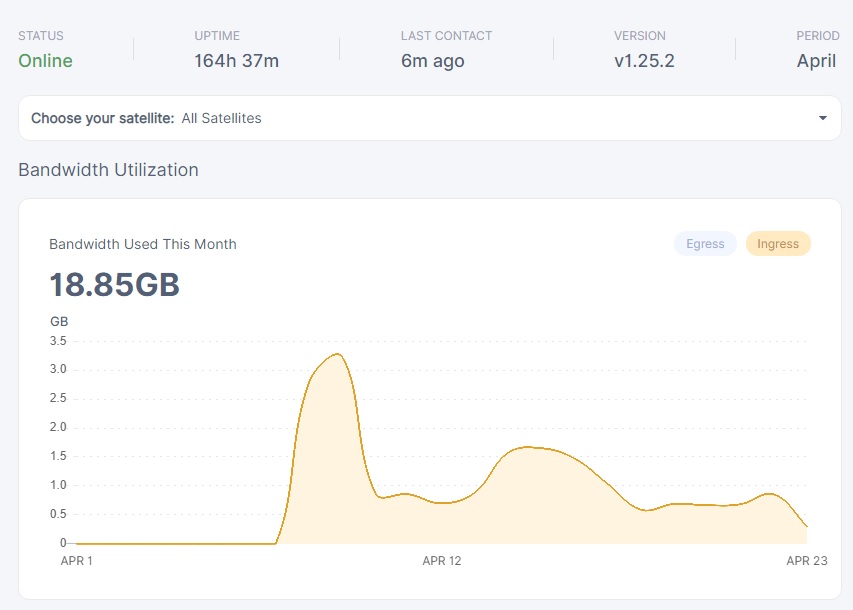
was helping someone with an unvetted node which is running on solo on its ip, and his particular node happened to be like a day offset from when i created my new unvetted node for testings…
so i got some data to compare… looks like there is a huge difference in the vetting process also for unvetted nodes when sharing an ip with a vetted node.
long story short, it’s basically not worth having vetted and unvetted nodes sharing ip’s for vetting.
besides they steal data from the vetted nodes, so again… so that alone makes shared ip’s not worth it.
and the vetting process also seems greatly inhibited… but not really iron clad, more an indication of it.
have also been pondering why my unvetted nodes was vetting so slowly… which this sort of explains.
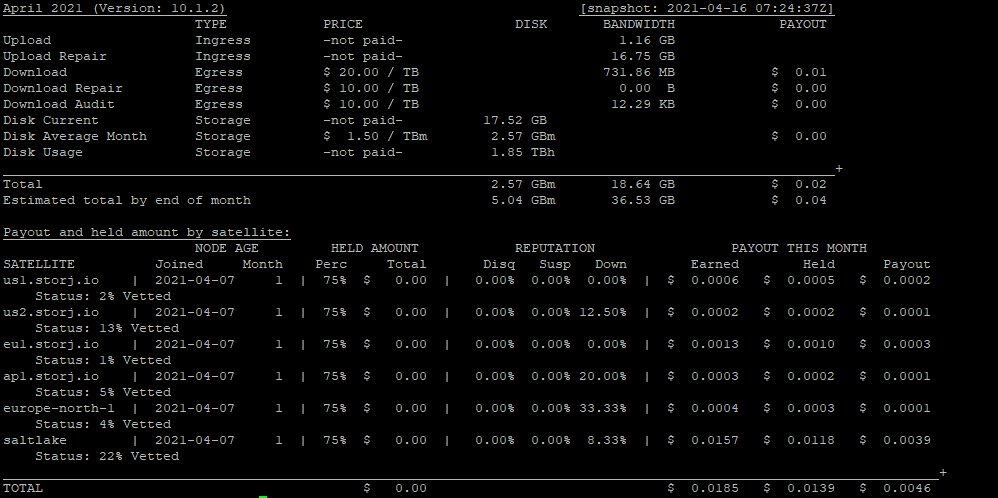
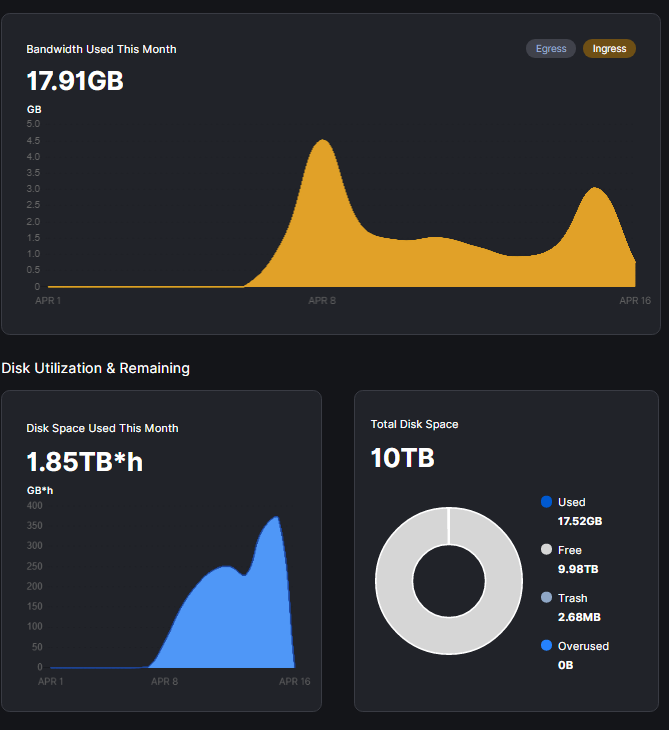
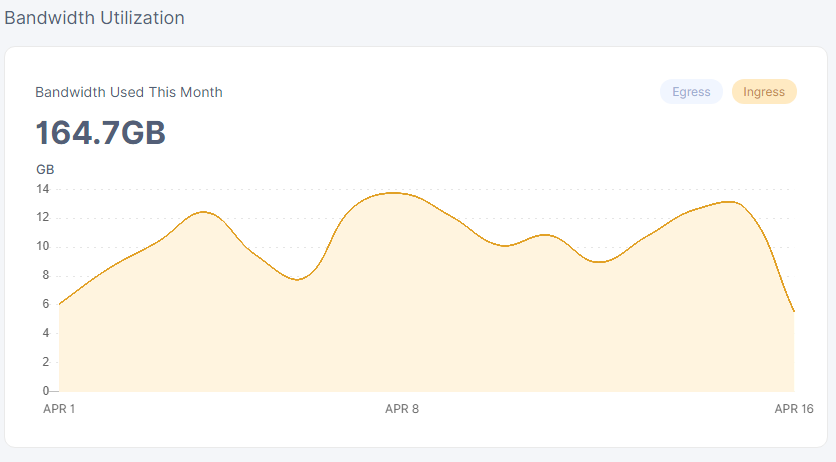
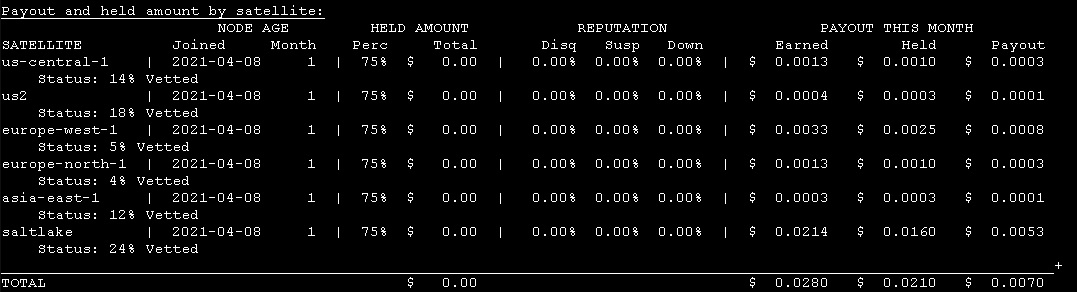
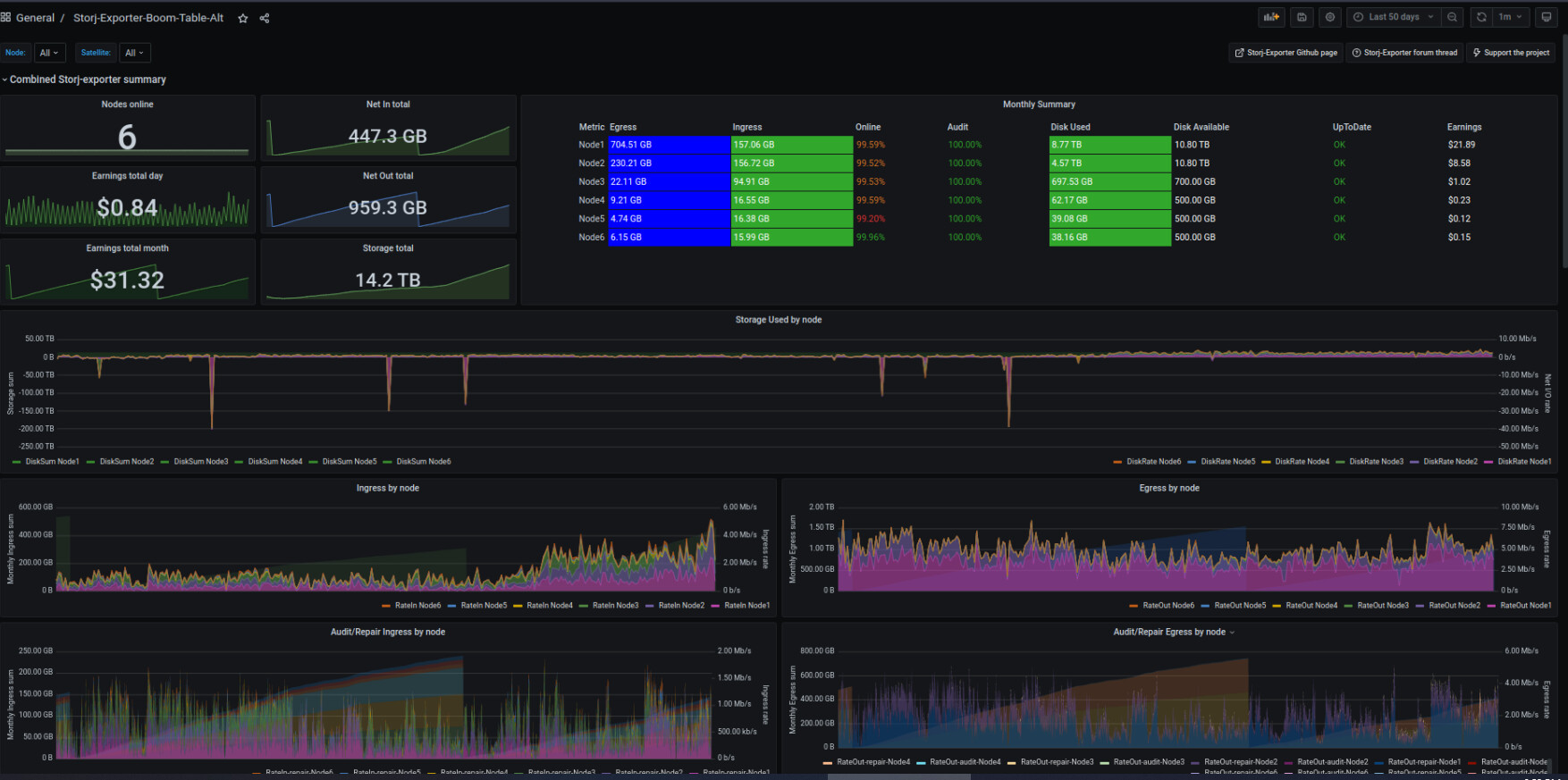
here comes the screens
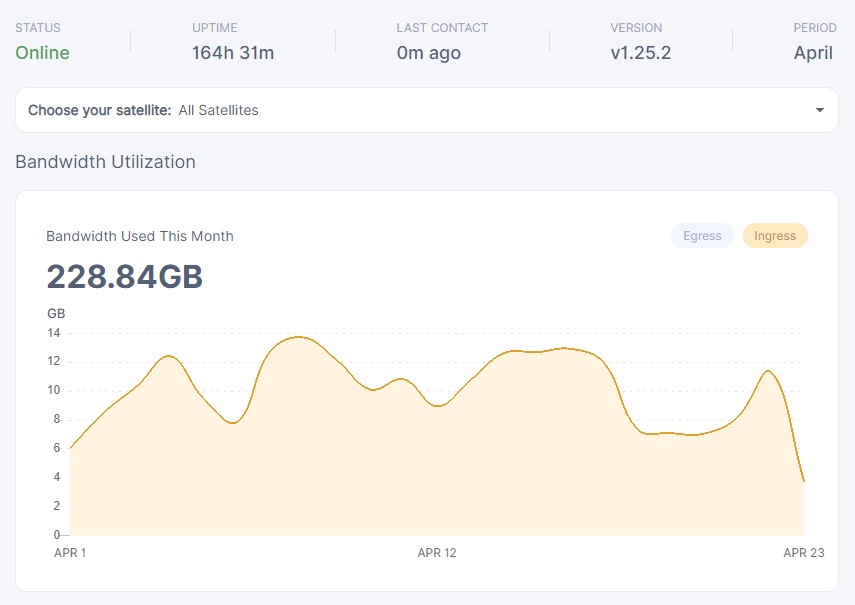
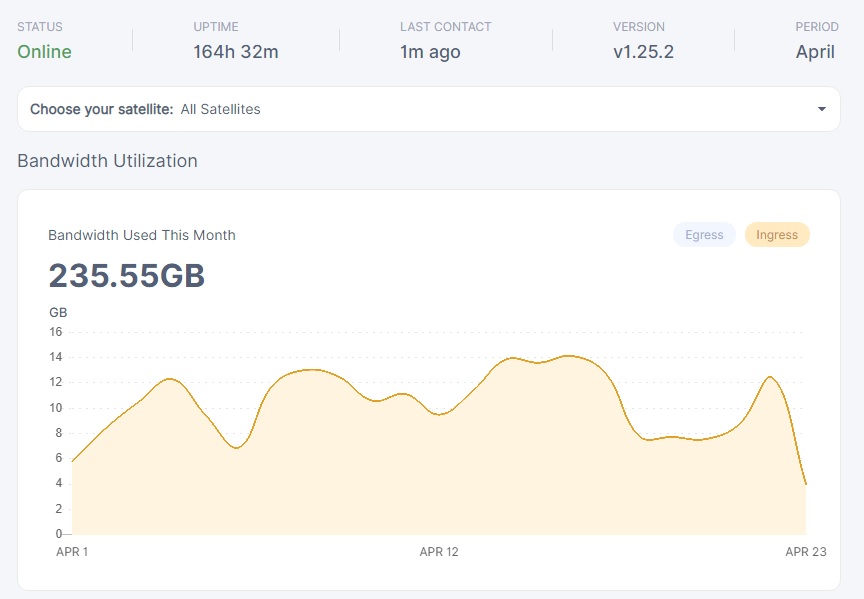
my unvetted node, sharing ip with vetted, joined 8th april
not much to say here…
the numbers speak for themselves, duno what the odd spike at the beginning of the new node is…
aside from that spike, all other ingress on the unvetted node has basically be subtracted from the vetted node of which it shares the ip addresss.
looks about what i would expect… 5-7.5% maybe a % point or two lower than my first initial estimate.
so long story short.
an ip gets a certain amount of ingress, if the nodes on it runs in optimal conditions.
these amounts of ingress usually don’t vary beyond a few % and if attempted measured accurately 0.25%
so a bit of useful information…
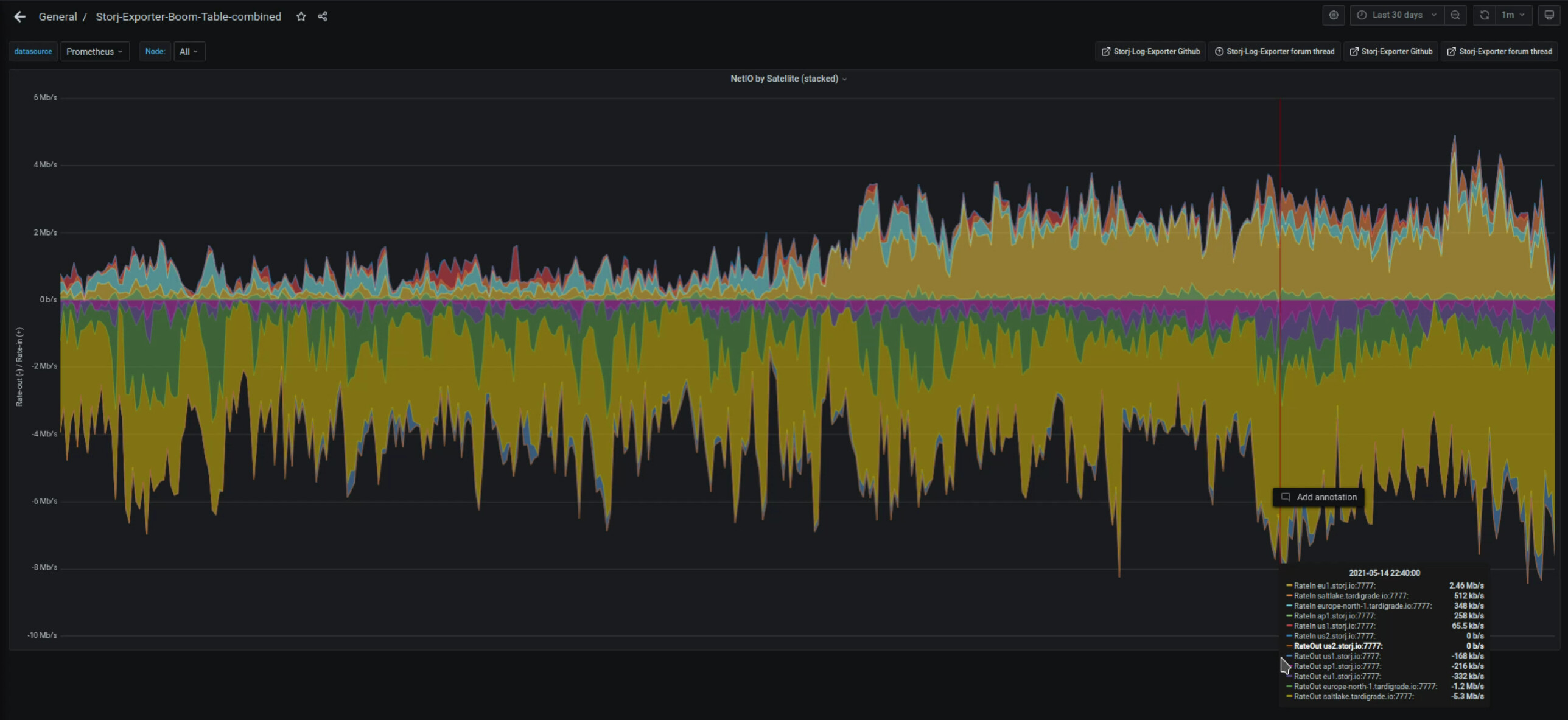
and now the question to come out of all of this is… why the heil does nodes on the home ip get less traffic than data center relayed, only 3-4% tho…
I think this comes down to round trip latency. Data center internet connections are running at single to low tens of milliseconds ping to much of the continent. Whereas home internet connections are in the low tens to low hundreds of milliseconds. Those millisecond differences count in the race to upload and download.
but they are relayed to the same server at my place…
which is what makes it kinda weird… only thing i can think of is that the different tiers of the internet might give data center traffic preferential treatment… which would sort of make sense…
running the data through a datacenter instead of directly to me… should take longer
For those wondering / manual updating, it seems as of yesterday nodes running v1.25.3 will no longer get regular ingress… since the new update for windows has been released…
the last week has picked up, but still nothing like some of the reported figures for a year ago… Given the time taken thinking of starting a 4TB Raspberry pi node on a different connection.
I certainly would not put an 8TB drive or larger on the network currently. If Ingres stays the same most of the drive life is likely to be consumed before it fills. My thinking is something in the range of 4-6TB is currently the optimal size. My second node that I added a bit over a month ago is 3TB WD Black. It was my main storage a few years ago but it has 60 000 powered on hours now so I no longer use it as that - so it became storj2 on the network. At current incoming levels it will see me out for the rest of the year or at least most of the year in terms of space.
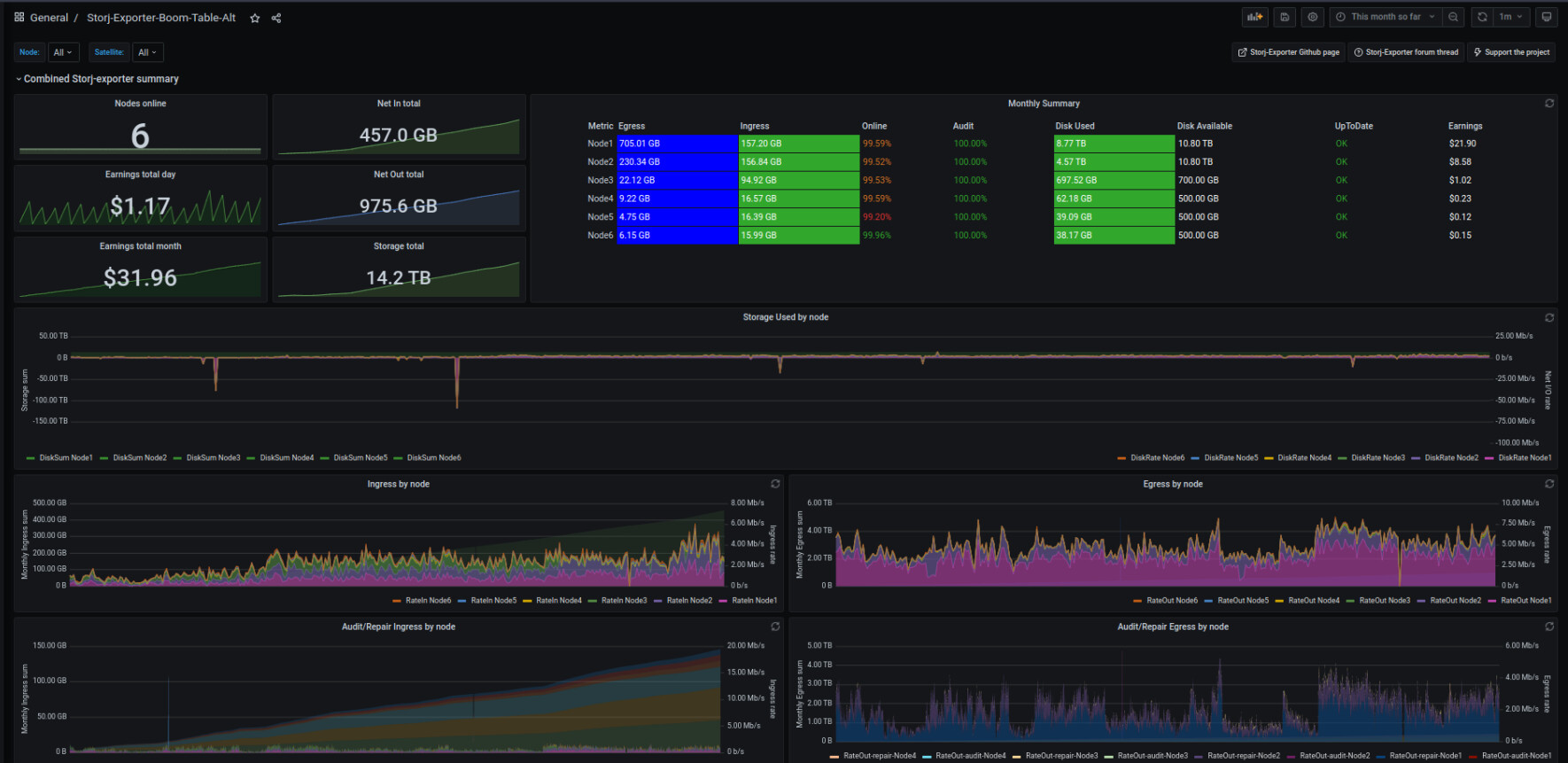
Assuming everyone else is enjoying a nice uptick in ingress and egress so far this month? Already surpassed ingress from last month…and finally recovered all of that lost storage from a couple of months ago.
and the successrate thing is mainly because 2 of my vdevs are filled and so the last one has to pull most of the load, seems like it is managing for now… hoping to soon get a deal on a stack of drives for a new vdev to help share the iops and add some much needed capacity.
but so great to finally see some ingress, hopefully it’s a sign of whats to come rather than an exception to the rule…
sadly i think it’s storj feeding us test data to reward those of us that wasn’t all in on chia.
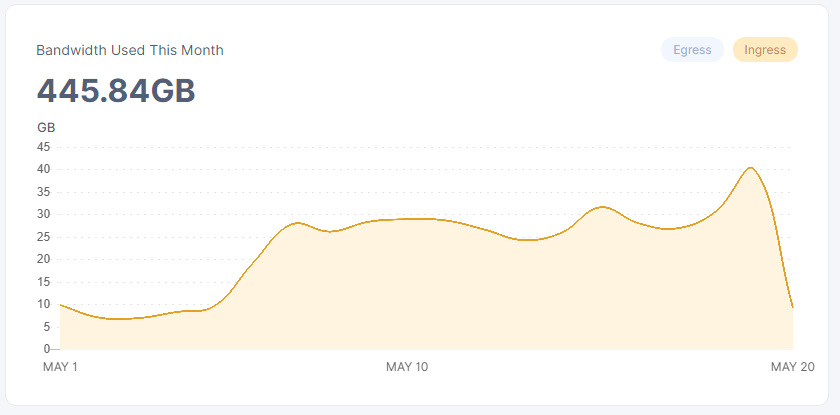
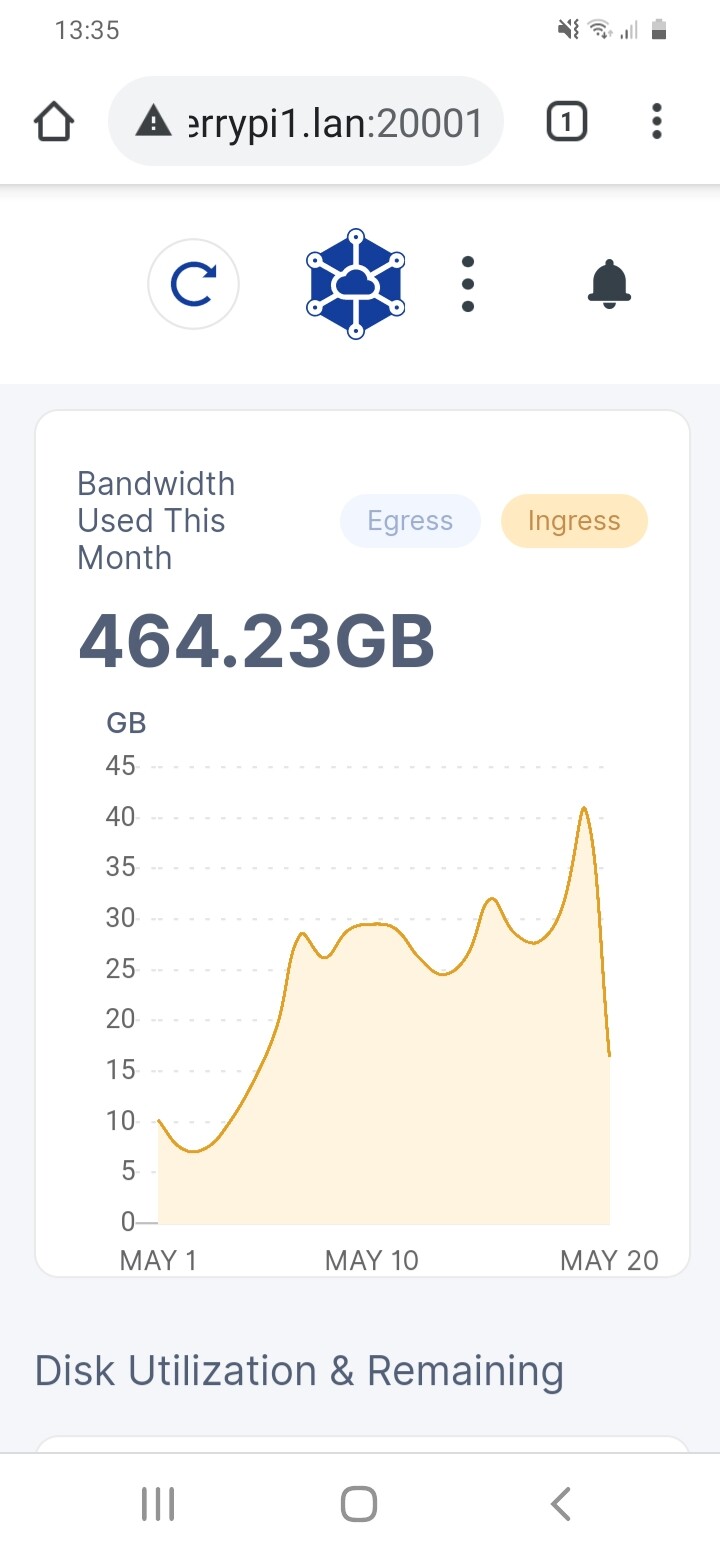
i guess my couple of % drop isn’t much since you are at 447 and i’m at 446 GB in this month.
thanks for the update, was kinda wondering if my % drop in upload successrate actually meant much.
apparently it’s barely measurable…
tho 8 hour difference in post time so maybe there is a 9GB offset
which would just about put it at 2.5% which i actually think was my exact drop in successrates
yeah ingress seems to have gone the way of the dodo…
wonder why your graph has a bit more sharp movements compared to mine… else i would say it looks about the same…
your node seems to run optimally i would say.
maybe all the traffic was that guy that talked about leaving the network with his near petabyte setup… seems kinda unlikely tho… even 1PB split 1000 ways would be 1TB for each …
and split over 15 days … i guess its possible…
even if gross guestimates, just wanted to see if it was in the same range…
kinda amazing that one guy can leave and it takes the rest of the network 15 days to soak up the data.