That only works as long as there are just a handful of hot files. The moment multiple customers request hot files at the same time the cheaper Pi3 and Pi4 nodes will not have enough memory to keep all hot files in the cache. Worst case the download pattern lets them rotate through the files basically reading from disk all the time. By the time the second request for the same file comes in they have been forced to delete it from cache and have to read it from disk again. So the fact that hot file delivery works for a single customer doesn’t mean it also works in bigger scales with multiple customers CDN like.
3 Likes
This is a good example of a scenario where carefully balancing placement of object by sizes onto appropriate media is of utmost importance. Zfs, which I just can’t shut up about, allows accomplishing just that with ease:
- metadata goes to SSD
- small files go to SSD
- large files go to HDD.
This accomplishes a few things:
- metadata fetches are always fast
- Small file fetches – where seek time would be much longer than transfer time – are also fast
- larger files – where seek time is relatively smaller compared to transfer time – are read from hdd.
The beauty of this, is that in that scenario raspberry pi usecase is back in the realm of possibilities: one can accomplish that with a pool of 1 HDD and one SSD (ideally, with PLP).
8GB of ram, of course, is a bare minimum, but due to effectively aggressive storage tiering it will go a long way for a few who have raspberry pi, unused single SSD and unused single SSD with PLP lying around idle. (which I don’t think those people exist, but hey, hypothesizing here).
1 Like
This is why the more memory advise should be in docs as recomandations.
1 Like
In windows more memory dont make sense. I use primo cache with NVME(no ram cache) but it also want ram for good file allocation in cache. 512GB-2TB cache. 2TB NVME cache want 13+GB RAM with allocation of 32kb. So minimum 32GB ram. Yes Recommendation is More RAM
For conventional approach – yes, where all data is piled together, increasing cache size gets higher chance of cache hit. But since cache is very small anyway, compared to total amount of data stored, with enough random access, it will stop mattered very quickly, as described in this comment Big Spikes in egress - #85 by littleskunk. Most data will result in cache miss regardless of how much ram you have.
Therefore, with large enough node, and enough of demand of CDN-line behavior from customers, amount of ram you have for caching will be irrelevant, unless you fit entire node into the ram. So you want to have enough ram to make system behave well, 8GB is min for ZFS, but beyond that – other ways to increase responsiveness of the entire storage, not just a subset of data that fits in cache" is the way to go.
Separating metadata and small files onto SSD and leaving large files on HDD is one of the very effective, data access pattern agnostic, approaches to accomplish that.
This is a good example of that as well: latency improvement from caching both in RAM and SSD, compared to HDD, is still enormous, but using SSD allows to have a massive amount of cache, comparable to the size of the node. e.g. you can have 2TB cache, on a 10TB node, and you have 20% chance of hitting cached data when customers access data randomly.
I don’t know if primo cache allows to fine tune what gets cached vs what gets fetched from HDD – being the block level cache it is not aware of filesystem, let alone file sizes, but it likely bypasses sequentially accessed data anyway, yield the close to optimal outcome. If there was a way to configure what length of sequential transfer to bypass – it would have been even better, since even “large” files that storagenode handles are still “small” from the OS perspective, that may result in excessive cache churn.
My stats show that very big amount is reeded several times. for example one of my server has 1 tb cache for 14 nodes All together is about 50 TB and I have cached reads across nodes 40-80%
So even relatively small cache give good result. Also read cache is separate from write cache. Write cache is only 5% of that 1 TB and 95% is read cache.
Some time ago I made a small analysis using logs. Found that my node of 0.5TB (at the time) would satisfy 30% of requests from a LRU cache of size just 5 GB. So, yeah, fully makes sense.
happening again now?
Yes, I can also see it
Same for me.
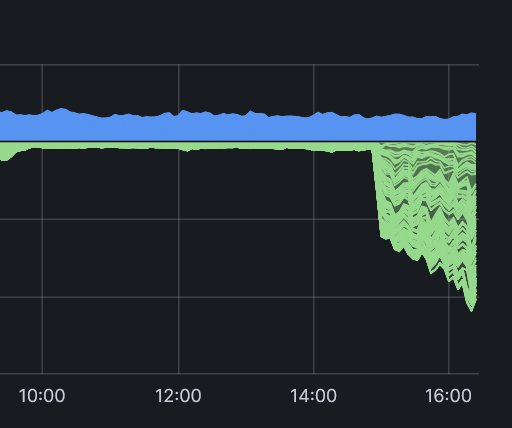
Seems it is happening trough the entire network. But it’s great and we earn more. ![]()
2gbit upload full used. never seen before
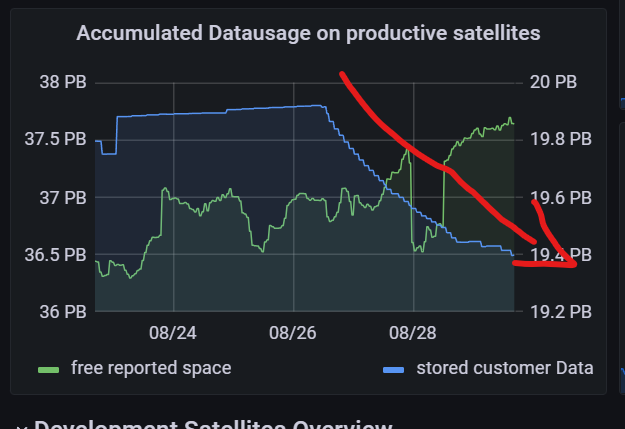
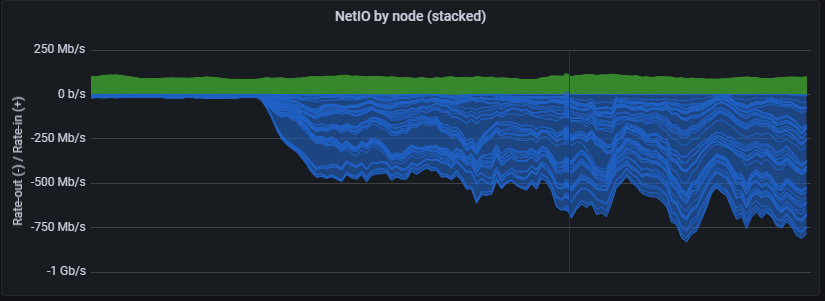
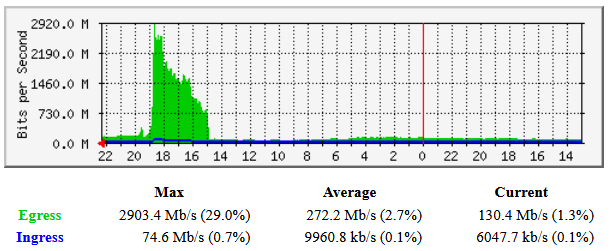
1 Like
Just thinking that if Storj had not changed their rates they would be looking at a rather huge loss about now…
So there is nothing happening on your nodes? For me the upload bandwith is still fully used.
Small SNO POWER! ![]()
![]()
Read the graph from right to left. He has also quite high egress since 3pm…
1 Like
God, I just hope it’s not a big player moving all their data out of the network…
the above comment means that no, the customer is not moving their data out of the network, they are testing scalability.
3 Likes
Whoops, I saw that but I thought that was just a guess.
That’s really cool, then! ![]()