Came down today to a bunch of mails saying one of my nodes was offline. In checking it appears that my TrueNAS SCALE server had cr@pped out. On restarting the server and checking Storj, it looks like it’s in a restart loop every 4 or 5 seconds. All I see in the Storj log for each attempt is:
2025-09-06T23:21:32Z INFO Configuration loaded {"Process": "storagenode", "Location": "/app/config/config.yaml"}
2025-09-06T23:21:32Z INFO Anonymized tracing enabled {"Process": "storagenode"}
2025-09-06T23:21:32Z INFO Operator email {"Process": "storagenode", "Address": "xxx@yyy.com"}
2025-09-06T23:21:32Z INFO Operator wallet {"Process": "storagenode", "Address": "0xc43DBD0E344E3a75AA64D917962D06feFB5443Fc"}
Looking at the docker logs in TrueNAS shows:
2025-09-06 23:21:32.348412+00:002025-09-06 23:21:32,347 INFO spawned: 'storagenode' with pid 97
2025-09-06 23:21:32.572390+00:00unexpected fault address 0x7f1f6e7e000c
2025-09-06 23:21:32.572431+00:00fatal error: fault
2025-09-06 23:21:32.574356+00:00[signal SIGBUS: bus error code=0x2 addr=0x7f1f6e7e000c pc=0x484003]
2025-09-06 23:21:32.574389+00:002025-09-06T23:21:32.574389416Z
2025-09-06 23:21:32.574399+00:00goroutine 1 gp=0xc000002380 m=10 mp=0xc001180008 [running]:
2025-09-06 23:21:32.574405+00:00runtime.throw({0x25f2008?, 0xc000f572e8?})
2025-09-06 23:21:32.574411+00:00/usr/local/go/src/runtime/panic.go:1101 +0x48 fp=0xc000f572a0 sp=0xc000f57270 pc=0x47aaa8
2025-09-06 23:21:32.574417+00:00runtime.sigpanic()
2025-09-06 23:21:32.574422+00:00/usr/local/go/src/runtime/signal_unix.go:922 +0x10a fp=0xc000f57300 sp=0xc000f572a0 pc=0x47ca0a
2025-09-06 23:21:32.574428+00:00runtime.memmove()
2025-09-06 23:21:32.574434+00:00/usr/local/go/src/runtime/memmove_amd64.s:117 +0xc3 fp=0xc000f57308 sp=0xc000f57300 pc=0x484003
2025-09-06 23:21:32.574440+00:00github.com/dgraph-io/ristretto/v2/z.(*mmapReader).Read(0xc001060660, {0xc000e9c000?, 0x1000, 0x800010000f573a0?})
2025-09-06 23:21:32.574483+00:00/go/pkg/mod/github.com/dgraph-io/ristretto/v2@v2.0.0/z/file.go:100 +0x76 fp=0xc000f57338 sp=0xc000f57308 pc=0x1bc5ad6
2025-09-06 23:21:32.574506+00:00bufio.(*Reader).Read(0xc000900ae0, {0xc00ae99106, 0x16, 0x4783b9?})
2025-09-06 23:21:32.574510+00:00/usr/local/go/src/bufio/bufio.go:245 +0x197 fp=0xc000f57370 sp=0xc000f57338 pc=0x5aa7d7
2025-09-06 23:21:32.574513+00:00github.com/dgraph-io/badger/v4.(*hashReader).Read(0xc00aea81b0, {0xc00ae99106, 0xc000f573d8?, 0x16})
2025-09-06 23:21:32.574516+00:00/go/pkg/mod/github.com/dgraph-io/badger/v4@v4.5.0/value.go:98 +0x2a fp=0xc000f573a0 sp=0xc000f57370 pc=0x1c2daaa
2025-09-06 23:21:32.574519+00:00io.ReadAtLeast({0x2b33b60, 0xc00aea81b0}, {0xc00ae99100, 0x1c, 0x1c}, 0x1c)
2025-09-06 23:21:32.574522+00:00/usr/local/go/src/io/io.go:335 +0x91 fp=0xc000f573e8 sp=0xc000f573a0 pc=0x4ba8b1
2025-09-06 23:21:32.574525+00:00io.ReadFull(...)
2025-09-06 23:21:32.574529+00:00/usr/local/go/src/io/io.go:354
-- Lots and lots of lines that look like backtraces
2025-09-06 23:21:32.577187+00:00runtime.goexit({})
2025-09-06 23:21:32.577193+00:00/usr/local/go/src/runtime/asm_amd64.s:1700 +0x1 fp=0xc000088fe8 sp=0xc000088fe0 pc=0x483161
2025-09-06 23:21:32.577199+00:00created by github.com/dgraph-io/badger/v4.Open in goroutine 1
2025-09-06 23:21:32.577216+00:00/go/pkg/mod/github.com/dgraph-io/badger/v4@v4.5.0/db.go:315 +0xc4d
2025-09-06 23:21:32.577233+00:002025-09-06T23:21:32.577233478Z
2025-09-06 23:21:32.577250+00:00goroutine 69 gp=0xc000702e00 m=nil [select]:
2025-09-06 23:21:32.577266+00:00runtime.gopark(0xc000089760?, 0x2?, 0x80?, 0x9b?, 0xc00008974c?)
2025-09-06 23:21:32.577286+00:00/usr/local/go/src/runtime/proc.go:435 +0xce fp=0xc0000895d8 sp=0xc0000895b8 pc=0x47abce
2025-09-06 23:21:32.577307+00:00runtime.selectgo(0xc000089760, 0xc000089748, 0x0?, 0x0, 0x0?, 0x1)
2025-09-06 23:21:32.577324+00:00/usr/local/go/src/runtime/select.go:351 +0x837 fp=0xc000089710 sp=0xc0000895d8 pc=0x457cb7
2025-09-06 23:21:32.577340+00:00github.com/dgraph-io/badger/v4.(*DB).updateSize(0xc000db1b08, 0xc000c62930)
2025-09-06 23:21:32.577357+00:00/go/pkg/mod/github.com/dgraph-io/badger/v4@v4.5.0/db.go:1205 +0x13e fp=0xc0000897c0 sp=0xc000089710 pc=0x1bf4f1e
2025-09-06 23:21:32.577373+00:00github.com/dgraph-io/badger/v4.Open.gowrap2()
2025-09-06 23:21:32.577391+00:00/go/pkg/mod/github.com/dgraph-io/badger/v4@v4.5.0/db.go:335 +0x25 fp=0xc0000897e0 sp=0xc0000897c0 pc=0x1bf0005
2025-09-06 23:21:32.577408+00:00runtime.goexit({})
2025-09-06 23:21:32.577425+00:00/usr/local/go/src/runtime/asm_amd64.s:1700 +0x1 fp=0xc0000897e8 sp=0xc0000897e0 pc=0x483161
2025-09-06 23:21:32.577442+00:00created by github.com/dgraph-io/badger/v4.Open in goroutine 1
2025-09-06 23:21:32.577472+00:00/go/pkg/mod/github.com/dgraph-io/badger/v4@v4.5.0/db.go:335 +0xe56
2025-09-06 23:21:32.578617+00:002025-09-06 23:21:32,578 INFO exited: storagenode (exit status 2; not expected)
Digging deeper, each time it tries to restart, syslog throws:
Sep 6 16:21:32 truenas zed[125735]: eid=1662 class=data pool='TheBigPool' priority=0 err=52 flags=0x1008081 bookmark=27159:45869806:0:143
Sep 6 16:21:32 truenas zed[125739]: eid=1663 class=data pool='TheBigPool' priority=0 err=52 flags=0x1008081 bookmark=27159:45869806:0:143
Sep 6 16:21:32 truenas zed[125743]: eid=1664 class=data pool='TheBigPool' priority=0 err=52 flags=0x1008081 bookmark=27159:45869806:0:143
A zpool status reveals:
root@truenas[~]# zpool status -v
pool: TheBigPool
state: ONLINE
status: One or more devices has experienced an error resulting in data
corruption. Applications may be affected.
action: Restore the file in question if possible. Otherwise restore the
entire pool from backup.
see: https://openzfs.github.io/openzfs-docs/msg/ZFS-8000-8A
scan: resilvered 21.8M in 00:00:00 with 0 errors on Sat Sep 6 09:26:00 2025
config:
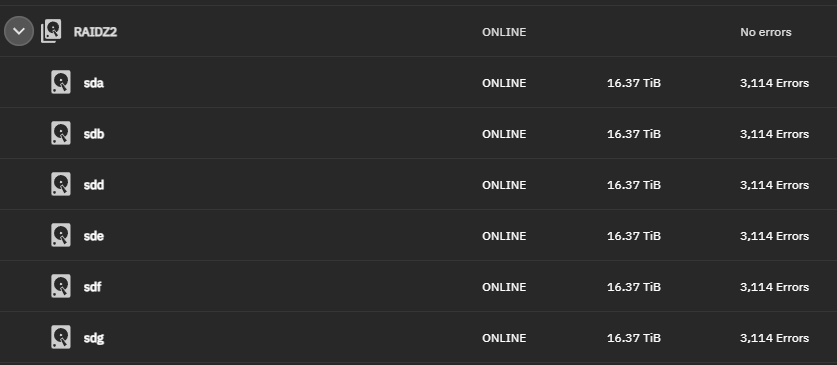
NAME STATE READ WRITE CKSUM
TheBigPool ONLINE 0 0 0
raidz2-0 ONLINE 0 0 0
935698bc-2eaf-4e70-b4f0-6a7ac29af87a ONLINE 0 0 3.04K
c6a601db-976d-4bd6-a40e-169329479a24 ONLINE 0 0 3.04K
f52208e0-32ca-47e0-9cdf-bc94211e8323 ONLINE 0 0 3.04K
cdd5a75a-7ac3-4c5f-a1d0-42f2b86066f4 ONLINE 0 0 3.04K
58ead5a4-3fe8-4ae5-ba9a-9d6419cdf8c4 ONLINE 0 0 3.04K
4577f924-97e5-42e1-a88c-884c4b690a1a ONLINE 0 0 3.04K
special
mirror-3 ONLINE 0 0 0
21a10d62-c26f-4471-932e-946537ba2e7d ONLINE 0 0 0
149770a7-f6cd-434d-98e2-1e85d4f293f8 ONLINE 0 0 0
logs
mirror-2 ONLINE 0 0 0
14f4713f-7a11-4416-ae0d-e52441511975 ONLINE 0 0 0
a141fc7d-5822-449d-bf6f-cc4f9b14814c ONLINE 0 0 0
errors: Permanent errors have been detected in the following files:
/mnt/TheBigPool/storej-node/data/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/u5
/mnt/TheBigPool/storej-node/data/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/ws
/mnt/TheBigPool/storej-node/data/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/pf
/mnt/TheBigPool/storej-node/data/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/in
/mnt/TheBigPool/storej-node/data/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/7x
/mnt/TheBigPool/storej-node/data/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/d4
/mnt/TheBigPool/storej-node/data/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/tl
Loads more blobs directories and the occasional file within a blobs directory
/mnt/TheBigPool/storej-node/data/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/5c
/mnt/TheBigPool/storej-node/data/storage/blobs/ukfu6bhbboxilvt7jrwlqk7y2tapb5d2r2tsmj2sjxvw5qaaaaaa/tj
TheBigPool/storagenode:<0x1>
pool: boot-pool
state: ONLINE
scan: scrub repaired 0B in 00:00:31 with 0 errors on Mon Sep 1 03:45:32 2025
config:
NAME STATE READ WRITE CKSUM
boot-pool ONLINE 0 0 0
nvme4n1p3 ONLINE 0 0 0
errors: No known data errors
root@truenas[~]#
Is there any chance I can save the node. Would deleting all the blobs directories listed in the zpool output help, which I’m assuming I’d take some hit for (hopefully recoverable).
Any other actions I can try to get more information from the node startup, which might show more information.
Cheers.