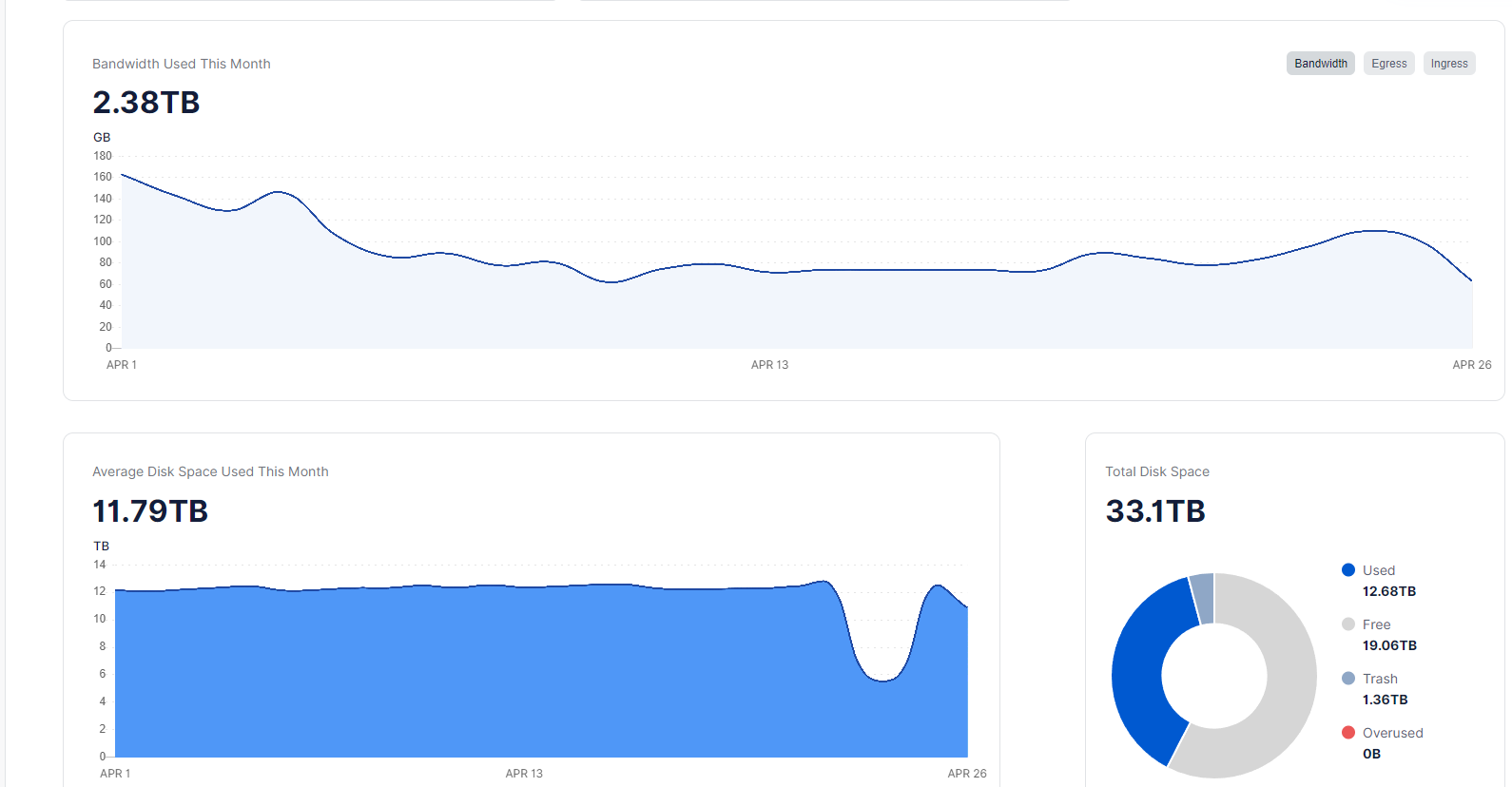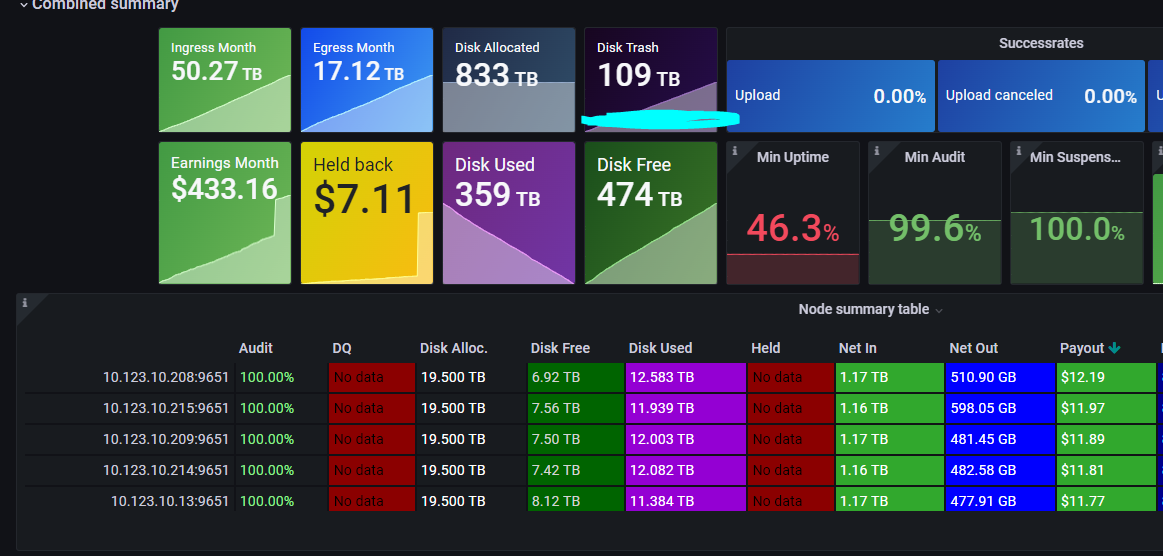
Been a operator for 2 years soon, adding more nodes as i go. Alot of disk trash is piling up now 109TB ![]() bloom filters seems to be working.
bloom filters seems to be working.
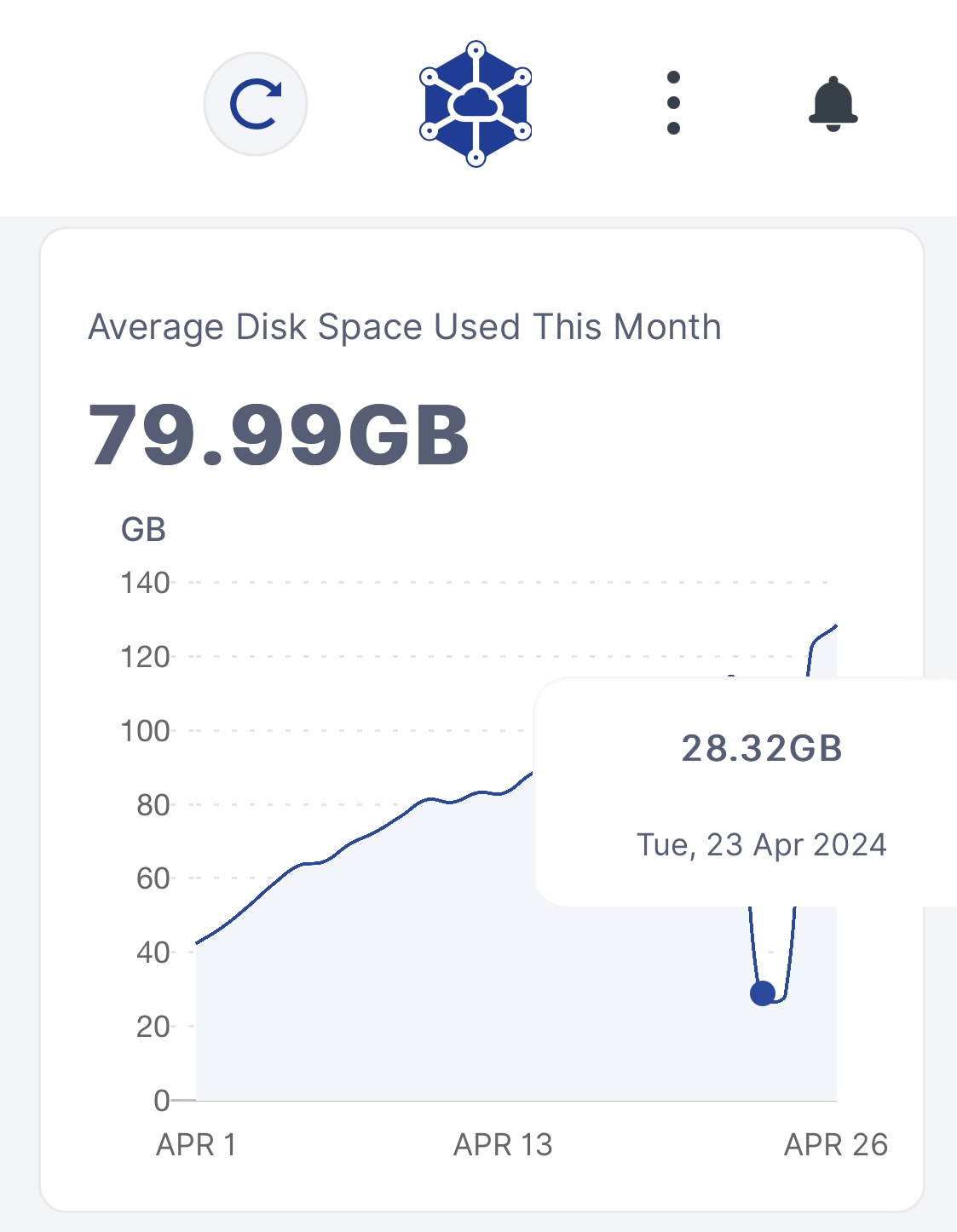
My nvme ssd is taking alot of pressure now because of all deletion:
Been a operator for 2 years soon, adding more nodes as i go. Alot of disk trash is piling up now 109TB ![]() bloom filters seems to be working.
bloom filters seems to be working.
My nvme ssd is taking alot of pressure now because of all deletion:
You’ve got more trash then most SNOs have data - wow! Yeah with the forever-free stuff being deleted over the next couple months you may not be super happy ![]()
I won’t bet on it. It would be nice though. I have 22TB drives to fill, started in ian.
That’s perhaps need to be discussed there:
Please take all suggestions, marked as a solution there.
The usage returned to normal.
What surprises me is that the usage decreased, but the earnings remained nearly unchanged, despite loosing around 3-4TB of data.
This are my 7 Nodes in Germany:
What’s perplexing to me is that the estimated payout is around 18-19 USD. However, when I check my wallet, the last payout was approximately 27 USD (as per the cost basis tool). I’m not complaining, just curious as to why there’s such a significant discrepancy.
There is a problem with tally running too long on US1 and it didn’t update nodes with the usage. It should not affect your payout as far as I understand, but it will affect graphs. We are figuring out how to fix this. Maybe no fix is required and we may decide to leave it as is.
And the estimation depends on the current usage, the estimator is assuming, that the usage would be the same, so it calculates a some value, which could be true or not. I would suggest to check it after May 15.
This sounds a little uncertain, so let me ensure everyone it won’t effect payouts.
The data the satellite reports back to the node is a time window and the amount of byte*hours stored in that time window. So if it took 56 hours for the next calculation to happen and your node stores 1TB, the data will say in this 56 hour time window your node stored 56TBh. The graph however calculates the usage for the day by dividing that TBh number by the number of hours reported, for all time windows ending on that day. But if it took 56 hours to get a next report, two days won’t have any time windows ending on those days and the graph defaults to 0 for the effected satellite. The full usage is still reported back to the node, the graph just doesn’t show it. I’m pretty sure the average reported at the top of the graph is calculated based on those daily numbers, so that might also be too low.
All of this effects stat display only, but not payout.
Please don’t. These topics won’t stop popping up and for everyone that posts about it, there are 10 more SNOs who don’t post but are also confused. A quick and dirty fix would be to simply not default to 0 but to the previous day’s calculation if there are no storage reports from that satellite for that day.
Yes, I know. But if the tally is failed, well, it will not produce a charge for the customers and likely will not produce a payout. I just do not have a full information, thus this uncertain, sorry!
However, you are right - it likely will not affect payout anyhow, because it will be re-calculated on invoice generation anyway.
Yes you are right. However, it will affect only me and maybe @Knowledge, but it would not require any “SQL Crime” injections…
Right, I’ll make a little more effort to show that is not the case then.
As you can see the node database has a gap between the 22nd and the 24th, but when I calculate the reported disk usage by dividing the reported Bh for the following record on the 24th by the time between those records, the storage usage perfectly lines up with the reports of the other days, so all usage is accounted for. This also confirms that the graph total is effected by the missing days as is should show closer to 0.82TB. Both the graph and query results here show only US1 data.
While I do care about the time of community leaders being wasted, I would for sure say the affected party here are the node operators being worried about nothing. Many of us spend time and effort in running a stable node and would for sure try to find out what is going wrong. Not many of us would know where to look in the databases to confirm. There are plenty of actual things that can go wrong and I would like to not make node operators worried over something that isn’t a real issue. This just wastes time and teaches them to not even bother looking for the cause in the future.
You’re right about that of course. That’s why I said that was a quick and dirty solution. The better solution would be to calculate the portion of each report spread out over several days that should be assigned to each day it covers and calculate the storage usage based for that portion. This doesn’t require any hacky tricks but makes the calculation slightly more complicated. The downside is that it will still show a gap until the following storage report actually comes in, but it would fix the gap still being there in the days after.
Thank you for confirmation!
It doesn’t have this feature as far as I know. So the only quick and dirty “solution” would be to use a “SQL war crime” to inject the usage between 22 and 24 to make all Operators happy, to do not spent time to explain this over and over again…
You don’t need anything different from the satellite. Say you have a report that covers 4 hours of day one, all of day two and 2 hours of day three, for a total of 30 hours. 4/30 of that Bh belongs to day one, 24/30 belongs to day two and 2/30 belongs to day three. Assign all storage reports to days like that and then sum the Bh and hours covered across reports and divide. No SQL crimes, no hiding actual issues in case a calculation was actually missed by the satellite, but it will fill the gaps.
That’s the point, it doesn’t have this feature yet. So, need either modifications or “SQL war crimes” at least as far as I understand this process.
We did not expect it to run so long. I do not know details, but it was not a normal run as may I assume.
Is “it” referring to the satellite here? Because that’s how I interpreted it initially. The satellite doesn’t need to change anything. This calculation can be done on the node, by just using the average apportioned to different days. That would still require coding of course, but no code changes to the satellite calculation, which shouldn’t be slowed down by this additional logic.
Yep, the satellite (or one of its parts, I starting to think that it could be better to have a separate binary for the each usage…), it has:
Hm, this sounds like it can be implemented on the storagenode side only? ![]()