![]() hanks - yea when its close to full jeg need to run filewalker again…
hanks - yea when its close to full jeg need to run filewalker again… ![]()
Maybe it’s true; I don’t realy know what the FW does, besides scanning all the files and hammering the CPU and HDD.
It informs the satellites of what is on my HDD or informs me of what should I have on my HDD and the files that should be deleted?
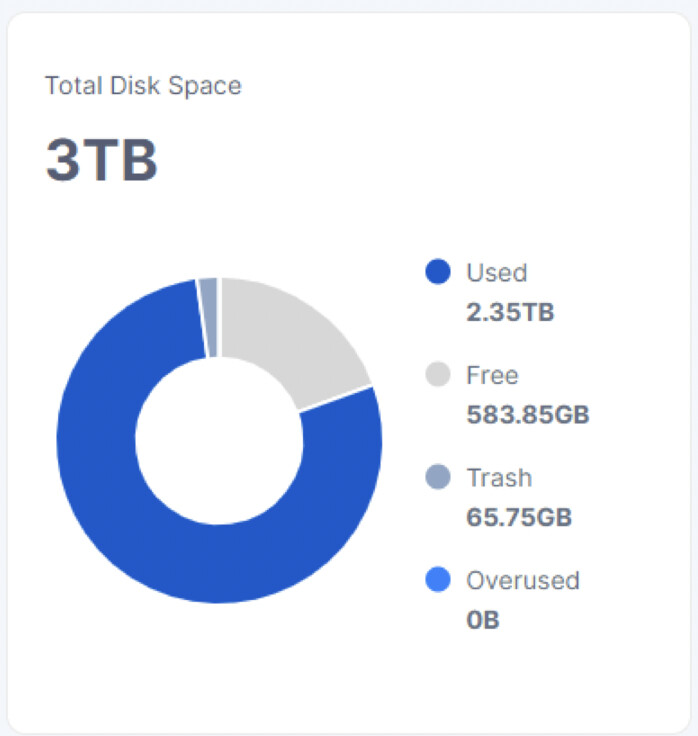
The dispalyed used storage value on the dashboard is correct or is wrong with the FW off?
Sorry but this i dont know.
As far as I’m aware it just doublechecks that the space used by the node is accounted for correctly in the node databases. This is simply a local correction that takes place in case some process didn’t update the total correctly. It doesn’t tell your node which files should be deleted (that’s what garbage collection is for), nor does it send that info to the satellite or compare it to satellite values. Unless your node is full, which is a signal that is sent to satellites so they stop selecting your node for uploads. This is why it’s important to keep an eye on your node and make sure the storage used value isn’t so far out of whack that your HDD fills up before this signal is sent to the satellite. You’d run into a lot of not so pretty issues should that happen.
I have a 4TB 2.5 inch disk (Shucked) that has 2.1 TB used. i have dissabled file walker and the disk usage is allmost constant 100% - the dashboard wont load (loades forever) and even if i stop my node it keeps at 100%. Its runnning in windows. Is there some way i can see what program is using this disk?
it cant catch up with load. Does you node stopes imidietly after you make stop request or it also running for some time like 10 min more before service realy stops?
I will suggest you move databases to c drive. in first step.
also check disks for errors.
Also for some reasons i think they can be smr disks, as 4tb small disks?
2 Likes
i have a node that is very slow at loading the dashboard, because bandwidth.db is beyond 5GB.
could be you have a similar issue…
but i think @Vadim is right… most 2.5" disk are SMR today.
so that sure isn’t helping.
Hey Vadim - no the node does not shut down right after - takes 5-7 min… I do think this is an SMR disk.
Corect - did you move DB to C drive? and did that help?
nah i just ignored it, my system is pretty overpowered, i just let it deal with it.
tho the fix for it is to delete the database and start over as suggested in this guide.
ofc that shouldn’t be the first option, but i tried pruning the database and such and nothing seems to fix it…
up to 7.7GB now on a file that should be … checked another node and its bandwidth.db is 70MB
Wow that is huge -
Its weird mine is only 12mb
It makes the whole server super slow that this one drives is doing 100% - i can hardly access the drive. And i dissabled FW on this one - so i dont know hat is causing it.
I always moove hdd to C, io is very vible to node, and then web less lagging also.
Okay thanks for the tip - i will think about it ![]()
If your db is not corrupt this is very bad advise. You can just vacuum the db to shrink it. Make sure you stop the node before doing that though. If you want to know how, just Google how to vacuum SQLite db’s.
2 Likes
SMR is causing it. The disk is frantically trying to rewrite whole shingled regions and never gets any downtime to free up continuous ranges on the disk. This is why SMR is so bad for 24/7 use cases. Especially with already slower 2.5" drives. Moving databases will move a lot of small writes away from that HDD. It’s the only thing that could help apart from starting a second node on another disk to spread the load.
2 Likes
tried that multiple times over time… nothing seems to fix it…
and it being a bad idea is the only reason i haven’t done so already…
its not really leaving me many options now… also since its still growing at a fairly rapid pace i do wonder if even deleting the db would fix it…
but it will certainly be interesting to see lol
we talked about it here
Looks like my memory failed me. You could check the db’s, see how many records are in the tables. You shouldn’t have old records in the none rolled up table. I’m not at my computer right now so don’t know the name of the table, bit it’s obvious when you see them. Don’t mess with the db’s while the node is running though.
2 Likes
I understand the point - but currently i have 3 nodes all getting data (not full) on this single machine - so the load is spread out ![]()
As mentioned, if a 2.5" drive is > 2TB then it is definitely SMR. There are some things you can try.
- move the DB to a SSD
- try limiting your space to a bit less than current usage so you don’t get as much ingress
- try limiting your concurrent connections to a small number (<9 from what I recall of other folks)
- if it eventually ‘recovers’ you could try increasing the disk allocation again.
what file system is it? if it’s something like btrfs that does copy on write that could be extra bad.