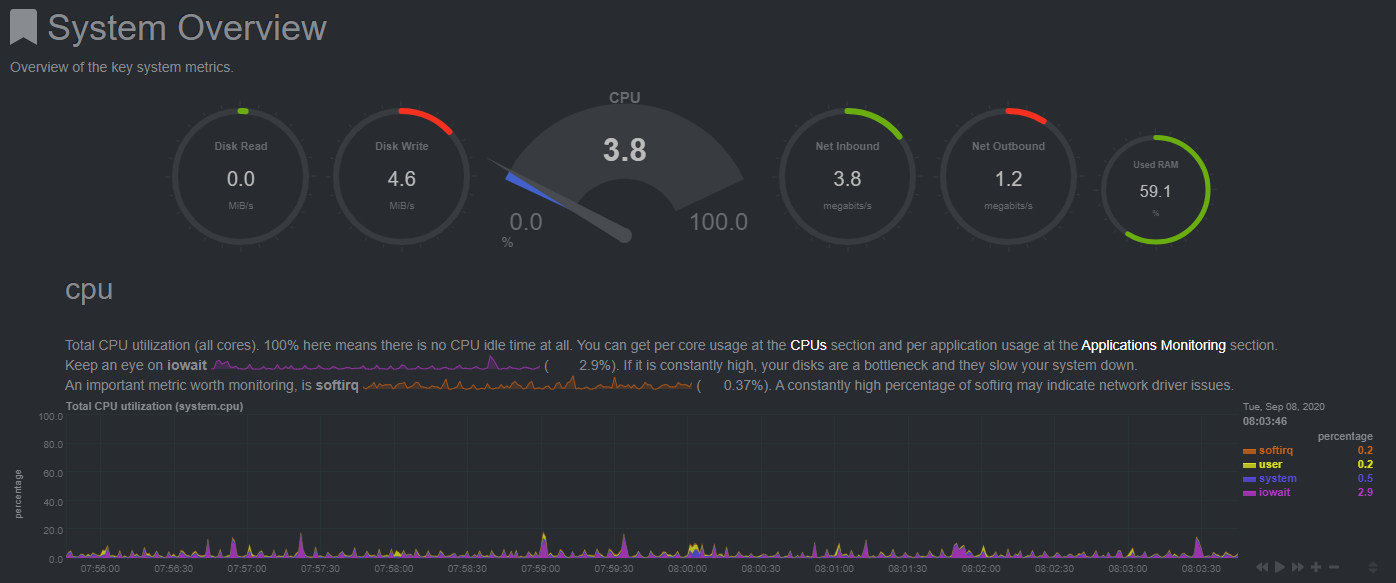
It’s all IO wait, which means the CPU is not the bottleneck, but the HDD is. What model is it? Could it be an SMR drive? The high IO wait moments likely coincide with either used space calculation or garbage collection.
I don’t think the USB3 is your problem, but yeah most of those larger 2.5" drives are SMR. Other SNOs have had some success by running another node on another HDD and effectively spreading the load. Other than something like that, there is likely not much you can do.
One other question, what file system are you using?
What do you mean by running another node on another HDD? I have a 2nd 2.5 inch 5TB which I was going to run as a second node with a second docker instance. I am using ext4 - is there a better one? I could test it with my new node
That’s basically what I meant. Those nodes would split incoming data so each HDD only has to deal with half the load. Ext4 is fine, was just making sure you aren’t using ntfs on linux. People have seen issues with that as well.
Yes, I originally started with NTFS - really bad idea!
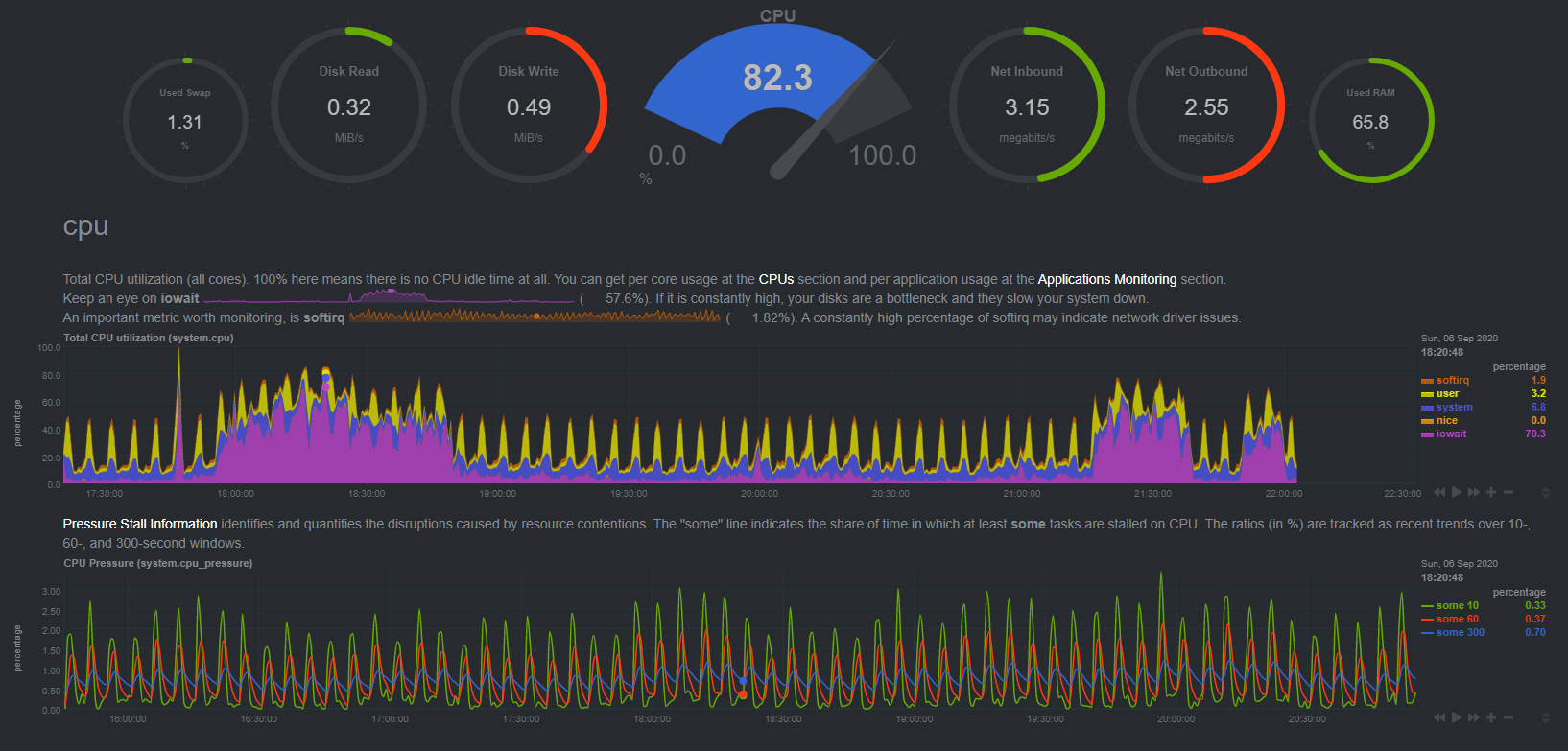
This happens often. CPU at 100% and it always starts at 00:00… It will normally last a few days. Anything I should check? Still related to the HDD do you think?
Since it’s still all IO wait, yes, it’s HDD related. There’s not much to check, you could check the HDD model and look up whether it’s SMR, but I’m pretty certain it will be. Those HDD’s simply aren’t optimized for 24/7 write operations.
ok, i just read another forum post. Do you think starting a new node under the same IP will help reduce the I/O load? I should be able to get it up and running today
I’ve never seen 2.5" CMR disks bigger than 2TB, so I’d be pretty sure your disk is SMR. Even most 1TB disks are SMR these days, so manufacturers can cut prices down.
Personnally, I’m using the --storage2.max-concurrent-requests option to go easy on such drives. Not ideal for the network, but that’s the only way I found to make a single SMR drive cope with the load. Without this option, my disk stalled so much it got my node suspended because it was unresponsive with all its databases locked.
This option should be used in last resort I guess, so if you can go with 2 disks maybe it’ll be alright even though the new node won’t be very active at first.
But not all smr drives are created equal, so… worth a try
@Pac
i use max concurrent for a long time, and my main issue with that was it would create its own errors simply caused by having a max set…
but ofc a little software problems rather than wearing a hdd out fast… thats an easy choice…
@heartbeat
i would also recommend recommend the dual node or triple node approach… after x3 the iops performance gains start to diminish so much it’s not worth it… i mean adding 1 node is +100% iops performance and adding a 3rd is 2 nodes + 1 and thus 50% iops performance increase…
so to extend hdd life i would recommend anyone running storj to run 2 or 3 hdd / nodes or similar setups.
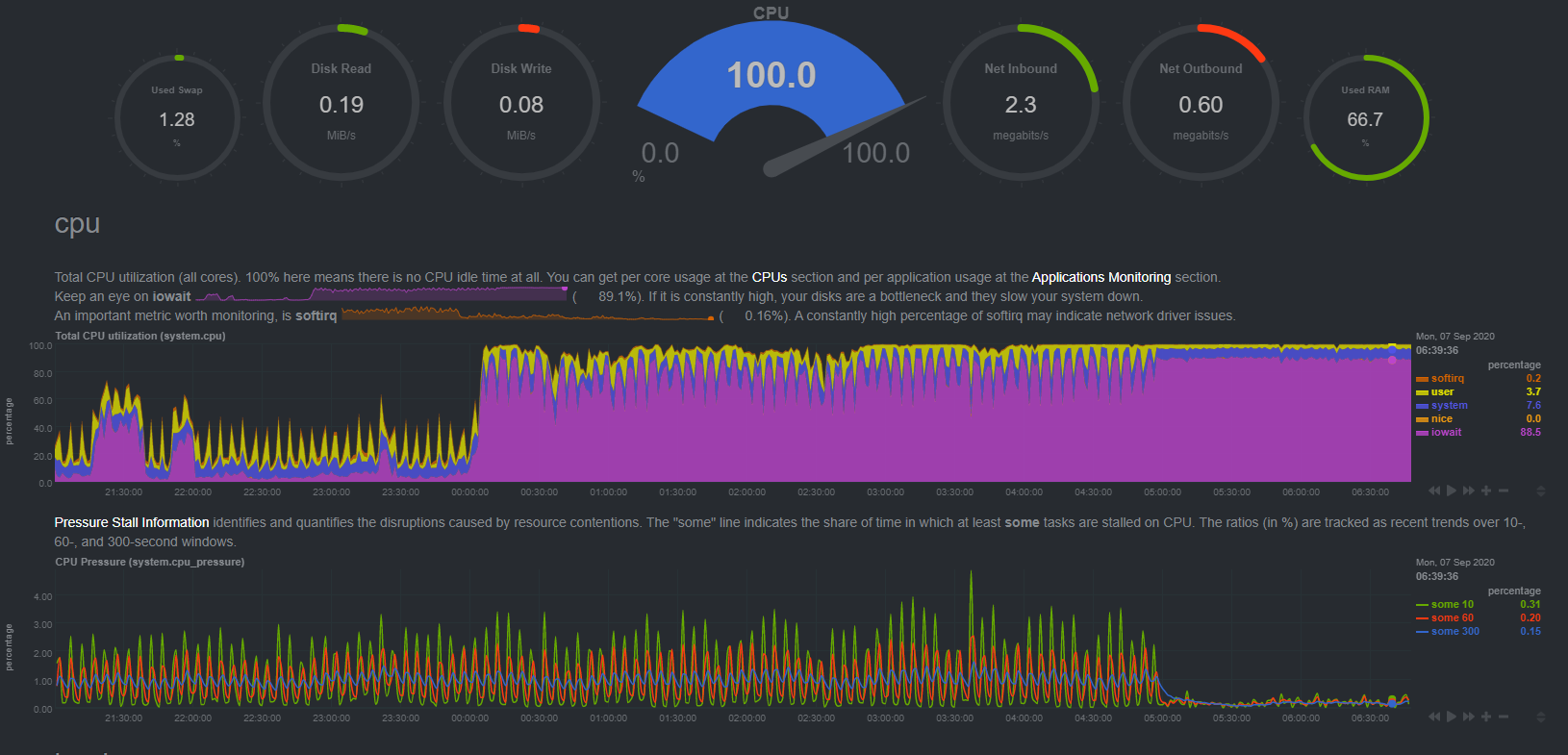
by doing almost everything i can to remove iowait my storagenode errors are basically non existing…
this mornings log successrate.
i know my uploads are a bit slacking, but i hope to get that removed when i install my new ssd which works as a write cache… the current two SSD’s i got can’t keep up… which is weird because we are uploading… but apparently that causes a ton of writes… and ofc i’m running everything in sync writes for various reasons.
the iowait spikes is a bad harddrive that i still haven’t been able to fix… keeps turning itself off, but it’s not to bad, when it doesn’t get to much traffic…
oh yeah you should check that your APM on the HDD firmware is turned off, has helped my latency… the drive is still broken… but works better and even all my other hdd’s seemed to reduce latency / iowait in general.
Sure, but personally what I really dislike about this option is that it doesn’t feel like the best approach to me: Ideally I think it should be dynamic, and the node software should adjust this in real time to reject uploads (ingress) when the disk can’t keep up (for instance when the average write speed of pieces falls below a threshold maybe?), but should then go back to accepting more pieces in parallel when the disk is “calm” again.
Because right now, it statically caps the number of files to be written in parallel even though there are moments where SMR disks can cope with way more than that.
I think I have set it up right but Storj is showing offline? Happy to try another way if there is a better way. I might even stick it on the same box if you think that is better / easier
This setup only works if you’re running the second node in a different machine. Hence why it says node machine2.
If you’re running them on the same machine you will need to do this.
node2: outside world => 28968 => router => 28968 => node machine [ => 28967 => docker container]
Meaning the docker run command will have -p 28968:28967 and the router forwards public port 28968 to 28968 on the node machine.


 thats an easy choice…
thats an easy choice…